Evaluando agentes de computer-use, paso a paso
Un recorrido por la evaluación humana de agentes de computer-use y de GUI en Potato: juzgar cada acción, verificar el anclaje del clic sobre la captura de pantalla y revisar las llamadas a herramientas una a una.
Un agente de computer-use lee una captura de pantalla, decide una acción y hace clic. Evaluar uno significa verificar cada paso: ¿fue correcta la acción y el clic realmente cayó sobre el elemento que nombró? — no solo si la tarea acabó teniendo éxito. El éxito de la tarea oculta el clic que dio en el botón equivocado pero avanzó igualmente, y la acción que fue correcta por suerte. Potato revisa estas ejecuciones con una superficie de trayectoria de GUI diseñada para ello y una revisión de llamadas a herramientas, ambas configuradas en YAML.
Un agente de computer-use — también llamado agente de GUI o de SO — ve la pantalla como píxeles o como un DOM y actúa a través de los mismos controles que tiene una persona. Benchmarks como OSWorld, ScreenSpot y AndroidWorld puntúan la finalización de la tarea automáticamente. La puntuación automática es barata y vale la pena ejecutarla, pero no puede decirte por qué falló una ejecución, ni atrapar el acierto por suerte. Ese es el hueco que llena la revisión humana paso a paso.
 Juzga la acción y si el clic cayó sobre el elemento que nombró
Juzga la acción y si el clic cayó sobre el elemento que nombró
¿Qué juzgas realmente en una trayectoria de GUI?
Cada paso empareja una captura de pantalla (lo que vio el agente) con una acción (lo que hizo). Juzgas la acción y, cuando el paso lleva coordenadas de clic, verificas el marcador de anclaje que Potato dibuja sobre la captura de pantalla:
- Corrección de la acción — correcta, elemento equivocado, acción equivocada o alucinada.
- Anclaje del clic — ¿cayeron las coordenadas sobre el elemento que nombró la acción?
- Resultado — ¿terminó la ejecución la tarea, y en qué paso se torció por primera vez?
 Revisa cada paso: corrección de la acción más anclaje del clic sobre la captura de pantalla
Revisa cada paso: corrección de la acción más anclaje del clic sobre la captura de pantalla
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot
action_key: action
coord_space: normalized
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Cada paso aporta screenshot, action y, opcionalmente, x/y (o un click: {x, y} anidado). El marcador de anclaje es la parte que las métricas automatizadas pasan por alto con más frecuencia: un modelo puede emitir la etiqueta de acción correcta mientras hace clic diez píxeles fuera del objetivo, y un aprobado/suspenso sobre la pantalla final nunca lo sacará a la luz.
¿Por qué importa más el primer paso erróneo que el resultado final?
Porque ese paso es lo que arreglarías o entrenarías. Una ejecución que falla en el paso 9 porque el paso 3 leyó mal un diálogo es en realidad un problema del paso 3, y etiquetarlo en el paso 9 enseña la lección equivocada. Atrapar la primera divergencia es la misma idea que hay detrás de los modelos de recompensa por proceso: una señal en cada paso localiza el error en lugar de colapsar toda la trayectoria en un solo número.
¿Cómo reviso las llamadas a herramientas de un agente?
Los agentes de GUI también llaman a herramientas y funciones, y esas fallan a su manera: intención correcta, herramienta equivocada; herramienta correcta, argumentos mal formados; llamada correcta, orden equivocado. El esquema tool_call_review extrae cada llamada de la traza y le da una tarjeta con el nombre de la herramienta y los argumentos formateados, así que las juzgas una a una (reflejando BFCL v4 / MCPMark).
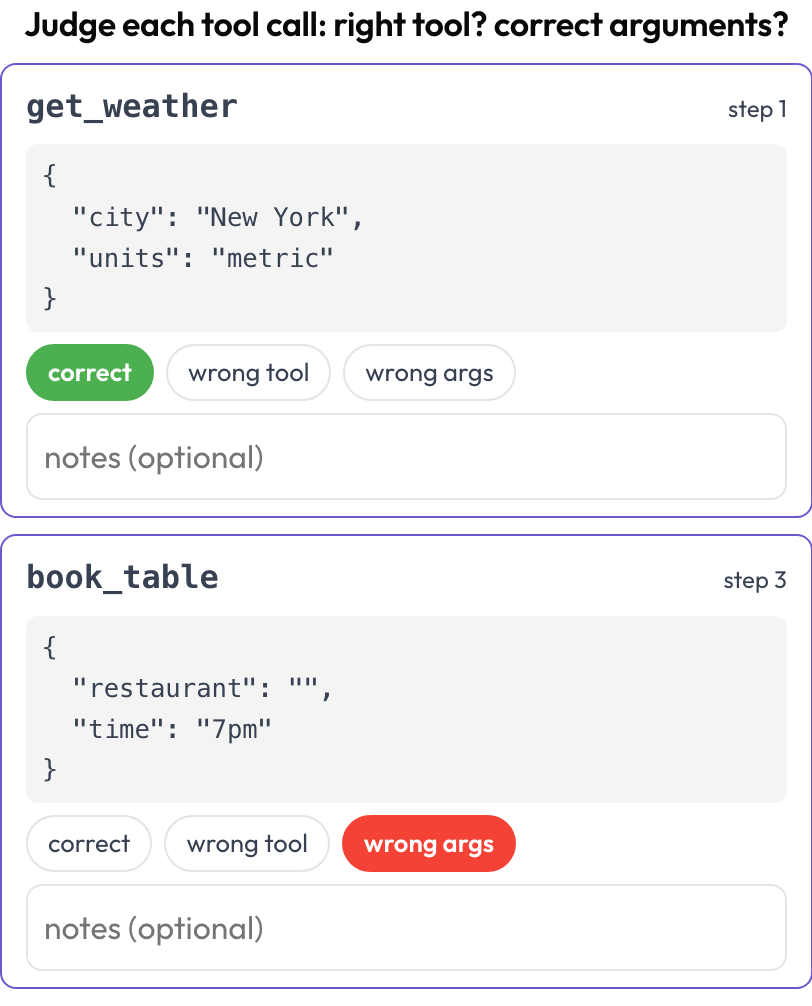 Juzga cada llamada a herramienta: ¿herramienta correcta, argumentos correctos, orden correcto?
Juzga cada llamada a herramienta: ¿herramienta correcta, argumentos correctos, orden correcto?
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order]Las llamadas a herramientas se extraen en el momento de renderizar a partir del campo tool_calls, tool_call o action de cada paso, así que una trayectoria que mezcla clics de interfaz y llamadas a API puede revisarse en ambos ejes dentro de una sola tarea.
¿Cómo configuro esto?
Cada superficie incluye un ejemplo ejecutable en examples/agent-traces/. Apunta Potato a uno para ver el esquema con datos de muestra:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/gui-trajectory/config.yaml -p 8000Tus propios datos se incorporan como una lista de pasos, cada uno con una URL de captura de pantalla o un data-URI y una cadena de acción. Para agentes web más amplios que trabajan desde páginas renderizadas en lugar de capturas de pantalla en bruto, consulta Evaluación de agentes web.
Lecturas adicionales
- Evaluación de agentes multimodales — la referencia completa del esquema para agentes de GUI, voz, vídeo y documentos
- Evaluando agentes de computer-use y multimodales — la guía, con una tabla de selección de esquemas
- Evaluando agentes de voz y vídeo — la otra mitad de las superficies multimodales
- Potato 2.6.2: una suite completa de evaluación de agentes de código abierto — toda la línea 2.6.x