Depurando fallos multiagente: un recorrido paso a paso
Cómo encontrar por qué falló un sistema LLM multiagente usando Potato: el grafo de interacción, la atribución de fallos, la revisión de traspasos, los cuadros de mando por agente, la línea de tiempo de contención de herramientas y el etiquetado de comportamiento emergente.
Cuando un equipo de agentes falla, lo difícil no es darse cuenta del fallo, sino encontrar qué agente lo causó, en qué paso, y si el problema real fue un mal traspaso entre dos agentes que estaban bien por separado. Este recorrido repasa las seis superficies de Potato creadas para ello, en el orden en que realmente las usarías sobre una ejecución rota. Todo lo de aquí se configura en YAML y se ejecuta en tu propio servidor; la referencia completa del esquema está en Evaluación de equipos multiagente.
Un sistema multiagente son varios agentes LLM con roles distintos — un planificador, un programador, un revisor — que se pasan mensajes y se traspasan el control. La investigación sobre por qué se rompen estos sistemas, la taxonomía MAST (Why Do Multi-Agent LLM Systems Fail?), encontró que la mayoría de los fallos son entre agentes: una restricción que se pierde en un traspaso, un equipo que nunca verifica su propio trabajo, agentes que hablan sin entenderse. Una transcripción de chat plana oculta precisamente eso, porque lo que salió mal vive en el espacio entre dos mensajes, no dentro de ninguno de ellos.
 El fallo está entre agentes, en un traspaso, no dentro de una transcripción
El fallo está entre agentes, en un traspaso, no dentro de una transcripción
¿Cómo veo la estructura de una ejecución multiagente?
Empieza por la forma de la ejecución, no por el texto. El esquema agent_interaction_graph representa toda la ejecución como un grafo dirigido: los nodos son agentes, las aristas son los traspasos entre ellos, y las aristas más gruesas indican más tráfico. Haces clic en un nodo para marcarlo en el camino crítico y haces clic en una arista para alternarla de normal a crítica y a problemática.
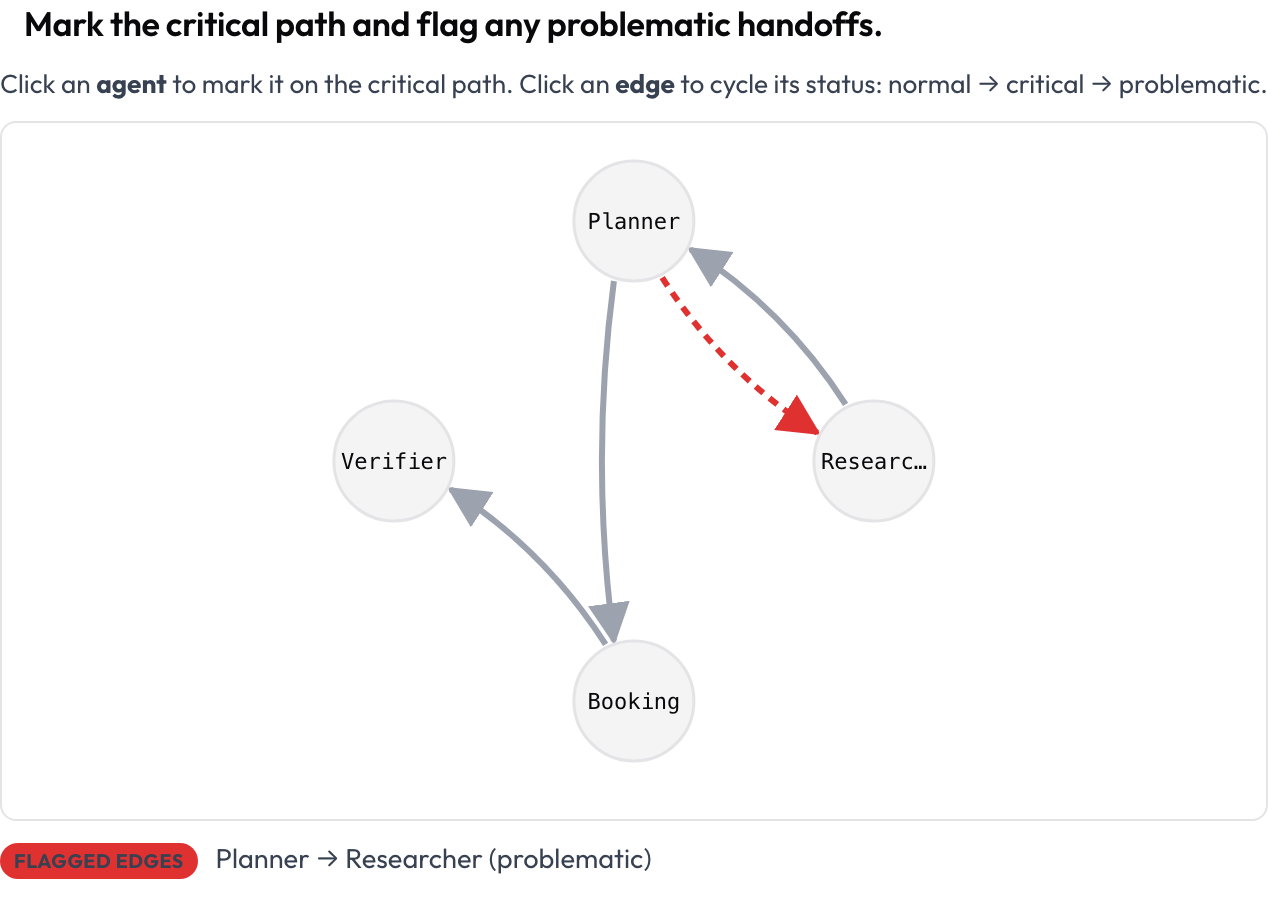 Marca el camino crítico y señala los traspasos problemáticos
Marca el camino crítico y señala los traspasos problemáticos
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentEl grafo se dispone automáticamente a partir de la traza, así que no dibujas nada. Cada nodo y arista es enfocable con el teclado y un resumen de texto enumera los nodos críticos y las aristas señaladas, de modo que el significado nunca depende solo del color. Esta vista es la forma más rápida de responder "qué habló con qué, y dónde se torció el camino".
¿Cómo atribuyo un fallo multiagente a un solo agente?
Una vez que puedes ver la ejecución, acota el fallo. El esquema failure_attribution pide la tripleta de la literatura de atribución de fallos (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, el conjunto de datos Who&When): el agente responsable, el paso decisivo y la razón. El desplegable de agentes y el selector de pasos se rellenan a partir de los propios turnos de la traza, así que solo puedes atribuir el fallo a un agente y un paso que realmente ocurrieron.
 Atribuye el fallo al agente responsable, al paso decisivo y al porqué
Atribuye el fallo al agente responsable, al paso decisivo y al porqué
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agentEmparejar la atribución con un radio de éxito/fallo significa que la tripleta solo se recoge en las ejecuciones que fallaron, lo que mantiene el tiempo del anotador en los casos que aportan señal.
¿Y los traspasos en sí?
La atribución nombra un paso decisivo. La revisión de traspasos examina cada transferencia de control. Allí donde el agente que actúa cambia entre turnos consecutivos, Potato emite una tarjeta de traspaso A → B, y señalas qué salió mal en el paso — pérdida de información, una restricción descartada, distorsión, deriva del objetivo — y valoras la calidad. Los modos de fallo provienen de la categoría entre agentes de MAST y del fenómeno de "eco" (Zhang et al., 2025).
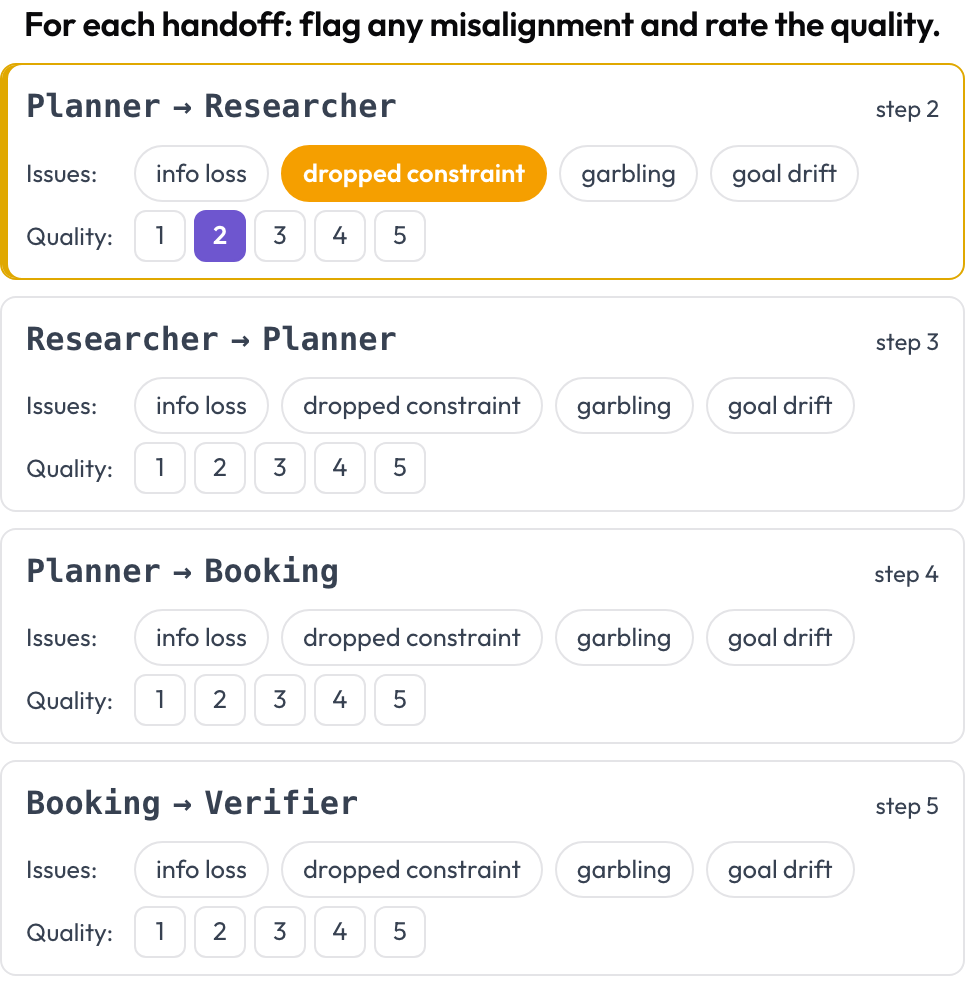 Señala la desalineación entre agentes en cada traspaso y valora su calidad
Señala la desalineación entre agentes en cada traspaso y valora su calidad
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Los traspasos se derivan en el momento de renderizar, así que no hay configuración manual. Aquí es donde suelen resolverse los casos de "cada agente parecía estar bien, el equipo aun así falló": la restricción estaba viva en el agente A y había desaparecido para cuando llegó al agente B.
¿Cómo puntúo a los agentes y al equipo?
Un fallo te dice qué se rompió una vez. Un cuadro de mando te dice si un diseño es bueno a lo largo de muchas ejecuciones. El esquema agent_scorecard puntúa dos niveles a la vez (MultiAgentBench, Zhou et al., ACL 2025): cada agente en fidelidad al rol, contribución y coordinación, y el equipo en sus propias dimensiones compartidas, con hitos opcionales. Las filas de agentes provienen de la traza, así que la matriz coincide con quién participó realmente.
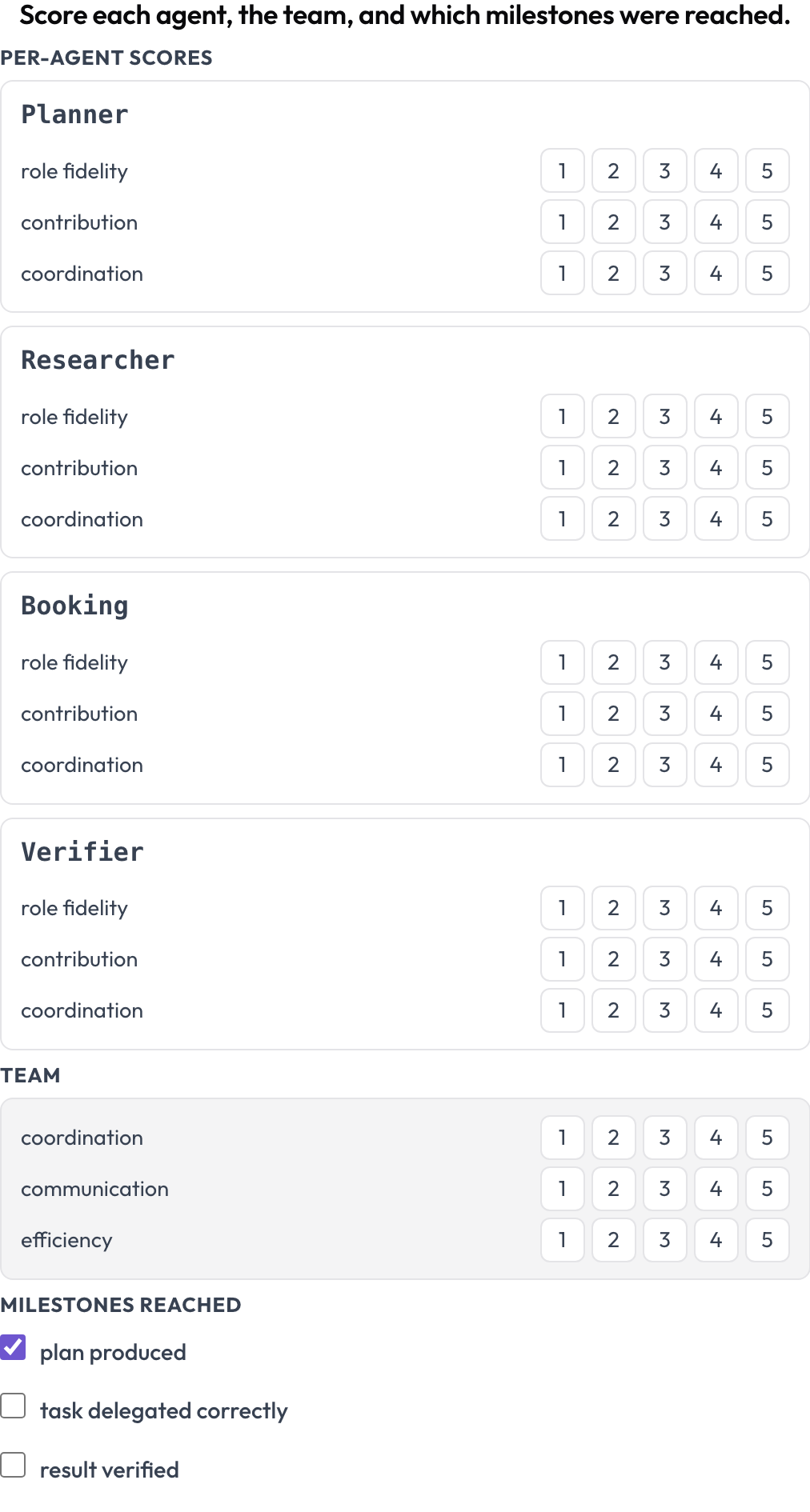 Puntúa a cada agente en fidelidad al rol, contribución y coordinación, además del equipo
Puntúa a cada agente en fidelidad al rol, contribución y coordinación, además del equipo
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]Un agente fuerte atrapado dentro de un equipo mal coordinado aparece aquí como una fila de agente alta junto a dimensiones de equipo bajas, que es el patrón que buscas cuando comparas orquestación secuencial frente a jerárquica frente a chat de grupo en las mismas tareas.
¿Y la concurrencia y los fallos colectivos?
Dos superficies más capturan fallos que una lectura turno a turno no puede. La línea de tiempo tool_contention pone a cada agente en su propio carril y resalta las regiones donde dos llamadas tocan el mismo recurso en tiempos solapados, que clasificas como interbloqueo (deadlock), espera circular, condición de carrera o benigna (DPBench, 2026).
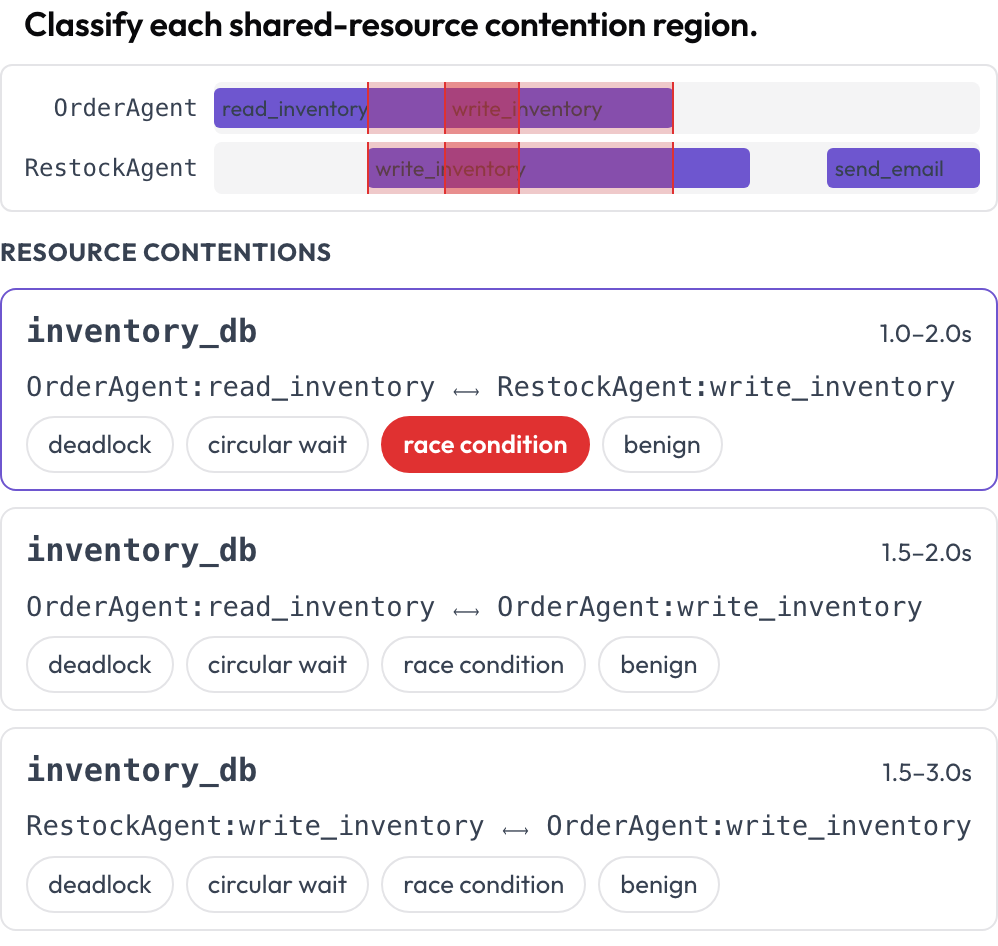 Detecta interbloqueos y condiciones de carrera en una línea de tiempo de llamadas a herramientas por agente
Detecta interbloqueos y condiciones de carrera en una línea de tiempo de llamadas a herramientas por agente
Y emergent_behavior maneja los fallos que son colectivos en lugar de localizados en un solo paso — colusión, pensamiento de grupo, errores en cascada, deriva de rol. Un comportamiento emergente no es un tramo contiguo; es un conjunto de turnos participantes, posiblemente de distintos agentes, así que marcas los turnos que toman parte y añades una nota.
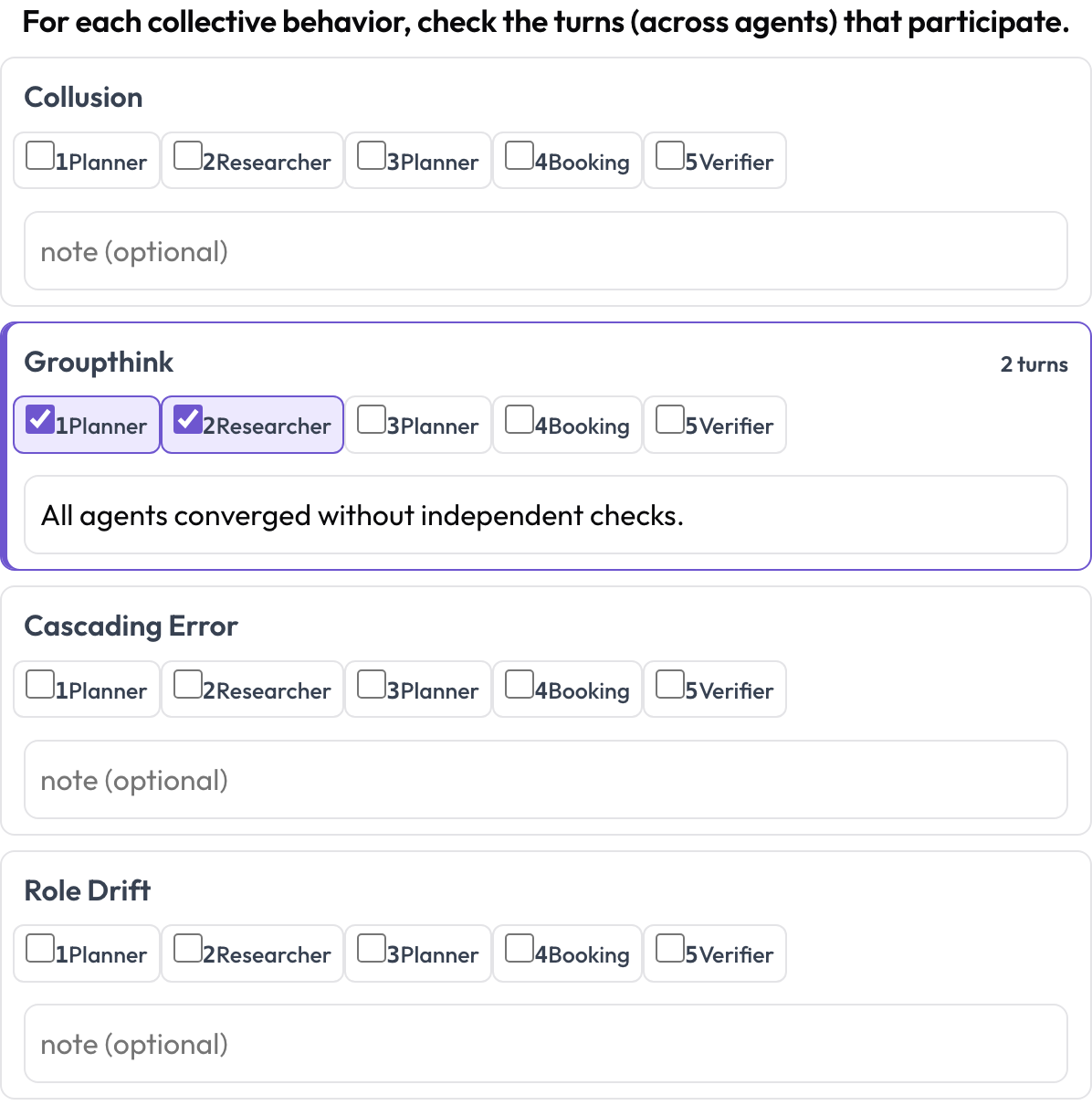 Etiqueta colusión, pensamiento de grupo y errores en cascada entre agentes y turnos
Etiqueta colusión, pensamiento de grupo y errores en cascada entre agentes y turnos
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: truePoniéndolo en orden
En una ejecución rota real la secuencia suele ser: leer el grafo de interacción para ver la forma, usar la atribución de fallos para nombrar el paso decisivo, abrir la revisión de traspasos si el paso decisivo fue una transferencia, y recurrir a la línea de tiempo de contención o al etiquetado de comportamiento emergente cuando el fallo tiene que ver con el tiempo o con el grupo más que con un solo agente. Puntúa con el cuadro de mando una vez que estés comparando diseños en lugar de depurar una sola ejecución. Mide el acuerdo sobre la atribución igual que harías con cualquier etiqueta subjetiva; consulta Acuerdo entre anotadores.
Lecturas adicionales
- Evaluación de equipos multiagente — la referencia completa del esquema con YAML para cada superficie
- Cómo evaluar sistemas multiagente — la guía de decisión para qué método usar y cuándo
- Potato 2.6.2: una suite completa de evaluación de agentes de código abierto — todo lo que llegó a lo largo de la línea 2.6.x
- Anotando trayectorias de agentes — taxonomías de errores por paso, incluido el etiquetado MAST a granularidad de paso