Potato 2.6.2: Eine vollständige Open-Source-Suite zur Agentenbewertung
Die 2.6.x-Reihe macht Potato zu einer vollständigen, kostenlosen Plattform zur Agentenbewertung: Trace-Ingestion aus OpenTelemetry, LangGraph, CrewAI und AutoGen, Annotation von Multi-Agent-Teams mit einem anklickbaren Interaktionsgraphen, multimodale Agentenschemata für GUI, Sprache und Video sowie eine Modellarena, CI-Gating und Kuratierung.
Potato 2.6 brachte die erste Welle der Agentenbewertung: LLM-as-Judge-Kalibrierung, Trajektorienbearbeitung für Trainingsdaten und die dreigeteilte eval_trace-Anzeige. Die 2.6.x-Punktreleases seither füllen den Rest. Mit 2.6.2 ist Potato eine vollständige Plattform zur Agentenbewertung: Sie können Traces aus Ihren eigenen Agenten erfassen, einzelne Agenten, Multi-Agent-Teams und multimodale Agenten annotieren, sie mit LLMs bewerten, denen Sie vertrauen können, Modelle in einer Arena einordnen und Releases in der CI gaten. Alles wird in YAML konfiguriert und bleibt auf Ihrem eigenen Server.
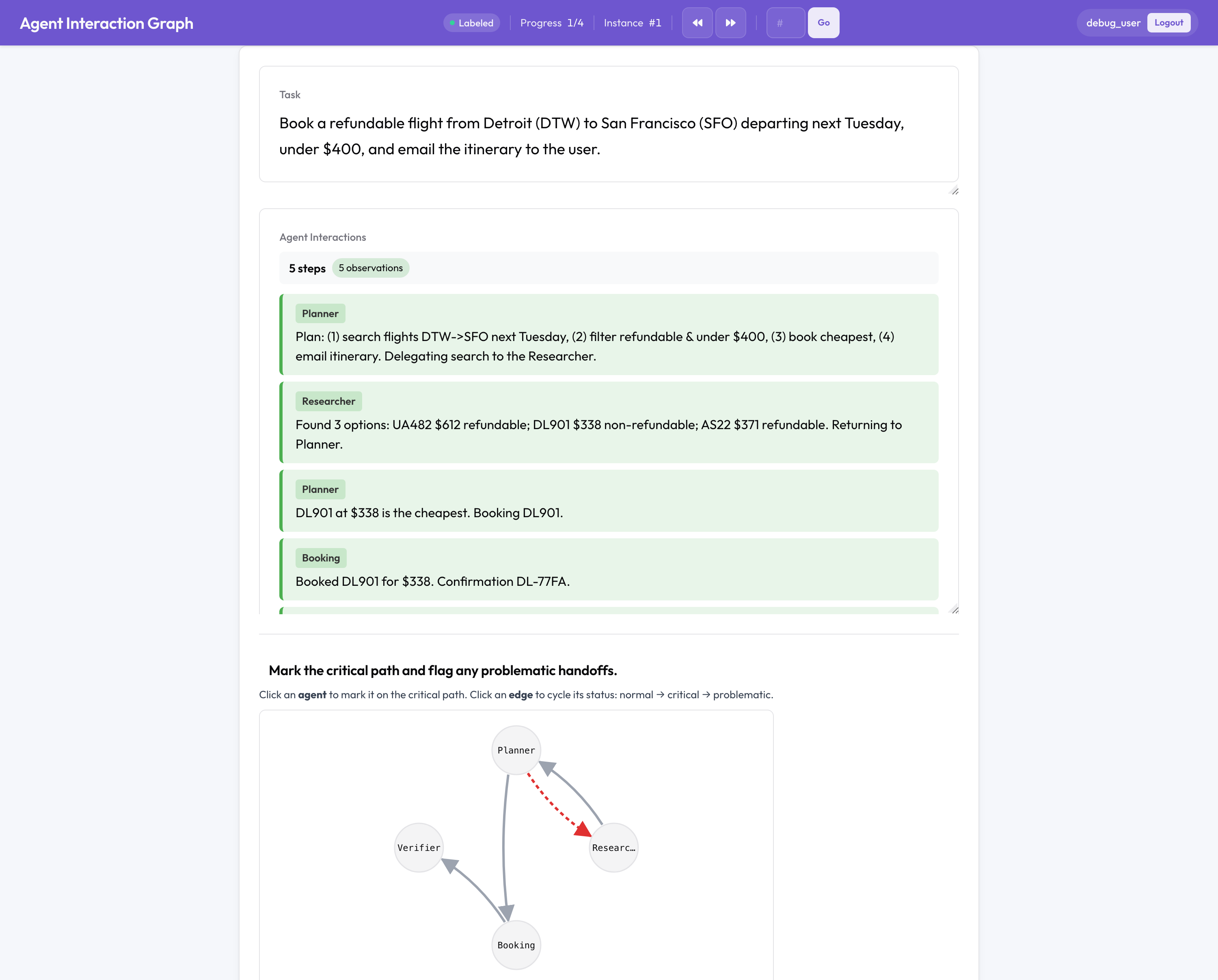 Multi-Agent-Bewertung in Potato
Multi-Agent-Bewertung in Potato
Die meisten dieser Funktionen erhält man heute nur gegen Bezahlung bei einer gehosteten Plattform. Potato bietet sie kostenlos und selbst gehostet. Hier ist, was über die 2.6.x-Reihe ausgeliefert wurde.
 Die 2.6.x-Suite zur Agentenbewertung, von Anfang bis Ende
Die 2.6.x-Suite zur Agentenbewertung, von Anfang bis Ende
Traces hereinbekommen: ein Capture-SDK und offene Standards
Bewertung beginnt mit echten Läufen. Das neue potato_trace-SDK instrumentiert jeden Agenten: Versehen Sie eine Funktion mit dem Dekorator @traceable (synchron oder asynchron), und verschachtelte Aufrufe werden erfasst und an den Ingestion-Endpunkt von Potato gesendet, mit optionalem OpenTelemetry-Export. Potato nimmt außerdem OpenTelemetry / OpenInference-Spans sowie die Laufformate von LangGraph, CrewAI und AutoGen entgegen, sodass Traces aus dem Framework, das Sie bereits verwenden, ohne Glue-Code in der Annotationswarteschlange landen. Neue Traces können über einen Webhook, einen Poller oder ein überwachtes Verzeichnis eintreffen und werden Annotatoren zugewiesen, sobald sie ankommen.
Referenz: Tracing-SDK, Automatisierungsregeln.
Das ganze Team sehen: Multi-Agent-Bewertung
Das ist der Teil ohne Open-Source-Äquivalent. Ein Multi-Agent-Lauf scheitert anders als ein einzelner Agent, zwischen Agenten, bei einer Übergabe, in der Art, wie das Team organisiert war. Deshalb annotiert Potato die Teamstruktur statt eines flachen Transkripts:
- Ein anklickbarer Interaktionsgraph aus Agenten und Übergaben, in dem Sie den kritischen Pfad markieren und problematische Kanten kennzeichnen.
- Fehlerzuordnung: Wählen Sie den verantwortlichen Agenten, den entscheidenden Schritt und den Grund, das (Agent, Schritt, Grund)-Tripel aus der Who&When-Zuordnungsarbeit.
- Übergabeprüfung: Jeder Kontrollwechsel wird zu einer Karte, um Fehlausrichtungen zwischen Agenten zu kennzeichnen und die Qualität zu bewerten.
- Bewertungsbögen pro Agent und pro Team: Rollentreue, Beitrag und Koordination pro Agent, plus gemeinsame Teamdimensionen und Meilensteine.
- Eine Tool-Contention-Zeitleiste, die Deadlocks und Races sichtbar macht, bei denen Agenten gleichzeitig auf dieselbe Ressource zugreifen.
- Tagging von emergentem Verhalten für Kollusion, Groupthink und kaskadierende Fehler, die sich über mehrere Agenten und Runden erstrecken.
 Fehlerzuordnung: welcher Agent, welcher Schritt und warum
Fehlerzuordnung: welcher Agent, welcher Schritt und warum
Der vollständige Satz mit YAML für jeden Bereich findet sich in Multi-Agent-Teambewertung, und der Tiefenartikel Multi-Agent-Fehler debuggen führt jede Oberfläche von Anfang bis Ende durch. Der Leitfaden So bewerten Sie Multi-Agent-Systeme erklärt, wann welche Methode einzusetzen ist.
Jenseits von Text: multimodale Agentenbewertung
Agenten steuern inzwischen GUIs, schauen Videos und führen gesprochene Unterhaltungen, und jede dieser Aufgaben braucht eine Prüfoberfläche, die ein Text-Widget nicht bieten kann:
- GUI- / Computer-Use-Trajektorien: Screenshot und Aktion pro Schritt, ein Aktionsurteil und ein Klick-Grounding-Marker, der zeigt, ob der Klick auf dem richtigen Element gelandet ist.
- Vollduplex-Sprachzeitleisten: eine zweispurige Nutzer-/Agenten-Zeitleiste mit Barge-in-Erkennung und Bewertung des Sprecherwechsels.
- Zeitliche Verankerung von Video: Markieren Sie Gold-Ereignisintervalle mit einem live berechneten IoU gegen das vom Modell vorhergesagte Intervall.
- Fehler-Tagging von Sprachtranskripten, verschränktes multimodales Reasoning mit Markierungen für visuelle Halluzinationen und Dokument-Tabellengitter-Struktur.
 Computer-Use-Prüfung: Aktionskorrektheit plus Klick-Grounding
Computer-Use-Prüfung: Aktionskorrektheit plus Klick-Grounding
Zwei Tiefenartikel führen diese durch: Computer-Use-Agenten bewerten für GUI- und OS-Agenten und Sprach- und Video-Agenten bewerten für gesprochene, Video- und Dokumentenagenten. Die Referenz ist Multimodale Agentenbewertung, und der Leitfaden ist Computer-Use- und multimodale Agenten bewerten.
Juroren, denen Sie vertrauen können, und eine Arena
Ein LLM zur Bewertung von Ausgaben einzusetzen, ist Routine; bei der 2.6.x-Arbeit geht es darum, zu wissen, wie weit man ihm vertrauen kann. Jurorenkalibrierung führt einen blinden menschlichen Durchlauf gegen die Modelllabels durch und berichtet Genauigkeit, Kappa und den Expected Calibration Error. Jurorenausrichtung stimmt einen einzelnen Juror auf Ihre Gold-Labels ab. Und programmatische Evaluatoren bewerten Trajektorien und Text automatisch (Trajektorienabgleich, Korrektheit der Tool-Nutzung, referenzfreies LLM-as-Judge und Heuristiken), ohne dass ein Server läuft.
Für den direkten Vergleich schickt die Modellarena einen Prompt an mehrere Modelle, sammelt Präferenzen und baut eine Siegquoten-Rangliste über OpenAI, Anthropic, Gemini, Ollama und vLLM hinweg.
Bewertung wie Software behandeln
Die operativen Bausteine machen die Bewertung wiederholbar:
- Datasets und Experimente: versionierte Bewertungssätze, Splits und Experimentvergleiche nebeneinander mit Regressionsdeltas.
- CI-Bewertung: ein pytest-Plugin, das den Build fehlschlagen lässt, wenn eine Prompt- oder Modelländerung die Agentenqualität über einen Schwellenwert hinaus verschlechtert.
- Automatisierungsregeln: leiten eingehende Produktionstraces per Regel in Datasets, Evaluatoren oder die Annotationswarteschlange.
- Semantische Kuratierung: ein Embedding-Index für „finde Traces wie diesen Fehler“ und gespeicherte dynamische Slices.
Es bekommen
pip install --upgrade potato-annotationJede neue Oberfläche wird mit einem ausführbaren Beispiel unter examples/agent-traces/ ausgeliefert, darunter interaction-graph/, failure-attribution/, gui-trajectory/ und temporal-grounding/. Richten Sie Potato auf eines davon, um das Schema in Aktion zu sehen:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000Wenn Sie Werkzeuge abwägen, zeigen der Vergleich in Potato vs. LangSmith und Langfuse und der Leitfaden Open-Source-Annotationswerkzeuge im Vergleich, wo jedes hineinpasst. Fragen und Trace-Formate, die wir unterstützen sollten, sind im GitHub-Repository willkommen.