Multi-Agent-Fehler debuggen: Eine Schritt-für-Schritt-Anleitung
So finden Sie mit Potato heraus, warum ein Multi-Agent-LLM-System gescheitert ist: der Interaktionsgraph, die Fehlerzuordnung, die Übergabeprüfung, Bewertungsbögen pro Agent, die Tool-Contention-Zeitleiste und das Tagging von emergentem Verhalten.
Wenn ein Team aus Agenten scheitert, ist der schwierige Teil nicht, das Scheitern zu bemerken — sondern herauszufinden, welcher Agent es verursacht hat, bei welchem Schritt, und ob das eigentliche Problem eine schlechte Übergabe zwischen zwei Agenten war, die für sich genommen jeweils in Ordnung waren. Diese Anleitung geht die sechs dafür gebauten Potato-Oberflächen durch, in der Reihenfolge, in der Sie sie bei einem fehlgeschlagenen Lauf tatsächlich verwenden würden. Alles hier wird in YAML konfiguriert und läuft auf Ihrem eigenen Server; die vollständige Schemareferenz ist Multi-Agent-Teambewertung.
Ein Multi-Agent-System besteht aus mehreren LLM-Agenten mit unterschiedlichen Rollen — einem Planer, einem Coder, einem Reviewer —, die Nachrichten weitergeben und die Kontrolle übergeben. Die Forschung dazu, warum diese Systeme brechen, die MAST-Taxonomie (Why Do Multi-Agent LLM Systems Fail?), fand heraus, dass die meisten Fehler zwischen den Agenten liegen: eine bei einer Übergabe verlorene Vorgabe, ein Team, das seine eigene Arbeit nie überprüft, Agenten, die aneinander vorbeireden. Ein flaches Chat-Transkript verbirgt genau diese, weil das, was schiefging, im Raum zwischen zwei Nachrichten lebt, nicht in einer von beiden.
 Der Fehler liegt zwischen Agenten, bei einer Übergabe, nicht in einem einzigen Transkript
Der Fehler liegt zwischen Agenten, bei einer Übergabe, nicht in einem einzigen Transkript
Wie sehe ich die Struktur eines Multi-Agent-Laufs?
Beginnen Sie mit der Form des Laufs, nicht mit dem Text. Das Schema agent_interaction_graph stellt den gesamten Lauf als gerichteten Graphen dar: Knoten sind Agenten, Kanten sind die Übergaben zwischen ihnen, wobei dickere Kanten mehr Verkehr bedeuten. Sie klicken auf einen Knoten, um ihn auf dem kritischen Pfad zu markieren, und auf eine Kante, um sie von normal über kritisch zu problematisch durchzuschalten.
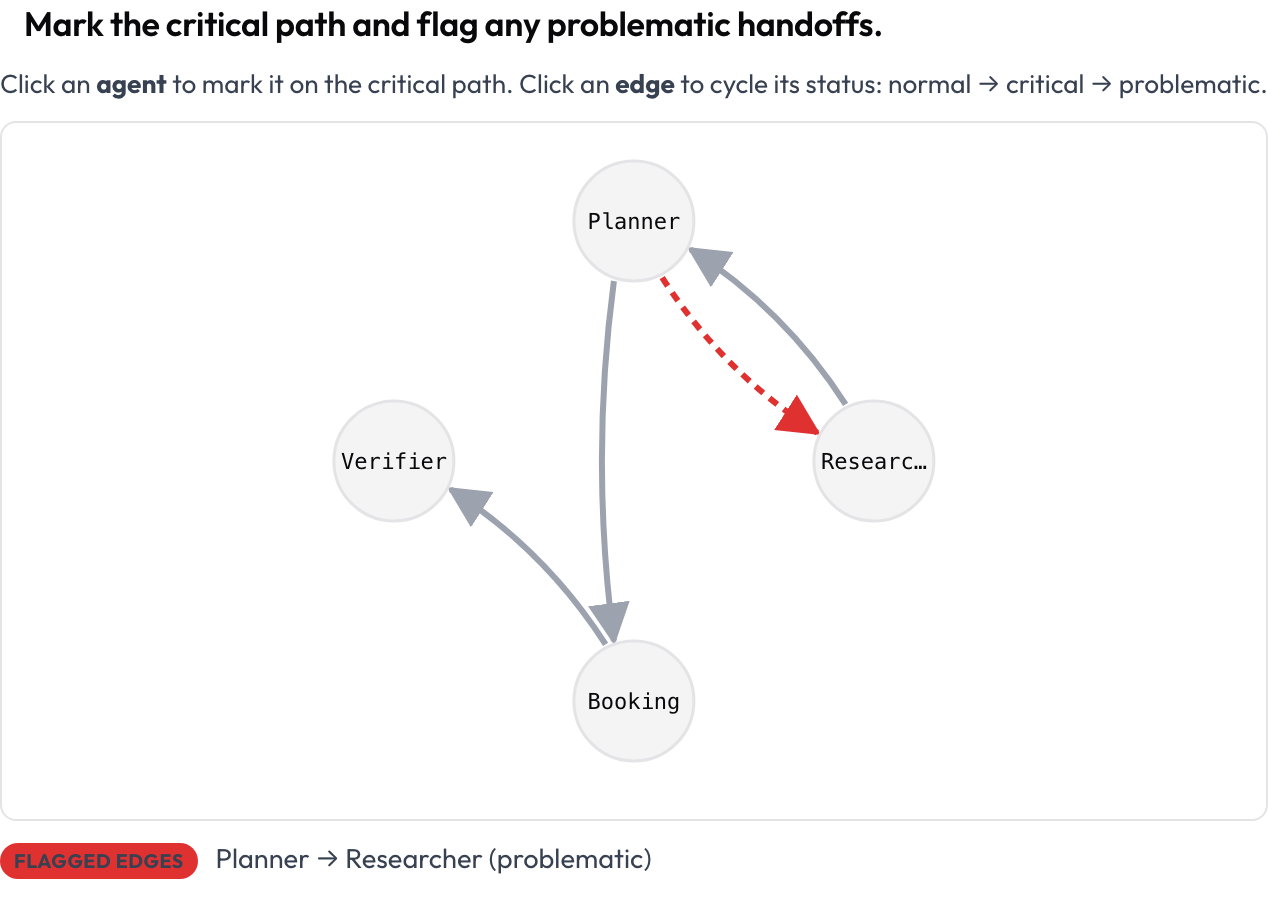 Markieren Sie den kritischen Pfad und kennzeichnen Sie problematische Übergaben
Markieren Sie den kritischen Pfad und kennzeichnen Sie problematische Übergaben
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentDer Graph wird automatisch aus dem Trace angeordnet, Sie zeichnen also nichts. Jeder Knoten und jede Kante ist per Tastatur fokussierbar, und eine Textzusammenfassung listet die kritischen Knoten und gekennzeichneten Kanten auf, sodass die Bedeutung nie allein auf der Farbe beruht. Diese Ansicht ist der schnellste Weg, um zu beantworten: „Was hat mit was gesprochen, und wo ist der Pfad schiefgelaufen?“
Wie ordne ich einen Multi-Agent-Fehler einem einzigen Agenten zu?
Sobald Sie den Lauf sehen können, fixieren Sie den Fehler. Das Schema failure_attribution fragt nach dem Tripel aus der Literatur zur Fehlerzuordnung (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, das Who&When-Dataset): den verantwortlichen Agenten, den entscheidenden Schritt und den Grund. Das Agenten-Dropdown und die Schrittauswahl werden aus den eigenen Runden des Traces befüllt, sodass Sie den Fehler nur einem Agenten und einem Schritt zuordnen können, die tatsächlich stattgefunden haben.
 Ordnen Sie den Fehler dem verantwortlichen Agenten, dem entscheidenden Schritt und dem Warum zu
Ordnen Sie den Fehler dem verantwortlichen Agenten, dem entscheidenden Schritt und dem Warum zu
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agentDie Zuordnung mit einem Erfolg/Misserfolg-Radio zu koppeln bedeutet, dass das Tripel nur bei fehlgeschlagenen Läufen erhoben wird, was die Zeit des Annotators auf die Fälle konzentriert, die Signal tragen.
Was ist mit den Übergaben selbst?
Die Zuordnung benennt einen entscheidenden Schritt. Die Übergabeprüfung betrachtet jeden Kontrollwechsel. Überall dort, wo der handelnde Agent zwischen aufeinanderfolgenden Runden wechselt, gibt Potato eine Übergabekarte A → B aus, und Sie kennzeichnen, was in der Übergabe schiefging — Informationsverlust, eine verlorene Vorgabe, Verstümmelung, Zieldrift — und bewerten die Qualität. Die Fehlermodi stammen aus der Inter-Agenten-Kategorie von MAST und dem „Echoing“-Phänomen (Zhang et al., 2025).
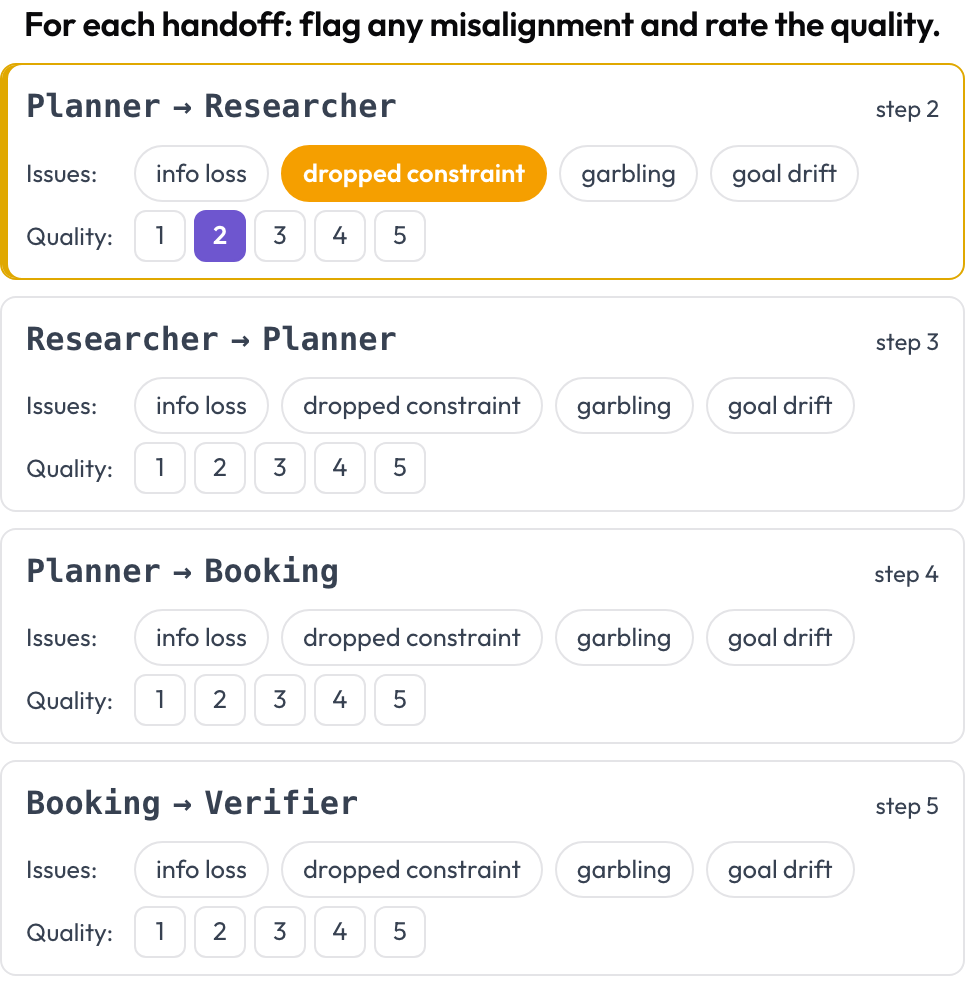 Kennzeichnen Sie Fehlausrichtungen zwischen Agenten bei jeder Übergabe und bewerten Sie deren Qualität
Kennzeichnen Sie Fehlausrichtungen zwischen Agenten bei jeder Übergabe und bewerten Sie deren Qualität
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Übergaben werden zur Renderzeit abgeleitet, es gibt also keine manuelle Einrichtung. Hier lösen sich meist die Fälle „jeder Agent sah in Ordnung aus, das Team scheiterte trotzdem“ auf: Die Vorgabe war in Agent A noch lebendig und bei Agent B verschwunden.
Wie bewerte ich die Agenten und das Team?
Ein Fehler sagt Ihnen, was einmal gebrochen ist. Ein Bewertungsbogen sagt Ihnen, ob ein Design über viele Läufe hinweg gut ist. Das Schema agent_scorecard bewertet zwei Ebenen zugleich (MultiAgentBench, Zhou et al., ACL 2025): jeden Agenten nach Rollentreue, Beitrag und Koordination und das Team nach seinen eigenen gemeinsamen Dimensionen, mit optionalen Meilensteinen. Die Agentenzeilen stammen aus dem Trace, sodass die Matrix dazu passt, wer tatsächlich teilgenommen hat.
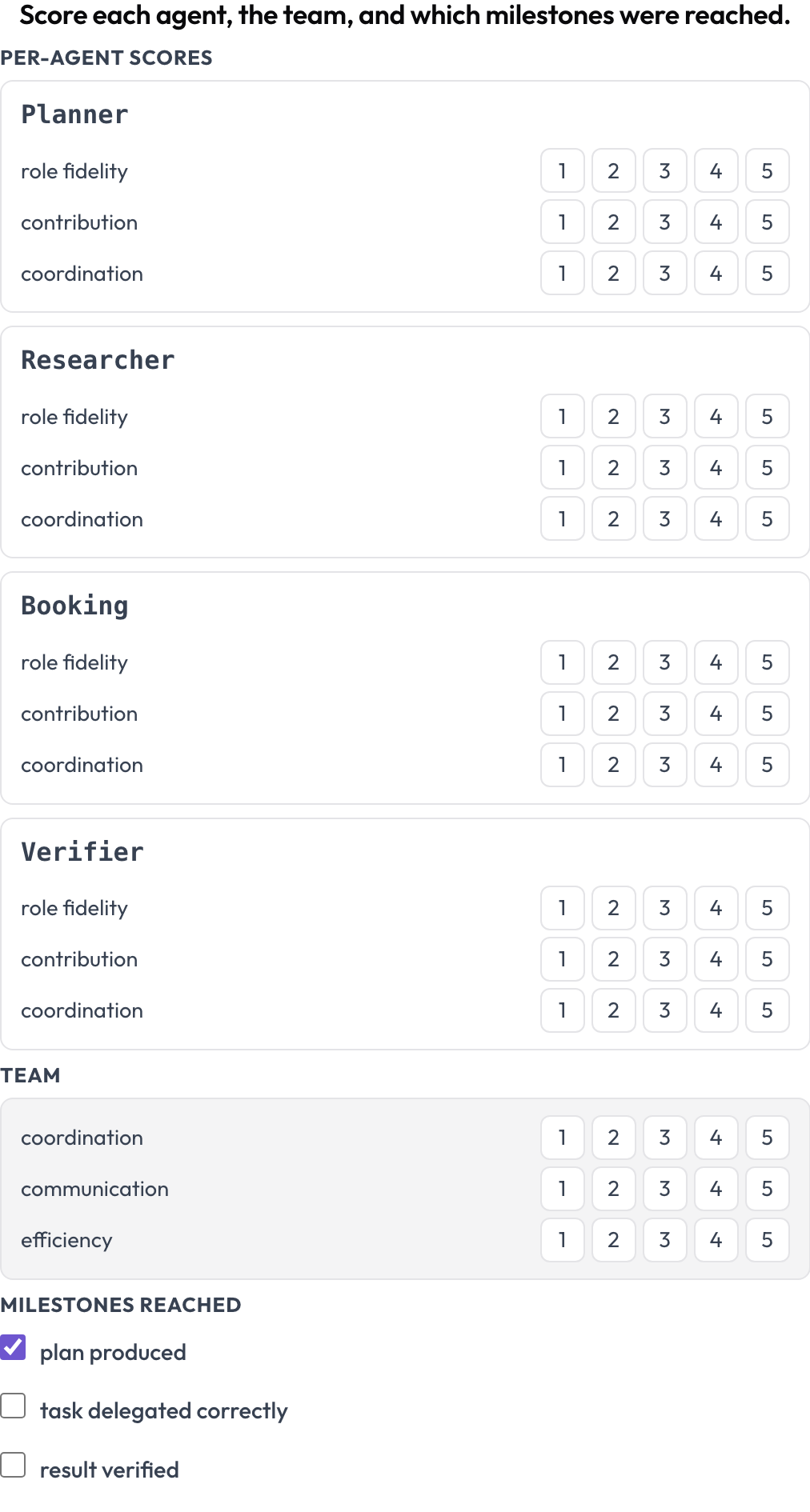 Bewerten Sie jeden Agenten nach Rollentreue, Beitrag und Koordination, dazu das Team
Bewerten Sie jeden Agenten nach Rollentreue, Beitrag und Koordination, dazu das Team
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]Ein starker Agent, der in einem schlecht koordinierten Team feststeckt, zeigt sich hier als hohe Agentenzeile neben niedrigen Teamdimensionen, was genau das Muster ist, das Sie wollen, wenn Sie sequenzielle gegen hierarchische gegen Group-Chat-Orchestrierung bei denselben Aufgaben vergleichen.
Was ist mit Nebenläufigkeit und kollektiven Fehlern?
Zwei weitere Oberflächen fangen Fehler ab, die ein Lesen Runde für Runde nicht erkennen kann. Die tool_contention-Zeitleiste stellt jeden Agenten auf seine eigene Spur und hebt Bereiche hervor, in denen zwei Aufrufe zu überlappenden Zeiten dieselbe Ressource berühren, die Sie als Deadlock, zirkuläres Warten, Race Condition oder harmlos klassifizieren (DPBench, 2026).
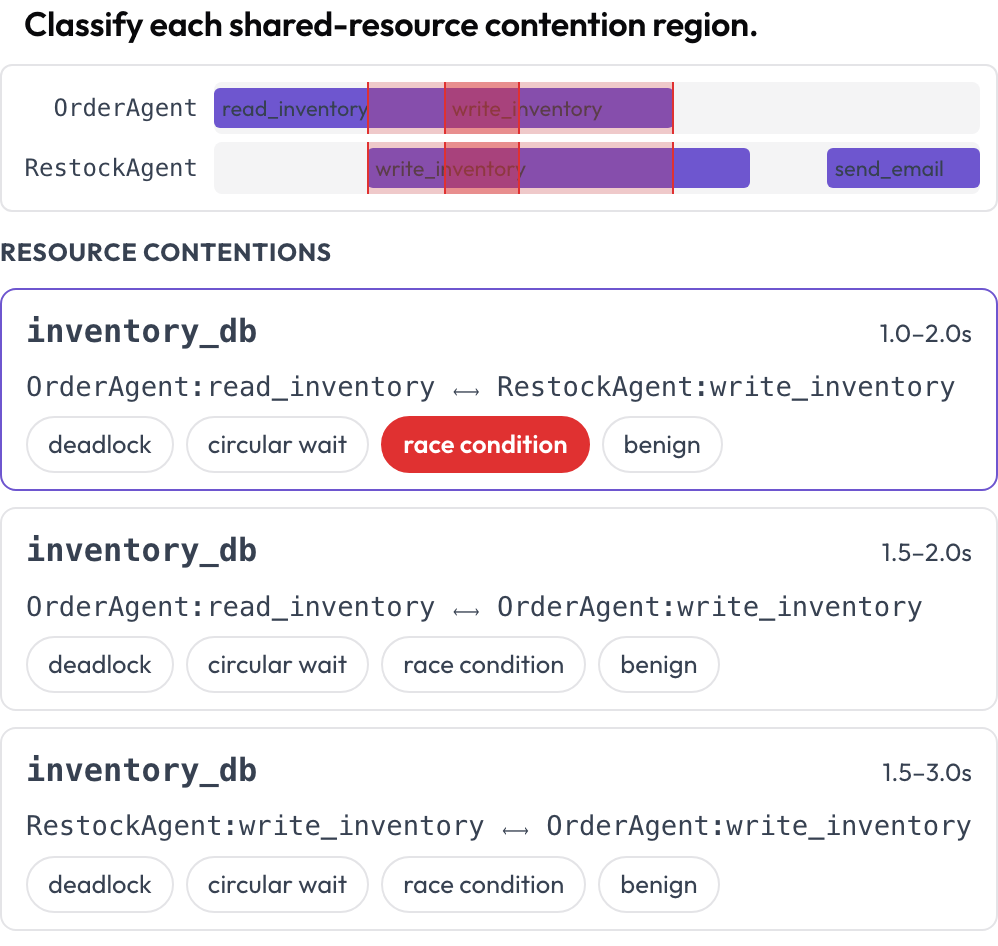 Erkennen Sie Deadlocks und Race Conditions auf einer Tool-Aufruf-Zeitleiste pro Agent
Erkennen Sie Deadlocks und Race Conditions auf einer Tool-Aufruf-Zeitleiste pro Agent
Und emergent_behavior behandelt Fehler, die kollektiv sind, statt an einem Schritt zu liegen — Kollusion, Groupthink, kaskadierende Fehler, Rollendrift. Ein emergentes Verhalten ist keine zusammenhängende Spanne; es ist eine Menge beteiligter Runden, möglicherweise von verschiedenen Agenten, sodass Sie die teilnehmenden Runden ankreuzen und eine Notiz hinzufügen.
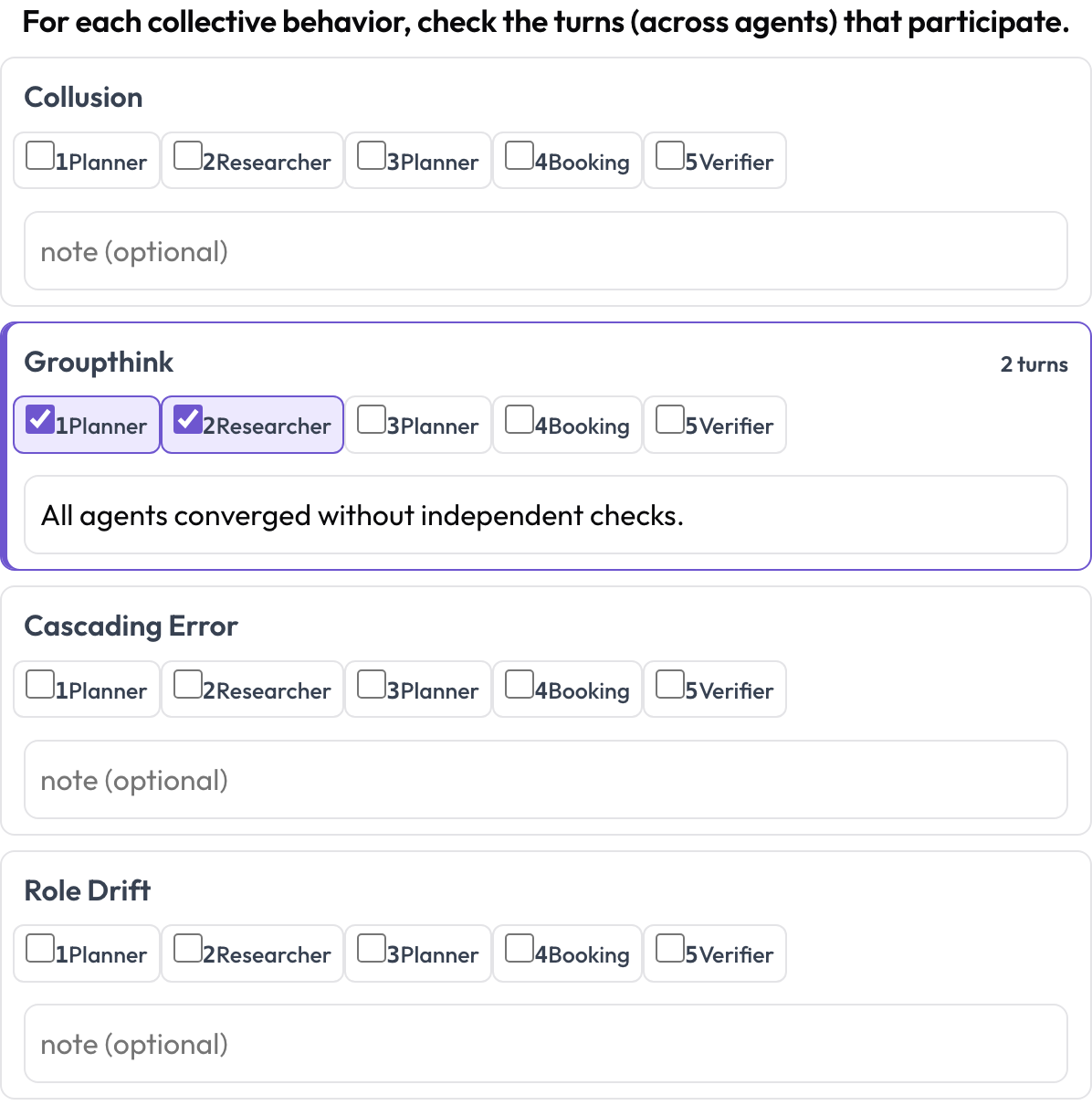 Markieren Sie Kollusion, Groupthink und kaskadierende Fehler über Agenten und Runden hinweg
Markieren Sie Kollusion, Groupthink und kaskadierende Fehler über Agenten und Runden hinweg
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueIn die richtige Reihenfolge bringen
Bei einem echten fehlgeschlagenen Lauf ist die Reihenfolge meist: Lesen Sie den Interaktionsgraphen, um die Form zu sehen, nutzen Sie die Fehlerzuordnung, um den entscheidenden Schritt zu benennen, öffnen Sie die Übergabeprüfung, wenn der entscheidende Schritt eine Übergabe war, und greifen Sie zur Contention-Zeitleiste oder zum Tagging von emergentem Verhalten, wenn der Fehler mit Timing oder der Gruppe statt mit einem einzelnen Agenten zu tun hat. Bewerten Sie mit dem Bewertungsbogen, sobald Sie Designs vergleichen statt einen Lauf zu debuggen. Messen Sie die Übereinstimmung bei der Zuordnung so, wie Sie es bei jedem subjektiven Label tun würden; siehe Inter-Annotator-Übereinstimmung.
Weiterführende Lektüre
- Multi-Agent-Teambewertung — die vollständige Schemareferenz mit YAML für jede Oberfläche
- So bewerten Sie Multi-Agent-Systeme — der Entscheidungsleitfaden, welche Methode wann zu verwenden ist
- Potato 2.6.2: Eine vollständige Open-Source-Suite zur Agentenbewertung — alles, was über die 2.6.x-Reihe ausgeliefert wurde
- Agententrajektorien annotieren — Fehlertaxonomien pro Schritt, einschließlich MAST-Tagging auf Schrittebene