Sprach- und Video-Agenten bewerten
Eine Anleitung zur menschlichen Bewertung von Sprach-, Video- und Dokumentenagenten in Potato: den Sprecherwechsel auf einer zweispurigen Zeitleiste bewerten, Videoereignisse mit live berechnetem IoU verankern, Sprachfehler markieren und die Tabellenstruktur kennzeichnen.
Agenten, die sprechen, Videos schauen und Dokumente lesen, scheitern auf Weisen, die ein Textfeld nicht zeigen kann. Die Fehler eines Sprachagenten leben an den Nahtstellen zwischen den Runden; die Antwort eines Videoagenten ist ein Zeitintervall, kein Satz; der Fehler eines Dokumentenagenten ist eine falsch gelesene Tabellenzelle. Jede dieser braucht eine Prüfoberfläche, die auf die Modalität zugeschnitten ist. Potato fügt vier solche Oberflächen hinzu — Sprache, Video, Sprechen und Dokument — neben seinen bestehenden Anzeigen für Bild und Audio. Die vollständige Referenz ist Multimodale Agentenbewertung.
 Ein einfaches Text-Widget kann kein Barge-in, kein Ereignisintervall und keine Tabellenzelle ausdrücken
Ein einfaches Text-Widget kann kein Barge-in, kein Ereignisintervall und keine Tabellenzelle ausdrücken
Wie bewerte ich den Sprecherwechsel eines Sprachagenten?
Gesprochene Agenten brechen an den Grenzen: Sie unterbrechen den Nutzer, reden über ihn hinweg oder pausieren so lange, dass der Nutzer aufgibt. Das Schema voice_interaction legt die Unterhaltung als zweispurige Zeitleiste aus — eine Nutzerspur und eine Agentenspur — und hebt die Überlappungsbereiche hervor, in denen beide gleichzeitig sprechen (Full-Duplex-Bench, 2025). Sie klassifizieren jede Überlappung und bewerten den gesamten Sprecherwechsel; das Audio wird inline abgespielt, wenn es vorhanden ist.
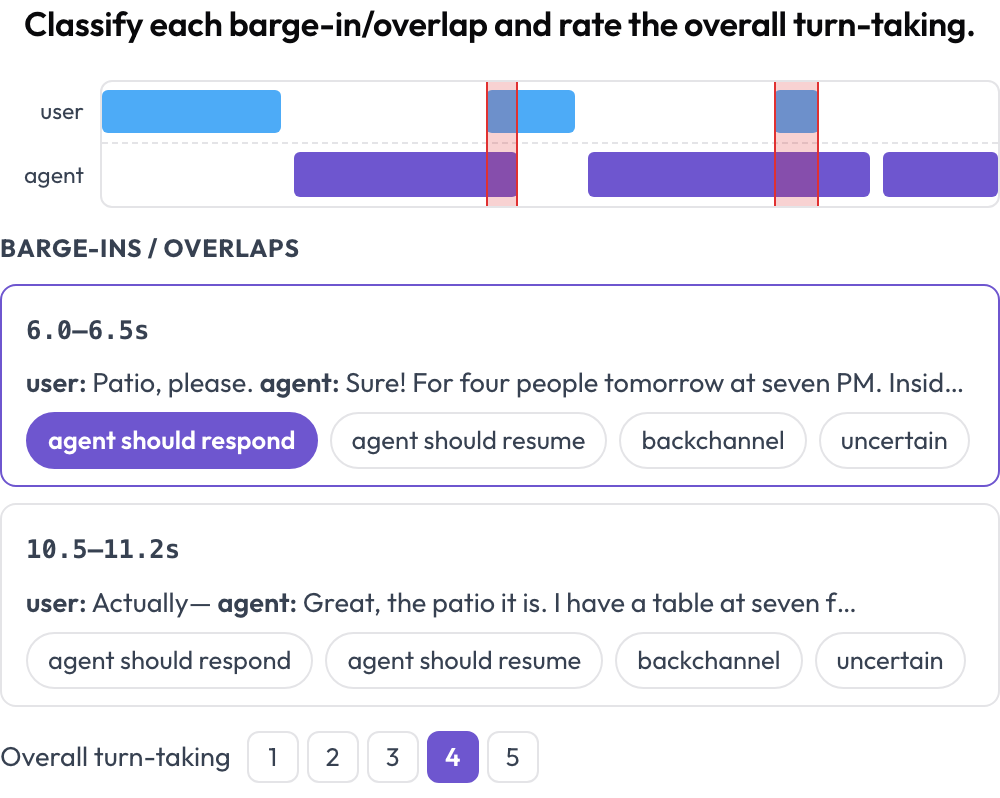 Zweispurige Sprachzeitleiste mit Barge-in-Erkennung und Bewertung des Sprecherwechsels
Zweispurige Sprachzeitleiste mit Barge-in-Erkennung und Bewertung des Sprecherwechsels
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5Die Überlappungen werden zur Renderzeit aus den Zeitangaben der Runden berechnet, sodass eine Vollduplex-Unterhaltung, die ein flaches Transkript zu „beide haben etwas gesagt“ verflachen würde, zu einer Menge konkreter, labelbarer Momente wird.
Wie bewerte ich die zeitliche Verankerung eines Videoagenten?
Die Antwort eines Videoagenten auf „Wann passiert das Ziel?“ ist ein Intervall, also bewerten Sie sie als solches. Das Schema temporal_grounding gibt Ihnen einen Scrubber, auf dem Sie für jeden Ereignis-Prompt das Gold-[start, end] markieren, indem Sie den Abspielkopf erfassen oder Sekunden eintippen. Wenn die Daten das vom Modell vorhergesagte Intervall tragen, aktualisieren sich ein live berechnetes IoU und eine Zweibalken-Mini-Zeitleiste, während Sie anpassen (TimeScope, 2025).
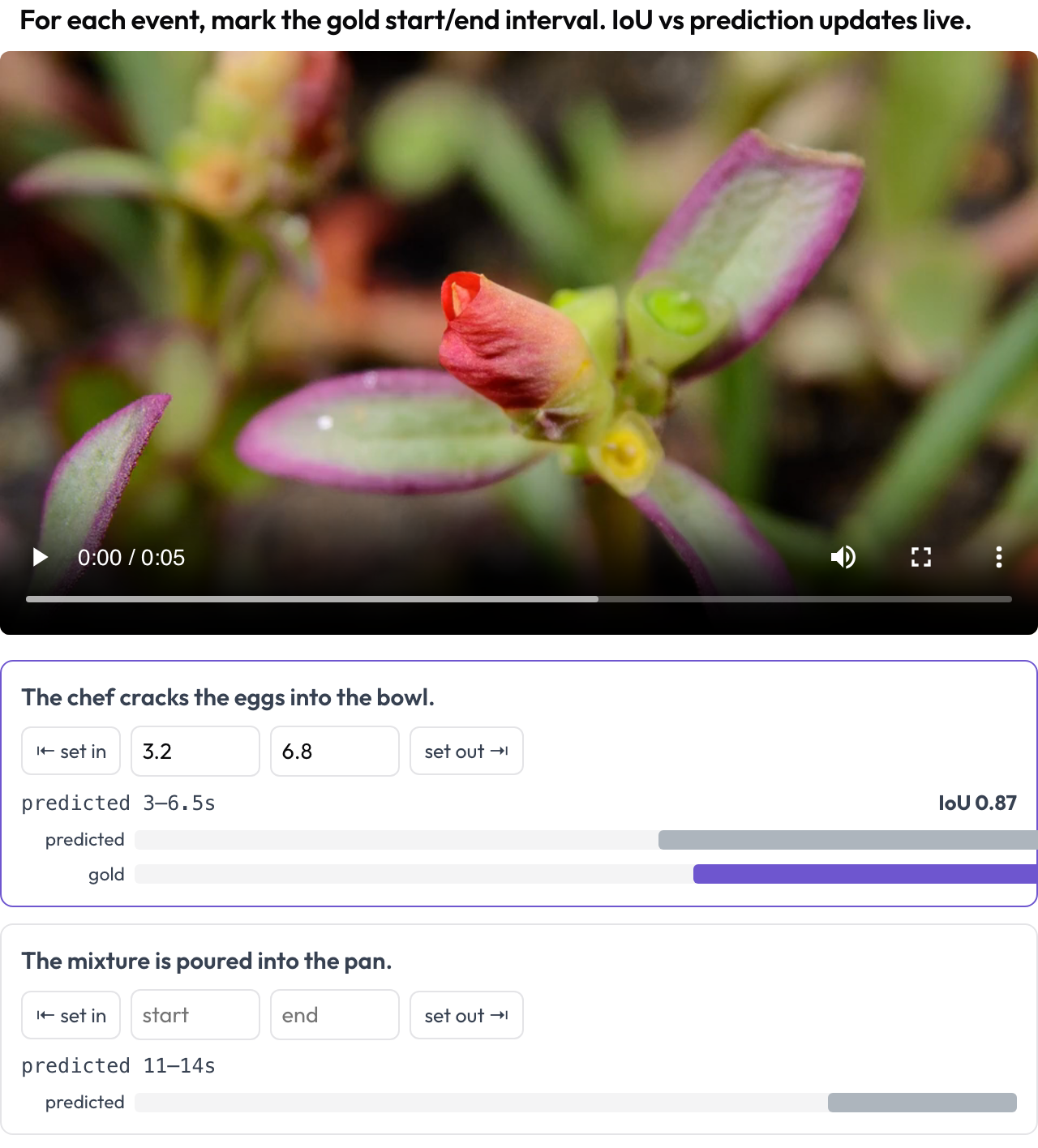 Markieren Sie Gold-Ereignisintervalle im Video mit einem live berechneten IoU gegenüber der Vorhersage des Modells
Markieren Sie Gold-Ereignisintervalle im Video mit einem live berechneten IoU gegenüber der Vorhersage des Modells
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsDas ist für die Lokalisierung von Vorhersage gegen Gold gebaut, was eine andere Aufgabe ist als allgemeines Segment-Labeling: Sie bewerten, wie nah die Spanne des Modells an der Wahrheit liegt, und zu sehen, wie sich das IoU bewegt, während Sie die Grenze ziehen, macht das unmittelbar.
Was ist mit Sprachtranskripten, Reasoning und Tabellen?
Drei weitere Oberflächen decken den Rest des multimodalen Spektrums ab:
- Sprachtranskripte (
speech_transcript): Jedes zeitlich ausgerichtete Segment ist eine Karte; Sie markieren ASR-/TTS-Fehler, Aussprachefehler und Sprechfehler und korrigieren den Text inline (Speak & Improve, 2025). Das ist die Ergänzung auf Segmentebene zur Sprecherwechsel-Ansicht. - Verschränktes Reasoning (
multimodal_reasoning): ein Text-Bild-Tool-Trace, dargestellt als typisierte Blöcke; Sie bewerten die Kohärenz jedes Schritts und kennzeichnen visuelle Halluzinationen, bei denen das Reasoning nicht aus dem Bild folgt (Multimodal RewardBench 2, 2025). - Dokumenttabellen (
table_grid): Sie legen die Gitterdimensionen fest und klicken Zellen an, um ihre Rolle zu markieren — Daten, Spaltenkopf, Zeilenkopf, leer — und erfassen so die Struktur, die Bounding-Boxes nicht können.
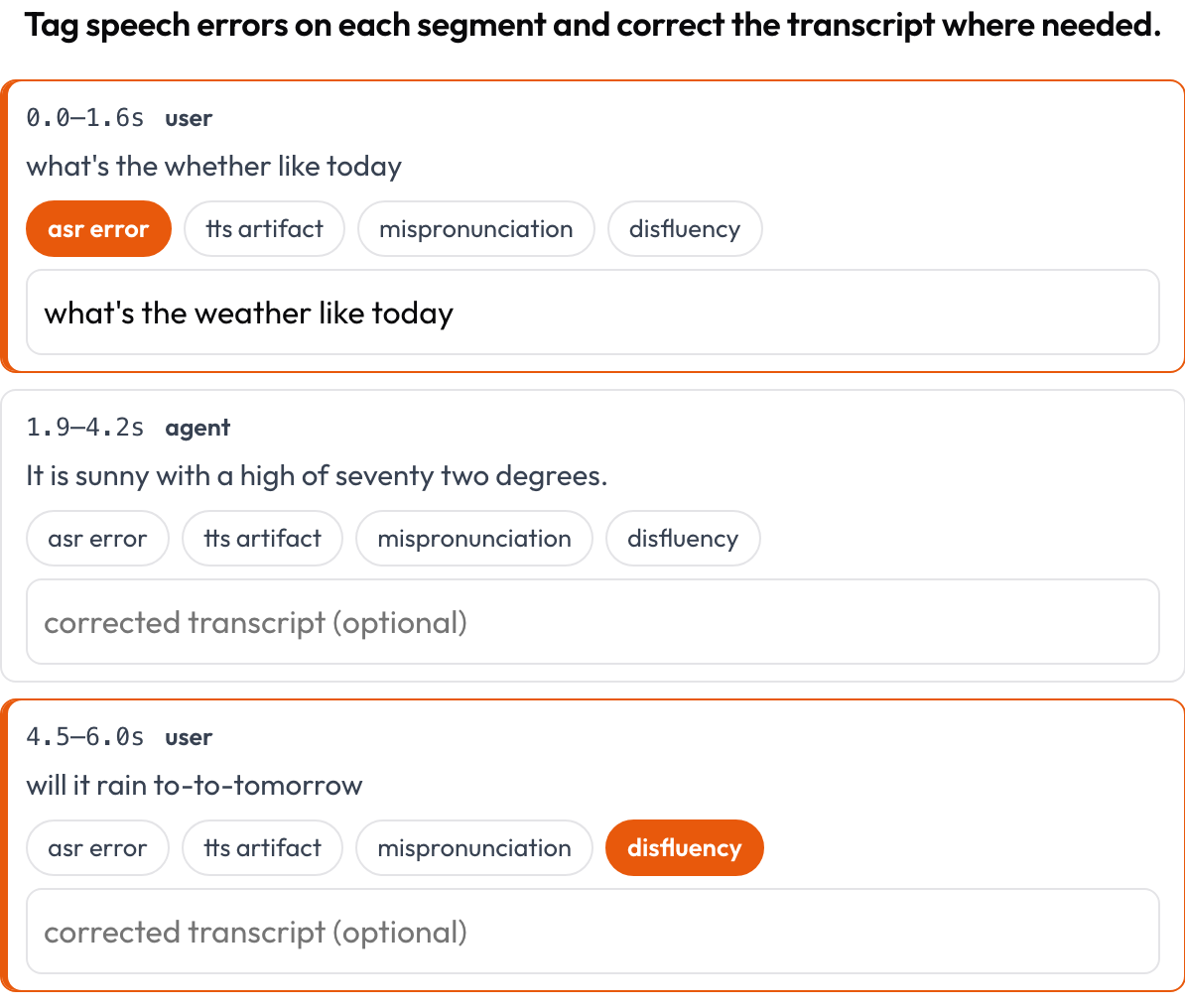 Markieren Sie ASR-/TTS-/Aussprachefehler pro Segment und korrigieren Sie das Transkript inline
Markieren Sie ASR-/TTS-/Aussprachefehler pro Segment und korrigieren Sie das Transkript inline
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true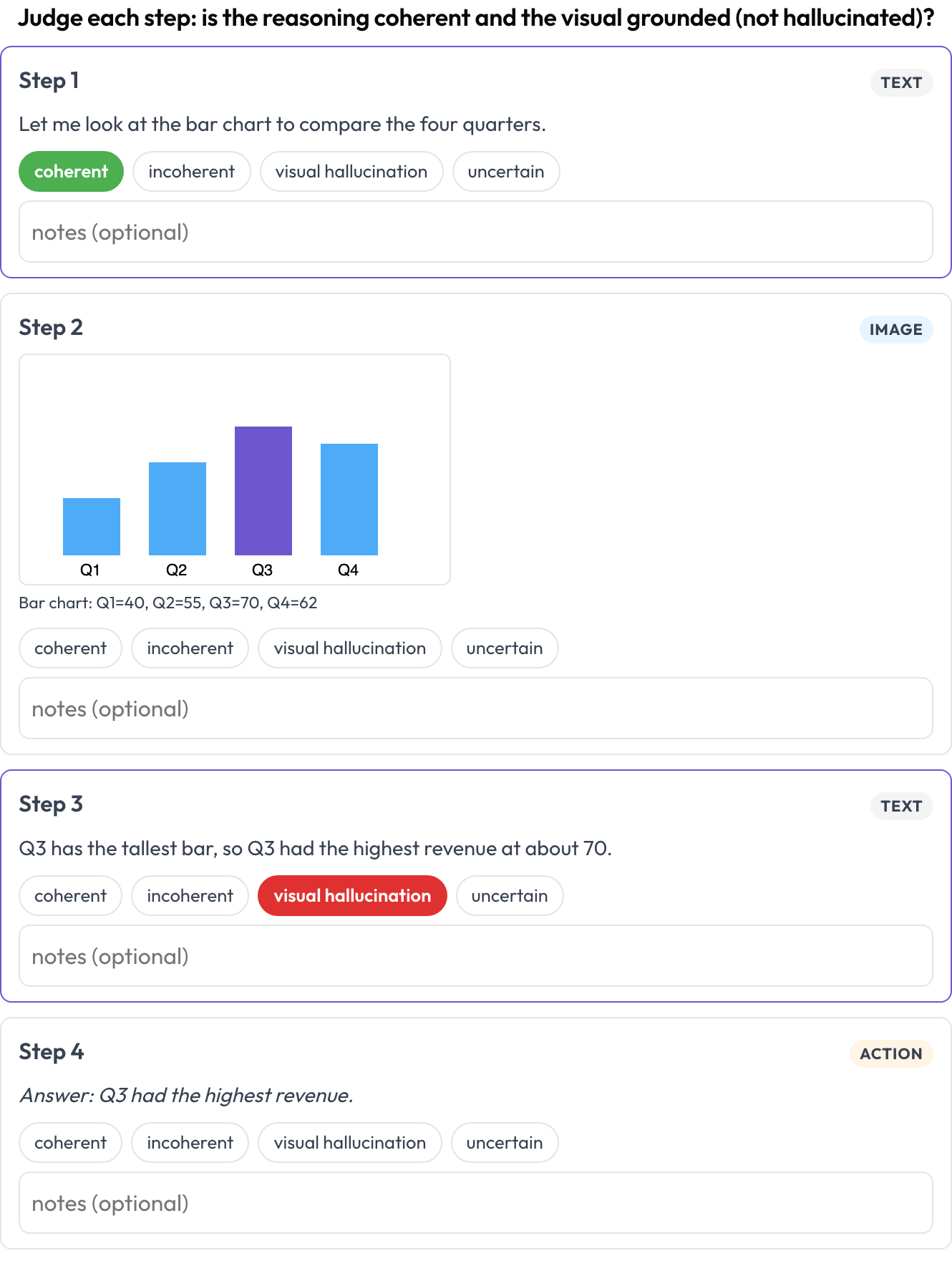 Bewerten Sie jeden Schritt eines Text-Bild-Tool-Reasoning-Traces auf Kohärenz und visuelle Halluzination
Bewerten Sie jeden Schritt eines Text-Bild-Tool-Reasoning-Traces auf Kohärenz und visuelle Halluzination
Mehrere dieser Schemata können in derselben Aufgabe laufen, sodass ein einzelner Dokumentenagenten-Lauf zugleich auf Tabellenstruktur und Reasoning-Kohärenz bewertet werden kann.
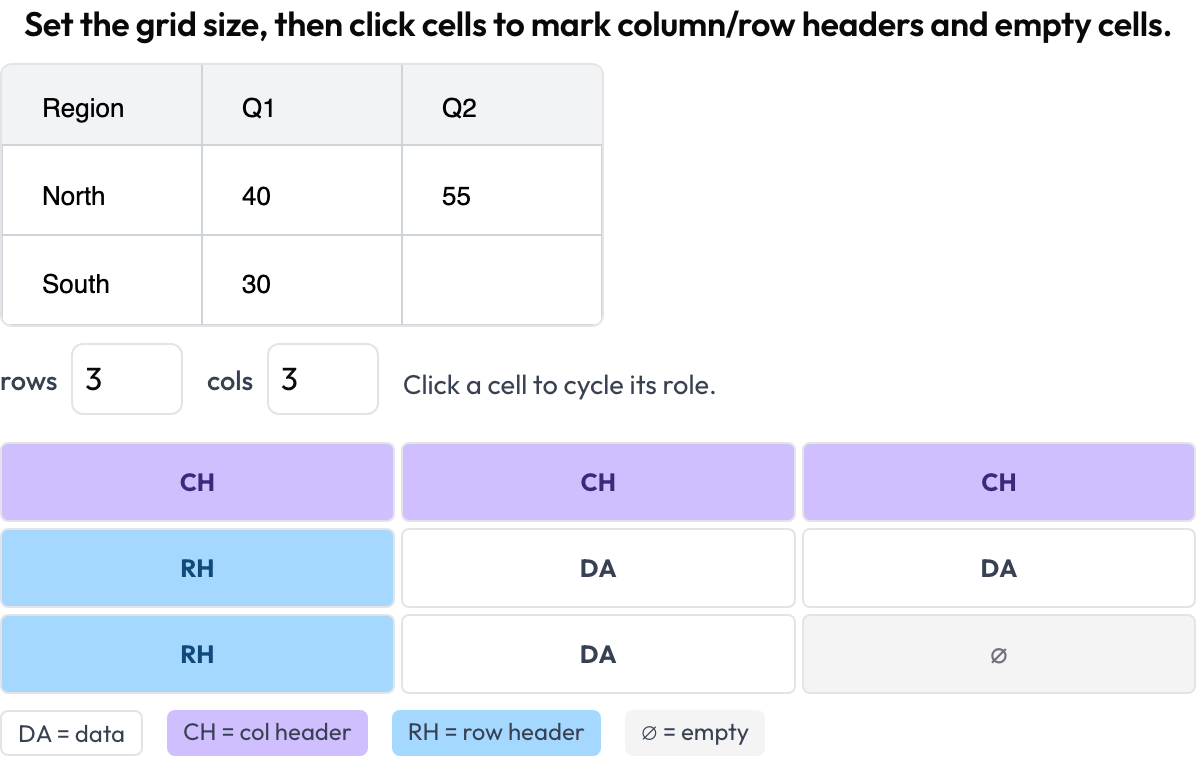 Annotieren Sie die Zellenstruktur einer Dokumenttabelle: Spalten- und Zeilenköpfe, Daten und leere Zellen
Annotieren Sie die Zellenstruktur einer Dokumenttabelle: Spalten- und Zeilenköpfe, Daten und leere Zellen
Wie richte ich das ein?
Jede Oberfläche wird mit einem ausführbaren Beispiel unter examples/agent-traces/ ausgeliefert:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000Ihre Daten kommen als Runden, Segmente oder Ereignisse mit Zeitstempeln hinein; die Oberfläche leitet ihre Zeitleiste zur Renderzeit daraus ab. Für GUI- und OS-Agenten ist das Begleitstück Computer-Use-Agenten bewerten.
Weiterführende Lektüre
- Multimodale Agentenbewertung — die vollständige Schemareferenz
- Computer-Use- und multimodale Agenten bewerten — der Leitfaden mit einer Tabelle zur Schemaauswahl
- Computer-Use-Agenten bewerten, Schritt für Schritt — die GUI- und OS-Hälfte der multimodalen Oberflächen
- Potato 2.6.2: Eine vollständige Open-Source-Suite zur Agentenbewertung — alles in der 2.6.x-Reihe