Computer-Use-Agenten bewerten, Schritt für Schritt
Eine Anleitung zur menschlichen Bewertung von Computer-Use- und GUI-Agenten in Potato: jede Aktion beurteilen, das Klick-Grounding auf dem Screenshot prüfen und Tool-Aufrufe einzeln durchgehen.
Ein Computer-Use-Agent liest einen Screenshot, entscheidet sich für eine Aktion und klickt. Ihn zu bewerten heißt, jeden Schritt zu prüfen: War die Aktion richtig, und ist der Klick tatsächlich auf dem Element gelandet, das er benannt hat — nicht nur, ob die Aufgabe am Ende erfolgreich war. Der Aufgabenerfolg verbirgt den Klick, der den falschen Button traf, aber trotzdem weiterkam, und die Aktion, die nur durch Glück richtig war. Potato prüft diese Läufe mit einer eigens gebauten GUI-Trajektorien-Oberfläche und einer Tool-Aufruf-Prüfung, beide in YAML konfiguriert.
Ein Computer-Use-Agent — auch GUI- oder OS-Agent genannt — sieht den Bildschirm als Pixel oder DOM und handelt über dieselben Bedienelemente, die ein Mensch hat. Benchmarks wie OSWorld, ScreenSpot und AndroidWorld bewerten die Aufgabenerfüllung automatisch. Automatische Bewertung ist günstig und einen Durchlauf wert, aber sie kann Ihnen nicht sagen, warum ein Lauf scheiterte, oder den glücklichen Durchgang aufdecken. Genau diese Lücke füllt die menschliche Schrittprüfung.
 Beurteilen Sie die Aktion und ob der Klick auf dem benannten Element gelandet ist
Beurteilen Sie die Aktion und ob der Klick auf dem benannten Element gelandet ist
Was beurteilen Sie in einer GUI-Trajektorie eigentlich?
Jeder Schritt paart einen Screenshot (was der Agent sah) mit einer Aktion (was er tat). Sie beurteilen die Aktion, und wenn der Schritt Klickkoordinaten trägt, prüfen Sie den Grounding-Marker, den Potato auf den Screenshot zeichnet:
- Aktionskorrektheit — korrekt, falsches Element, falsche Aktion oder halluziniert.
- Klick-Grounding — sind die Koordinaten auf dem Element gelandet, das die Aktion benannt hat?
- Ergebnis — hat der Lauf die Aufgabe abgeschlossen, und bei welchem Schritt ging er zuerst schief?
 Prüfen Sie jeden Schritt: Aktionskorrektheit plus Klick-Grounding auf dem Screenshot
Prüfen Sie jeden Schritt: Aktionskorrektheit plus Klick-Grounding auf dem Screenshot
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot
action_key: action
coord_space: normalized
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Jeder Schritt liefert screenshot, action und optionale x/y (oder ein verschachteltes click: {x, y}). Der Grounding-Marker ist der Teil, den automatisierte Metriken am häufigsten verfehlen: Ein Modell kann das richtige Aktionslabel ausgeben, während es zehn Pixel neben dem Ziel klickt, und ein Pass/Fail auf dem Endbildschirm wird das nie aufdecken.
Warum zählt der erste falsche Schritt mehr als das Endergebnis?
Weil dieser Schritt das ist, was Sie beheben oder worauf Sie trainieren würden. Ein Lauf, der bei Schritt 9 scheitert, weil Schritt 3 einen Dialog falsch las, ist in Wirklichkeit ein Problem von Schritt 3, und ihn bei Schritt 9 zu labeln, lehrt die falsche Lektion. Die erste Abweichung zu erfassen ist dieselbe Idee, die hinter Process Reward Models steht: Ein Signal bei jedem Schritt lokalisiert den Fehler, statt die ganze Trajektorie in eine einzige Zahl zusammenzufassen.
Wie prüfe ich die Tool-Aufrufe eines Agenten?
GUI-Agenten rufen außerdem Tools und Funktionen auf, und die scheitern auf ihre eigene Weise: richtige Absicht, falsches Tool; richtiges Tool, fehlerhafte Argumente; richtiger Aufruf, falsche Reihenfolge. Das Schema tool_call_review zieht jeden Aufruf aus dem Trace und gibt ihm eine Karte mit dem Tool-Namen und hübsch formatierten Argumenten, sodass Sie sie einzeln beurteilen (analog zu BFCL v4 / MCPMark).
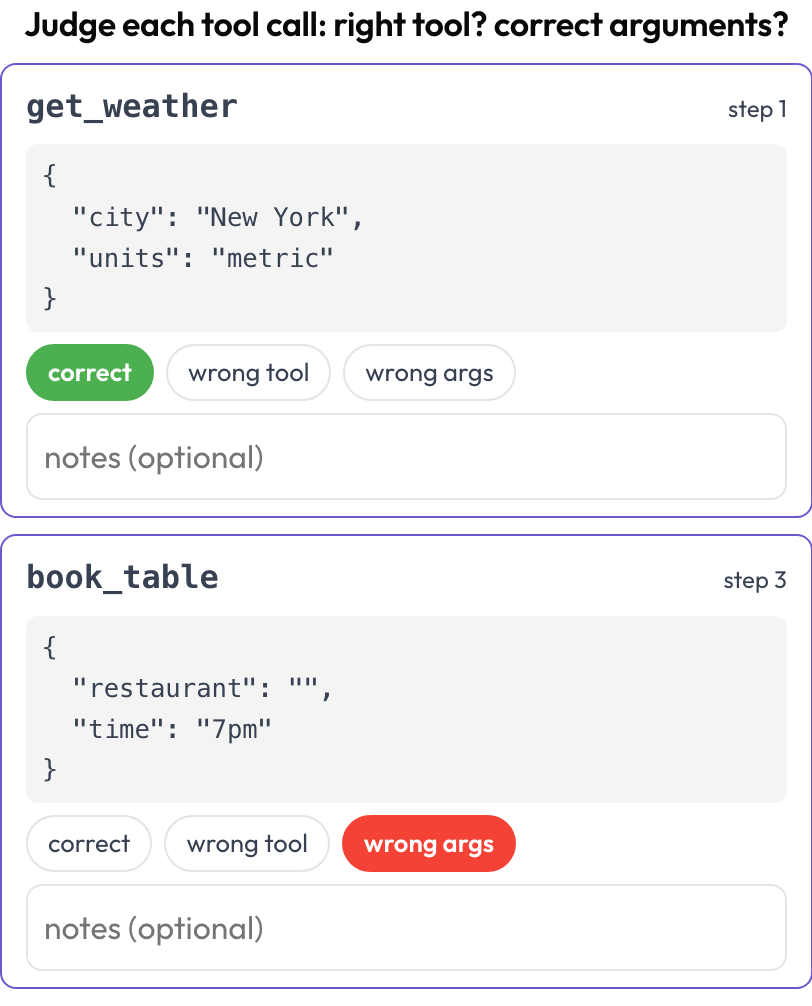 Beurteilen Sie jeden Tool-Aufruf: richtiges Tool, korrekte Argumente, richtige Reihenfolge
Beurteilen Sie jeden Tool-Aufruf: richtiges Tool, korrekte Argumente, richtige Reihenfolge
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order]Tool-Aufrufe werden zur Renderzeit aus dem Feld tool_calls, tool_call oder action jedes Schritts extrahiert, sodass eine Trajektorie, die UI-Klicks und API-Aufrufe vermischt, in einer einzigen Aufgabe auf beiden Achsen geprüft werden kann.
Wie richte ich das ein?
Jede Oberfläche wird mit einem ausführbaren Beispiel unter examples/agent-traces/ ausgeliefert. Richten Sie Potato auf eines davon, um das Schema mit Beispieldaten zu sehen:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/gui-trajectory/config.yaml -p 8000Ihre eigenen Daten kommen als Liste von Schritten hinein, jeder mit einer Screenshot-URL oder einem Daten-URI und einem Aktionsstring. Für umfassendere Web-Agenten, die aus gerenderten Seiten statt aus rohen Screenshots arbeiten, siehe Web-Agenten bewerten.
Weiterführende Lektüre
- Multimodale Agentenbewertung — die vollständige Schemareferenz für GUI-, Sprach-, Video- und Dokumentenagenten
- Computer-Use- und multimodale Agenten bewerten — der Leitfaden mit einer Tabelle zur Schemaauswahl
- Sprach- und Video-Agenten bewerten — die andere Hälfte der multimodalen Oberflächen
- Potato 2.6.2: Eine vollständige Open-Source-Suite zur Agentenbewertung — die vollständige 2.6.x-Reihe