Potato 2.6.2: A Complete Open-Source Agent-Evaluation Suite
The 2.6.x line turns Potato into a full, free agent-evaluation platform: trace ingestion from OpenTelemetry, LangGraph, CrewAI, and AutoGen, multi-agent team annotation with a clickable interaction graph, multimodal-agent schemas for GUI, voice, and video, plus a model arena, CI gating, and curation.
Potato 2.6 brought the first wave of agent evaluation: LLM-as-judge calibration, trajectory editing for training data, and the three-pane eval_trace display. The 2.6.x point releases since then fill in the rest. As of 2.6.2, Potato is a complete agent-evaluation platform: you can capture traces from your own agents, annotate single agents, multi-agent teams, and multimodal agents, judge them with LLMs you can trust, rank models in an arena, and gate releases in CI. All of it is configured in YAML and stays on your own server.
 Potato multi-agent evaluation
Potato multi-agent evaluation
Most of these are capabilities people currently pay a hosted platform to get. Potato does them free and self-hosted. Here is what shipped across the 2.6.x line.
 The 2.6.x agent-evaluation suite, end to end
The 2.6.x agent-evaluation suite, end to end
Get traces in: a capture SDK and open standards
Evaluation starts with real runs. The new potato_trace SDK instruments any agent: decorate a function with @traceable (sync or async) and nested calls are captured and sent to Potato's ingestion endpoint, with an optional OpenTelemetry export. Potato also ingests OpenTelemetry / OpenInference spans and LangGraph, CrewAI, and AutoGen run formats, so traces from the framework you already use land in the annotation queue without glue code. New traces can arrive over a webhook, a poller, or a watched directory and become assignable to annotators as they land.
Reference: Tracing SDK, Automation Rules.
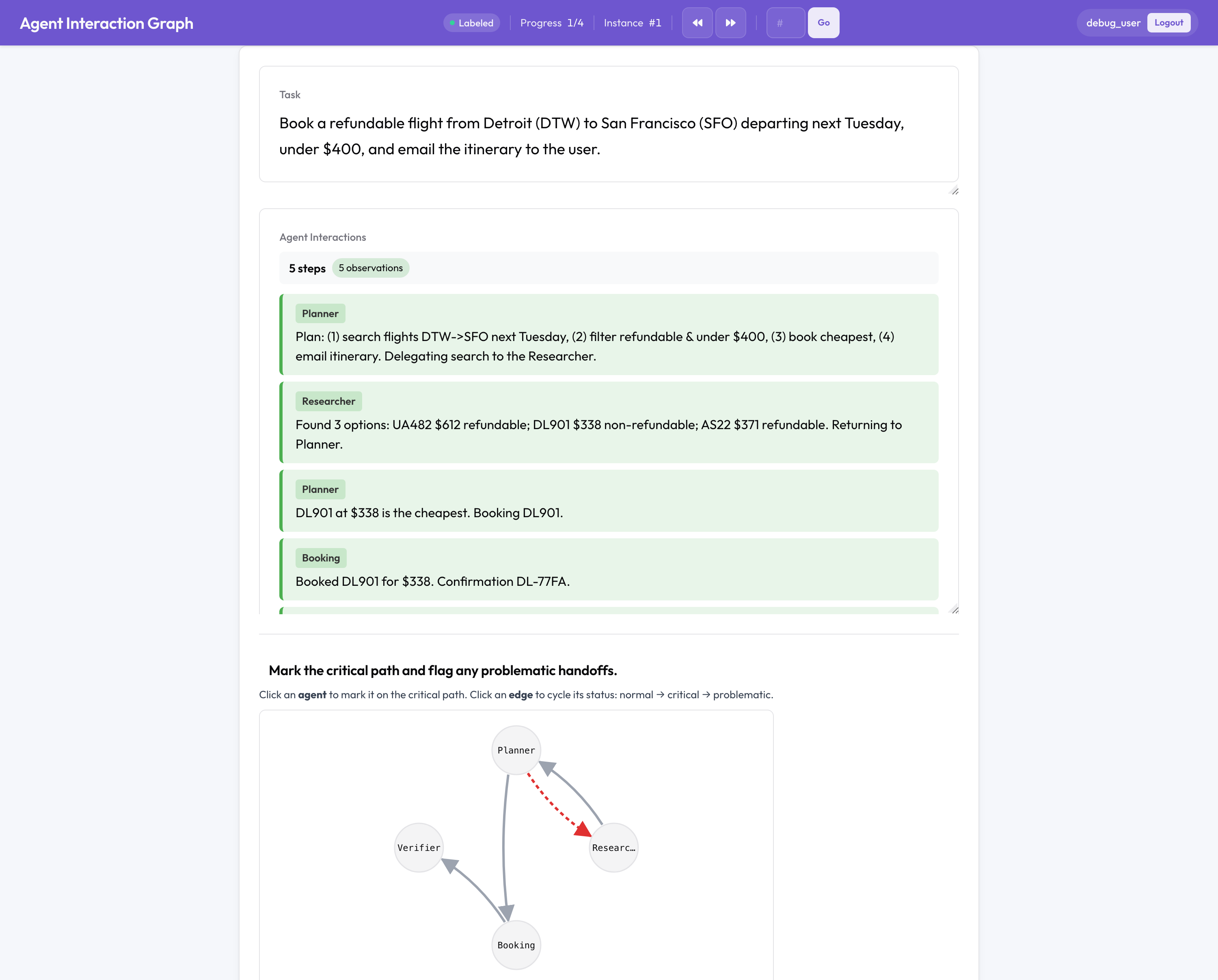
See the whole team: multi-agent evaluation
This is the part with no open-source equivalent. A multi-agent run fails differently than a single agent, between agents, at a handoff, in how the team was organized, so Potato annotates the team structure rather than a flat transcript:
- A clickable interaction graph of agents and handoffs, where you mark the critical path and flag problematic edges.
- Failure attribution: pick the responsible agent, the decisive step, and the reason, the (agent, step, reason) triple from the Who&When attribution work.
- Handoff review: every control transfer becomes a card to flag inter-agent misalignment and rate quality.
- Per-agent and per-team scorecards: role fidelity, contribution, and coordination per agent, plus shared team dimensions and milestones.
- A tool-contention timeline that surfaces deadlocks and races where agents touch the same resource at once.
- Emergent-behavior tagging for collusion, groupthink, and cascading errors that span several agents and turns.
 Failure attribution: which agent, which step, and why
Failure attribution: which agent, which step, and why
The full set, with YAML for each, is in Multi-Agent Team Evaluation, and the deep dive Debugging Multi-Agent Failures walks each surface end to end. The guide How to Evaluate Multi-Agent Systems covers when to use which.
Beyond text: multimodal-agent evaluation
Agents now drive GUIs, watch video, and hold spoken conversations, and each needs a review surface a text widget cannot provide:
- GUI / computer-use trajectories: per-step screenshot and action, an action verdict, and a click-grounding marker that shows whether the click landed on the right element.
- Full-duplex voice timelines: a dual-track user/agent timeline with barge-in detection and turn-taking scoring.
- Video temporal grounding: mark gold event intervals with a live IoU against the model's predicted interval.
- Speech-transcript error tagging, interleaved multimodal reasoning with visual-hallucination flags, and document table-grid structure.
 Computer-use review: action correctness plus click grounding
Computer-use review: action correctness plus click grounding
Two deep dives walk these through: Evaluating Computer-Use Agents for GUI and OS agents, and Evaluating Voice and Video Agents for spoken, video, and document agents. The reference is Multimodal-Agent Evaluation, and the guide is Evaluating Computer-Use and Multimodal Agents.
Judges you can trust, and an arena
Using an LLM to grade outputs is routine; the 2.6.x work is about knowing how far to trust it. Judge calibration runs a blind human pass against the model labels and reports accuracy, kappa, and Expected Calibration Error. Judge alignment tunes a single judge against your gold labels. And programmatic evaluators score trajectories and text automatically (trajectory match, tool-use correctness, reference-free LLM-as-judge, and heuristics) without a server running.
For head-to-head comparison, the Model Arena sends one prompt to several models, collects preferences, and builds a win-rate leaderboard across OpenAI, Anthropic, Gemini, Ollama, and vLLM.
Treat evaluation like software
The operational pieces make evaluation repeatable:
- Datasets and experiments: versioned eval sets, splits, and side-by-side experiment comparison with regression deltas.
- CI evaluation: a pytest plugin that fails the build when a prompt or model change regresses agent quality past a threshold.
- Automation rules: route incoming production traces into datasets, evaluators, or the annotation queue by rule.
- Semantic curation: an embedding index for "find traces like this failure" and saved dynamic slices.
Getting it
pip install --upgrade potato-annotationEach new surface ships a runnable example under examples/agent-traces/, including interaction-graph/, failure-attribution/, gui-trajectory/, and temporal-grounding/. Point Potato at one to see the schema running:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000If you are weighing tools, the comparison in Potato vs LangSmith and Langfuse and the guide Open-Source Annotation Tools Compared lay out where each fits. Questions and trace formats we should support are welcome on the GitHub repository.