Evaluating Voice and Video Agents
A walkthrough of human evaluation for spoken, video, and document agents in Potato: scoring turn-taking on a dual-track timeline, grounding video events with live IoU, tagging speech errors, and marking table structure.
Agents that talk, watch video, and read documents fail in ways a text box cannot show. A voice agent's mistakes live at the seams between turns; a video agent's answer is a time interval, not a sentence; a document agent's error is a misread table cell. Each of these needs a review surface shaped to the modality. Potato adds four such surfaces — voice, video, speech, and document — alongside its existing image and audio displays. The full reference is Multimodal-Agent Evaluation.
 A plain text widget cannot express a barge-in, an event interval, or a table cell
A plain text widget cannot express a barge-in, an event interval, or a table cell
How do I evaluate a voice agent's turn-taking?
Spoken agents break at the boundaries: cutting the user off, talking over them, or pausing so long the user gives up. The voice_interaction schema lays the conversation out as a dual-track timeline — a user lane and an agent lane — and highlights the overlap regions where both speak at once (Full-Duplex-Bench, 2025). You classify each overlap and rate the overall turn-taking; the audio plays inline when provided.
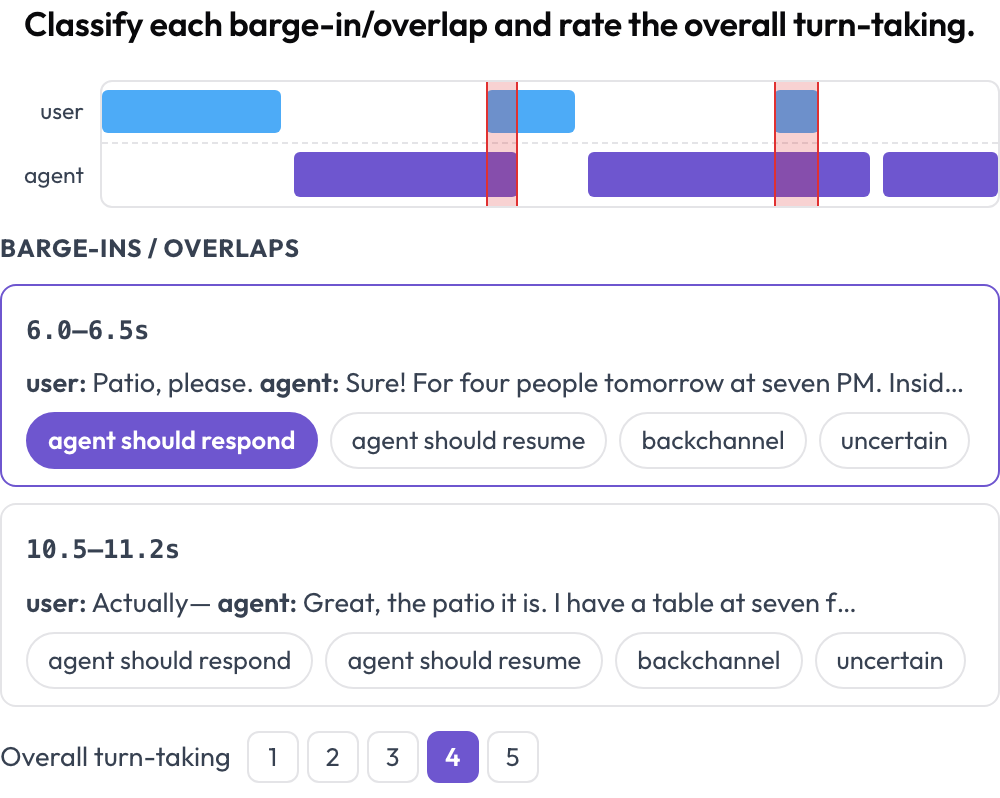 Dual-track voice timeline with barge-in detection and turn-taking scoring
Dual-track voice timeline with barge-in detection and turn-taking scoring
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5The overlaps are computed from the turn timings at render time, so a full-duplex conversation that a flat transcript would flatten into "they both said things" becomes a set of concrete, labelable moments.
How do I score a video agent's temporal grounding?
A video agent's answer to "when does the goal happen?" is an interval, so you score it as one. The temporal_grounding schema gives you a scrubber where you mark the gold [start, end] for each event prompt, by capturing the playhead or typing seconds. When the data carries the model's predicted interval, a live IoU and a two-bar mini-timeline update as you adjust (TimeScope, 2025).
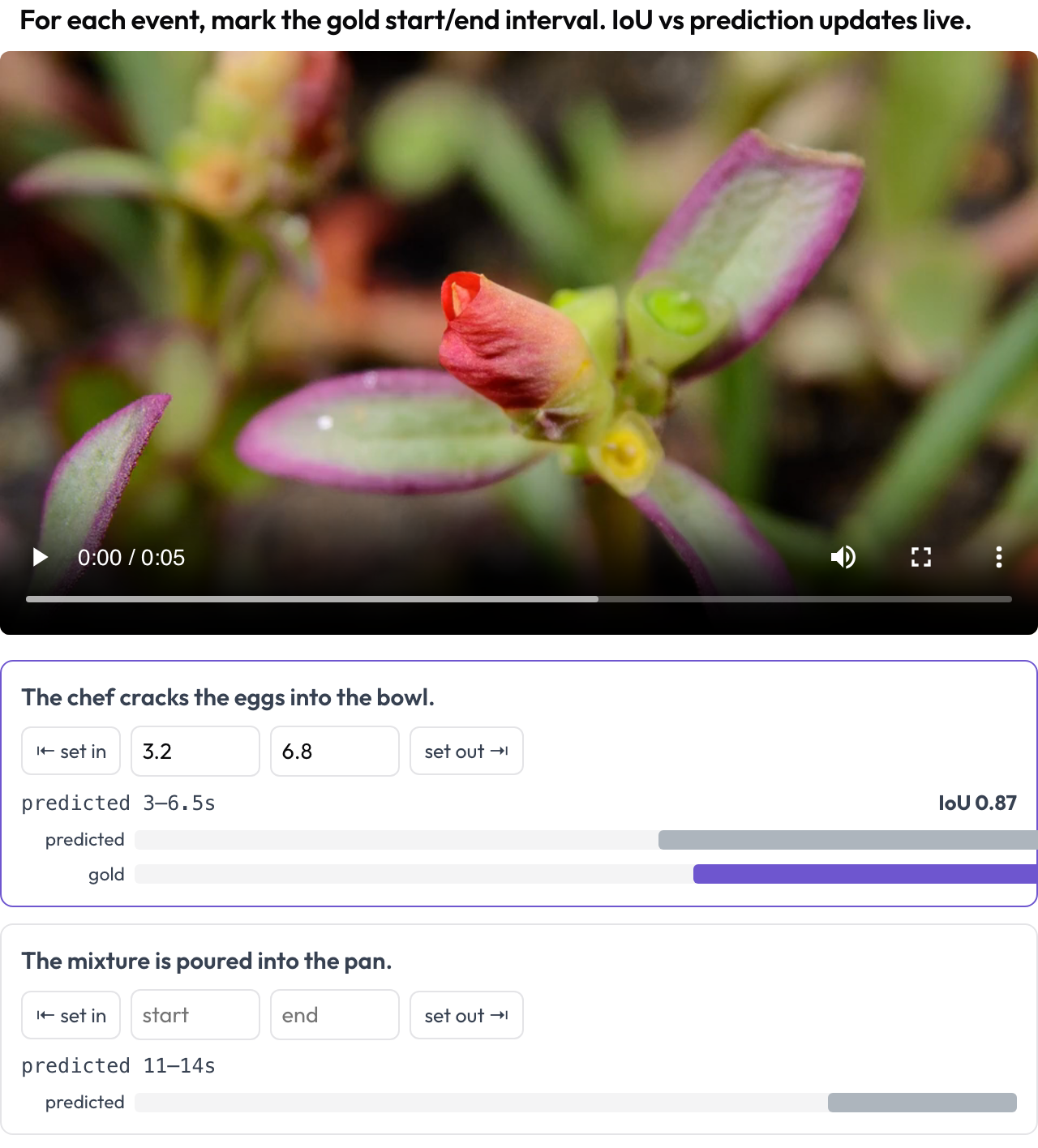 Mark gold event intervals on video with a live IoU vs. the model's prediction
Mark gold event intervals on video with a live IoU vs. the model's prediction
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsThis is built for predicted-versus-gold localization, which is a different job from general segment labeling: you are scoring how close the model's span is to the truth, and seeing the IoU move as you drag the boundary makes that immediate.
What about speech transcripts, reasoning, and tables?
Three more surfaces cover the rest of the multimodal spread:
- Speech transcripts (
speech_transcript): each time-aligned segment is a card; you tag ASR/TTS errors, mispronunciations, and disfluencies and correct the text inline (Speak & Improve, 2025). This is the segment-level complement to the turn-taking view. - Interleaved reasoning (
multimodal_reasoning): a text-image-tool trace rendered as typed blocks; you rate each step's coherence and flag visual hallucinations where the reasoning does not follow from the image (Multimodal RewardBench 2, 2025). - Document tables (
table_grid): you set the grid dimensions and click cells to mark their role — data, column header, row header, empty — capturing the structure that bounding boxes cannot.
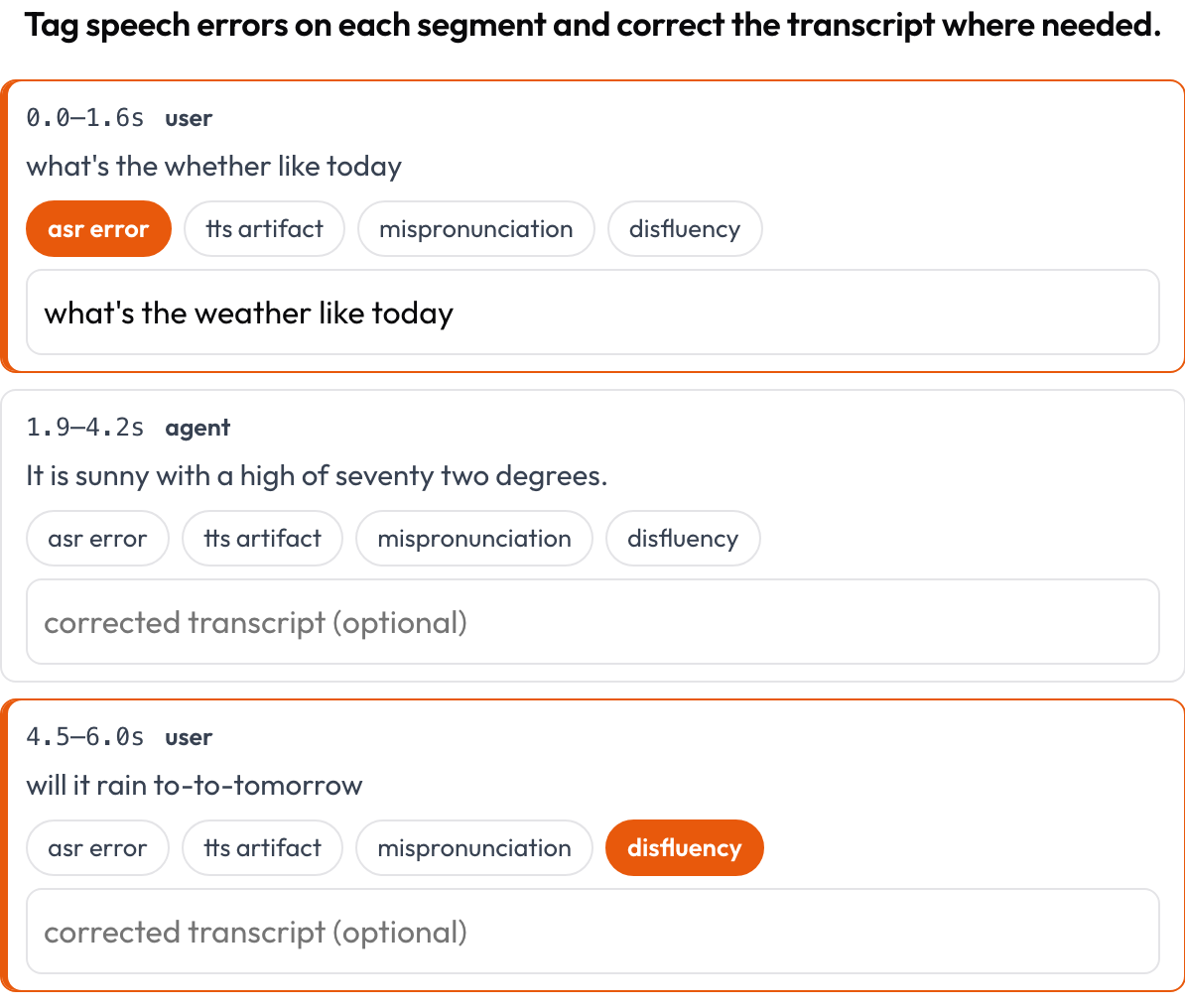 Tag ASR/TTS/pronunciation errors per segment and correct the transcript inline
Tag ASR/TTS/pronunciation errors per segment and correct the transcript inline
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true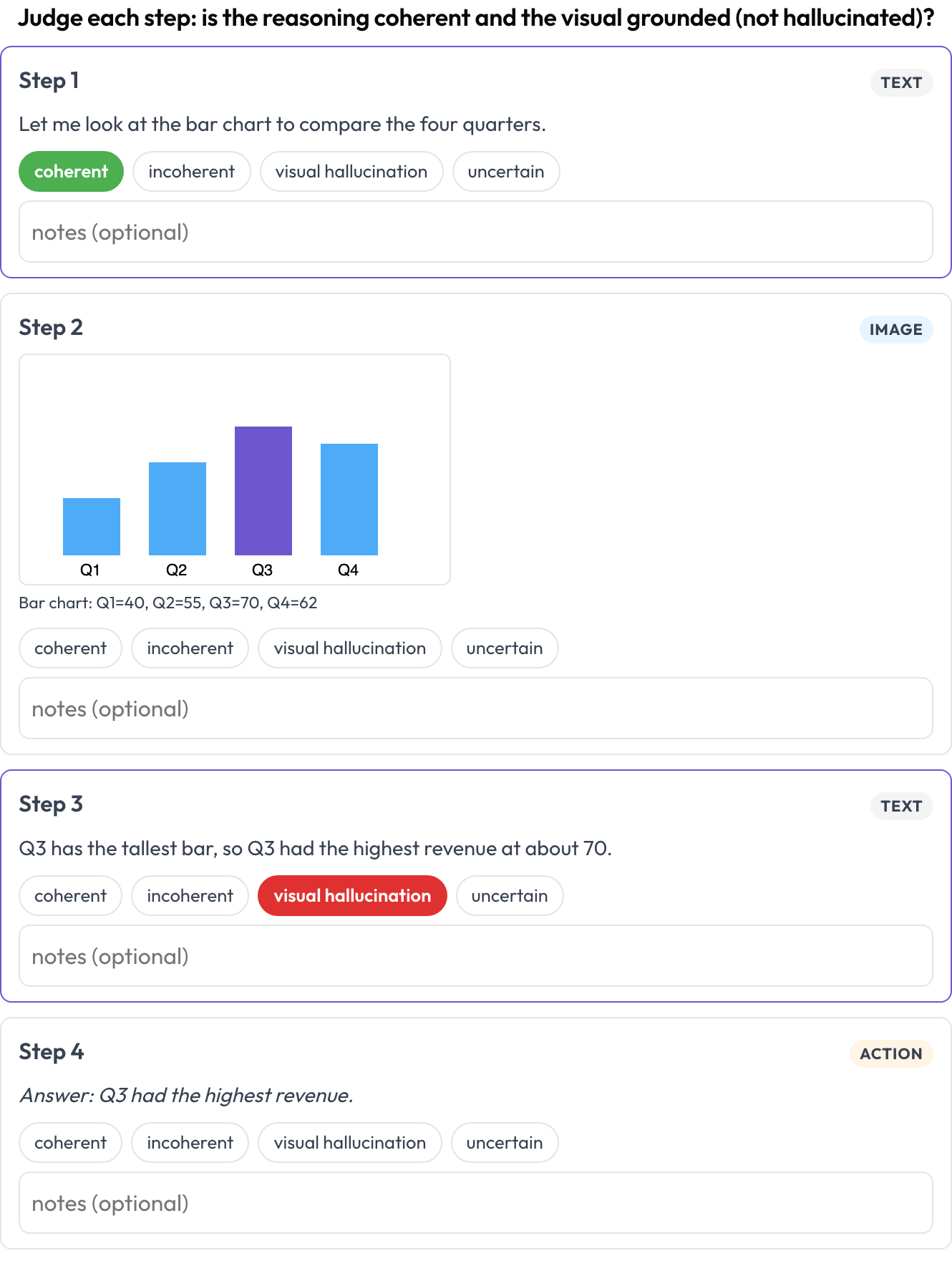 Rate each step of a text-image-tool reasoning trace for coherence and visual hallucination
Rate each step of a text-image-tool reasoning trace for coherence and visual hallucination
Several of these schemas can run on the same task, so a single document-agent run can be scored for table structure and reasoning coherence at once.
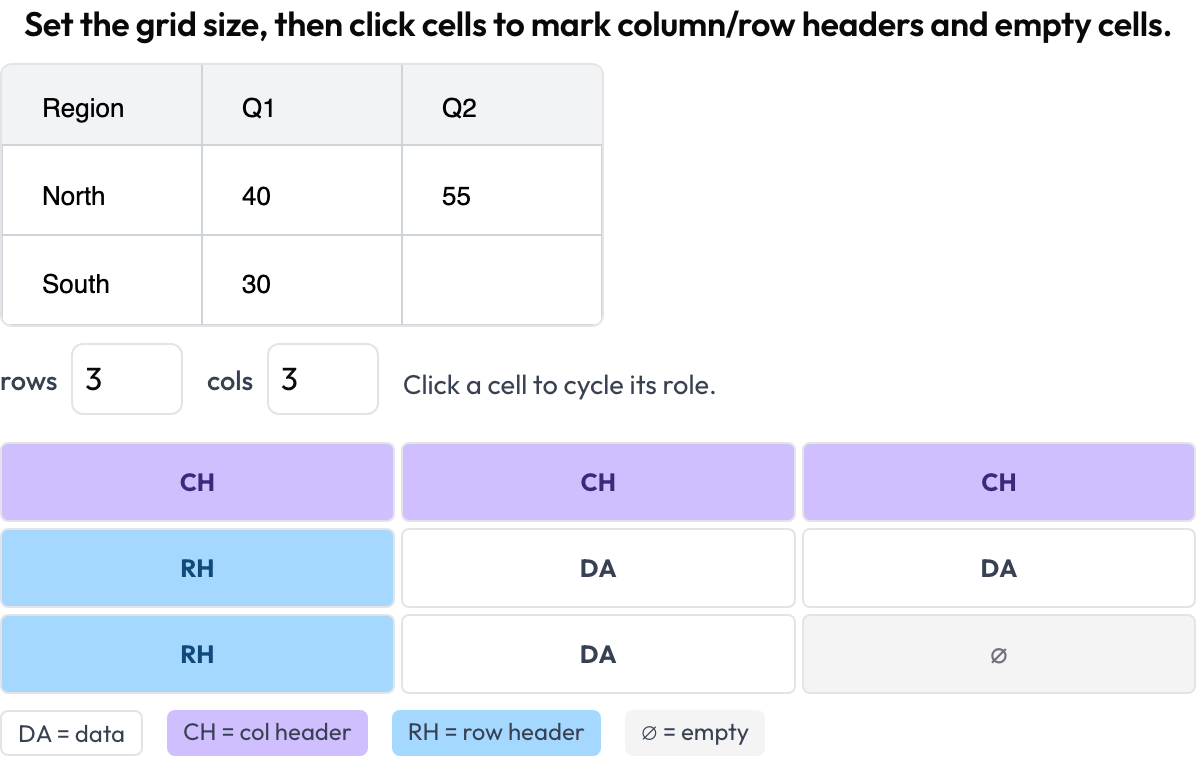 Annotate document-table cell structure: column and row headers, data, and empty cells
Annotate document-table cell structure: column and row headers, data, and empty cells
How do I set this up?
Each surface ships a runnable example under examples/agent-traces/:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000Your data drops in as turns, segments, or events with timestamps; the surface derives its timeline from them at render time. For GUI and OS agents, the companion piece is Evaluating Computer-Use Agents.
Further reading
- Multimodal-Agent Evaluation — the full schema reference
- Evaluating Computer-Use and Multimodal Agents — the guide, with a schema-selection table
- Evaluating Computer-Use Agents, Step by Step — the GUI and OS half of the multimodal surfaces
- Potato 2.6.2: A Complete Open-Source Agent-Evaluation Suite — everything in the 2.6.x line