Evaluating Computer-Use Agents, Step by Step
A walkthrough of human evaluation for computer-use and GUI agents in Potato: judging each action, checking click grounding on the screenshot, and reviewing tool calls one at a time.
A computer-use agent reads a screenshot, decides on an action, and clicks. Evaluating one means checking each step: was the action right, and did the click actually land on the element it named — not just whether the task eventually succeeded. Task success hides the click that hit the wrong button but advanced anyway, and the action that was right by luck. Potato reviews these runs with a purpose-built GUI-trajectory surface and a tool-call review, both configured in YAML.
A computer-use agent — also called a GUI or OS agent — sees the screen as pixels or a DOM and acts through the same controls a person has. Benchmarks like OSWorld, ScreenSpot, and AndroidWorld score task completion automatically. Automatic scoring is cheap and worth running, but it cannot tell you why a run failed, or catch the lucky pass. That is the gap human step review fills.
 Judge the action and whether the click landed on the element it named
Judge the action and whether the click landed on the element it named
What do you actually judge in a GUI trajectory?
Each step pairs a screenshot (what the agent saw) with an action (what it did). You judge the action, and when the step carries click coordinates, you check the grounding marker that Potato draws on the screenshot:
- Action correctness — correct, wrong element, wrong action, or hallucinated.
- Click grounding — did the coordinates land on the element the action named?
- Outcome — did the run finish the task, and at which step did it first go wrong?
 Review each step: action correctness plus click grounding on the screenshot
Review each step: action correctness plus click grounding on the screenshot
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot
action_key: action
coord_space: normalized
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Each step supplies screenshot, action, and optional x/y (or a nested click: {x, y}). The grounding marker is the part automated metrics miss most often: a model can output the right action label while clicking ten pixels off the target, and a pass/fail on the final screen will never surface it.
Why does the first wrong step matter more than the final result?
Because that step is what you would fix or train against. A run that fails at step 9 because step 3 misread a dialog is really a step-3 problem, and labeling it at step 9 teaches the wrong lesson. Catching the first divergence is the same idea behind process reward models: a signal at every step localizes the error instead of collapsing the whole trajectory into one number.
How do I review an agent's tool calls?
GUI agents also call tools and functions, and those fail in their own ways: right intent, wrong tool; right tool, malformed arguments; right call, wrong order. The tool_call_review schema pulls each call out of the trace and gives it a card with the tool name and pretty-printed arguments, so you judge them one at a time (mirroring BFCL v4 / MCPMark).
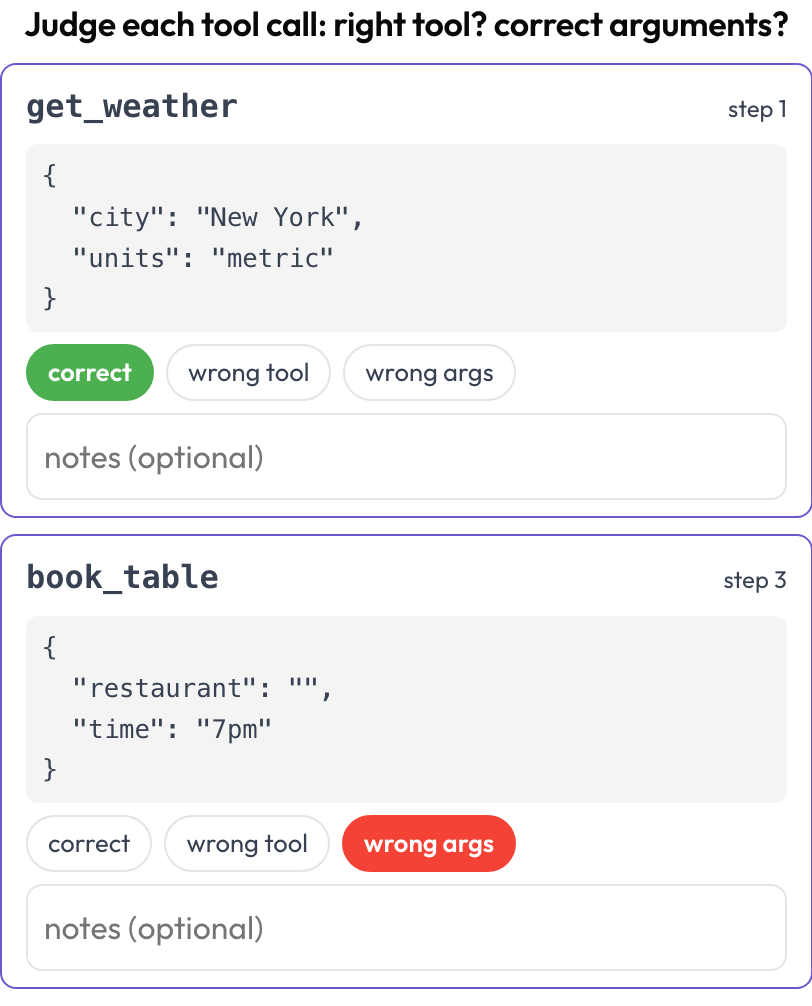 Judge every tool call: right tool, correct arguments, right order
Judge every tool call: right tool, correct arguments, right order
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order]Tool calls are extracted at render time from each step's tool_calls, tool_call, or action field, so a trajectory that mixes UI clicks and API calls can be reviewed on both axes in one task.
How do I set this up?
Each surface ships a runnable example under examples/agent-traces/. Point Potato at one to see the schema with sample data:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/gui-trajectory/config.yaml -p 8000Your own data drops in as a list of steps, each with a screenshot URL or data-URI and an action string. For broader web agents that work from rendered pages rather than raw screenshots, see Web-Agent Evaluation.
Further reading
- Multimodal-Agent Evaluation — the full schema reference for GUI, voice, video, and document agents
- Evaluating Computer-Use and Multimodal Agents — the guide, with a schema-selection table
- Evaluating Voice and Video Agents — the other half of the multimodal surfaces
- Potato 2.6.2: A Complete Open-Source Agent-Evaluation Suite — the full 2.6.x line