Potato 2.6.2: 완전한 오픈소스 에이전트 평가 제품군
2.6.x 라인은 Potato를 완전하고 무료인 에이전트 평가 플랫폼으로 만듭니다. OpenTelemetry, LangGraph, CrewAI, AutoGen에서의 트레이스 수집, 클릭 가능한 상호작용 그래프를 통한 멀티 에이전트 팀 어노테이션, GUI·음성·비디오를 위한 멀티모달 에이전트 스키마, 그리고 모델 아레나, CI 게이팅, 큐레이션까지 제공합니다.
Potato 2.6은 에이전트 평가의 첫 번째 물결을 가져왔습니다. LLM-as-judge 보정, 학습 데이터를 위한 트래젝토리 편집, 그리고 3분할 eval_trace 디스플레이가 그것입니다. 그 이후의 2.6.x 포인트 릴리스들이 나머지를 채웁니다. 2.6.2 기준으로 Potato는 완전한 에이전트 평가 플랫폼입니다. 직접 만든 에이전트에서 트레이스를 수집하고, 단일 에이전트·멀티 에이전트 팀·멀티모달 에이전트를 어노테이션하고, 신뢰할 수 있는 LLM으로 평가하고, 아레나에서 모델 순위를 매기고, CI에서 릴리스를 게이팅할 수 있습니다. 이 모든 것이 YAML로 구성되며 여러분 자신의 서버에 머무릅니다.
 Potato 멀티 에이전트 평가
Potato 멀티 에이전트 평가
이들 중 대부분은 현재 사람들이 호스팅형 플랫폼에 비용을 지불하고 얻는 기능입니다. Potato는 이를 무료로, 자체 호스팅 방식으로 제공합니다. 다음은 2.6.x 라인 전반에 걸쳐 출시된 내용입니다.
 처음부터 끝까지 이어지는 2.6.x 에이전트 평가 제품군
처음부터 끝까지 이어지는 2.6.x 에이전트 평가 제품군
트레이스 가져오기: 캡처 SDK와 개방형 표준
평가는 실제 실행에서 시작됩니다. 새로운 potato_trace SDK는 어떤 에이전트든 계측합니다. 함수에 @traceable(동기 또는 비동기)을 데코레이트하면 중첩된 호출이 캡처되어 Potato의 수집 엔드포인트로 전송되며, 선택적으로 OpenTelemetry로 내보낼 수도 있습니다. Potato는 또한 OpenTelemetry / OpenInference 스팬과 LangGraph, CrewAI, AutoGen 실행 포맷을 수집하므로, 여러분이 이미 사용 중인 프레임워크의 트레이스가 별도의 글루 코드 없이 어노테이션 큐에 들어옵니다. 새 트레이스는 웹훅, 폴러, 또는 감시 디렉터리를 통해 도착할 수 있으며, 도착하는 즉시 어노테이터에게 할당될 수 있습니다.
팀 전체 보기: 멀티 에이전트 평가
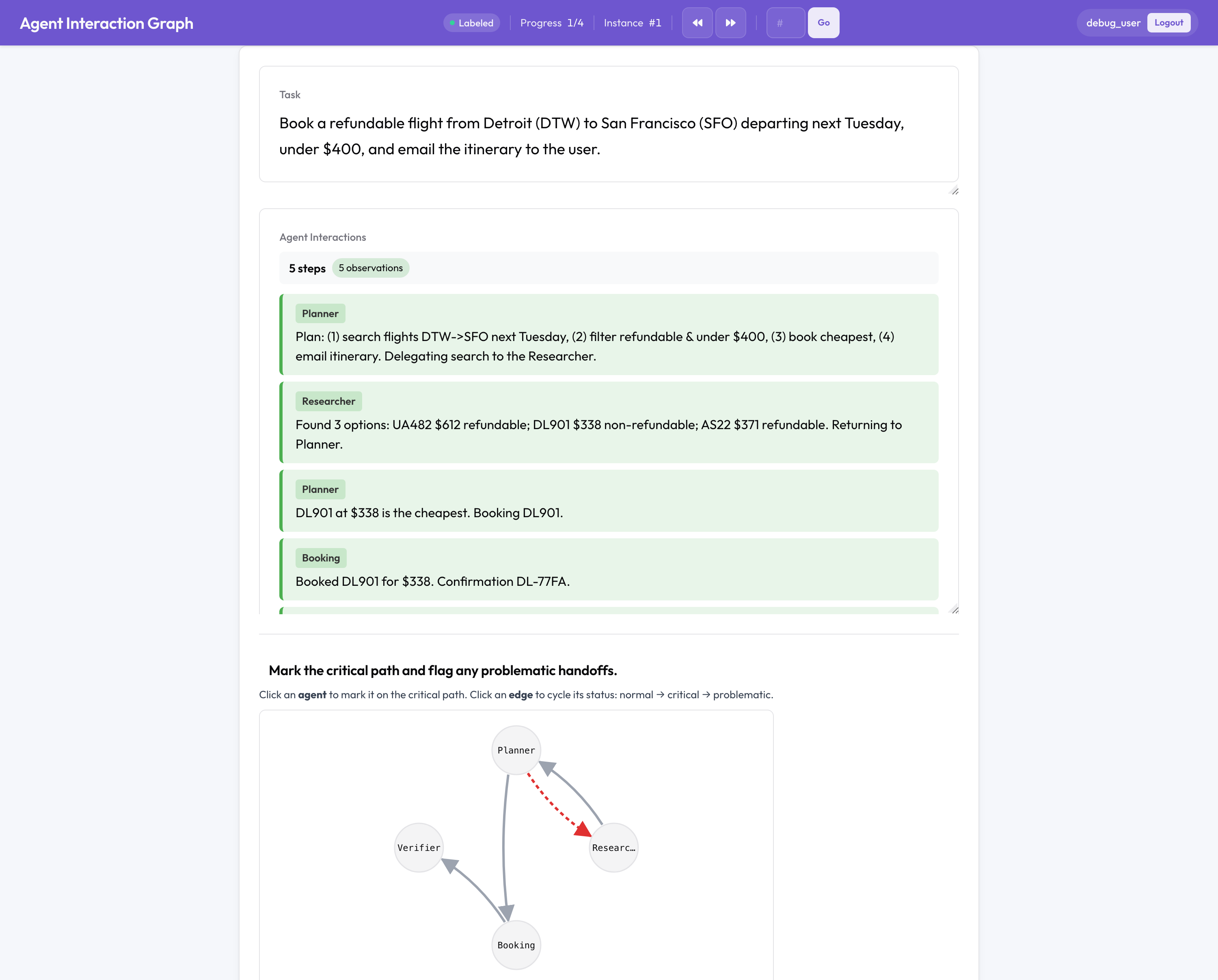
이것이 오픈소스에 동등한 것이 없는 부분입니다. 멀티 에이전트 실행은 단일 에이전트와는 다르게 실패합니다. 에이전트들 사이에서, 핸드오프에서, 팀이 어떻게 조직되었는지에서 실패하므로, Potato는 평평한 대화록이 아니라 팀 구조를 어노테이션합니다.
- 에이전트와 핸드오프의 클릭 가능한 상호작용 그래프. 여기서 임계 경로를 표시하고 문제가 있는 엣지를 플래그합니다.
- 실패 귀인: 책임 에이전트, 결정적 단계, 그리고 이유를 선택합니다. Who&When 귀인 연구에서 나온 (에이전트, 단계, 이유) 트리플입니다.
- 핸드오프 검토: 모든 제어 이전이 카드가 되어 에이전트 간 불일치를 플래그하고 품질을 평가합니다.
- 에이전트별 및 팀별 스코어카드: 에이전트마다 역할 충실도, 기여도, 협업, 그리고 공유 팀 차원과 마일스톤.
- 에이전트들이 동일한 리소스를 동시에 건드리는 교착 상태와 경합을 드러내는 도구 경합 타임라인.
- 여러 에이전트와 턴에 걸친 결탁, 집단사고, 연쇄 오류를 위한 창발 행동 태깅.
 실패 귀인: 어느 에이전트, 어느 단계, 그리고 왜
실패 귀인: 어느 에이전트, 어느 단계, 그리고 왜
각각에 대한 YAML을 포함한 전체 집합은 멀티 에이전트 팀 평가에 있으며, 심층 분석인 멀티 에이전트 실패 디버깅이 각 표면을 처음부터 끝까지 다룹니다. 가이드 멀티 에이전트 시스템 평가 방법은 언제 어느 것을 사용할지를 다룹니다.
텍스트를 넘어서: 멀티모달 에이전트 평가
이제 에이전트는 GUI를 조작하고, 비디오를 시청하고, 음성 대화를 나눕니다. 그리고 각각은 텍스트 위젯이 제공할 수 없는 검토 표면을 필요로 합니다.
- GUI / 컴퓨터 사용 트래젝토리: 단계별 스크린샷과 동작, 동작 판정, 그리고 클릭이 올바른 요소에 떨어졌는지를 보여주는 클릭 그라운딩 마커.
- 풀 듀플렉스 음성 타임라인: 끼어들기 감지와 턴테이킹 점수를 포함한 사용자/에이전트 듀얼 트랙 타임라인.
- 비디오 시간적 그라운딩: 모델이 예측한 구간과의 실시간 IoU와 함께 골드 이벤트 구간을 표시합니다.
- 음성 전사 오류 태깅, 시각적 환각 플래그가 있는 인터리브된 멀티모달 추론, 그리고 문서 표 그리드 구조.
 컴퓨터 사용 검토: 동작 정확성과 클릭 그라운딩
컴퓨터 사용 검토: 동작 정확성과 클릭 그라운딩
두 가지 심층 분석이 이를 살펴봅니다. GUI 및 OS 에이전트를 위한 컴퓨터 사용 에이전트 평가, 그리고 음성·비디오·문서 에이전트를 위한 음성 및 비디오 에이전트 평가입니다. 레퍼런스는 멀티모달 에이전트 평가이고, 가이드는 컴퓨터 사용 및 멀티모달 에이전트 평가입니다.
신뢰할 수 있는 심판, 그리고 아레나
LLM으로 출력을 채점하는 것은 일상적입니다. 2.6.x 작업은 그것을 어디까지 신뢰할지 아는 것에 관한 것입니다. 심판 보정은 모델 라벨에 대해 블라인드 휴먼 패스를 실행하고 정확도, 카파, 그리고 기대 보정 오차(ECE)를 보고합니다. 심판 정렬은 단일 심판을 여러분의 골드 라벨에 맞춰 튜닝합니다. 그리고 프로그래밍 방식 평가기는 서버를 실행하지 않고도 트래젝토리와 텍스트를 자동으로 채점합니다(트래젝토리 일치, 도구 사용 정확성, 레퍼런스 없는 LLM-as-judge, 그리고 휴리스틱).
정면 비교를 위해 모델 아레나는 하나의 프롬프트를 여러 모델에 보내고, 선호도를 수집하고, OpenAI, Anthropic, Gemini, Ollama, vLLM 전반에 걸친 승률 리더보드를 구축합니다.
평가를 소프트웨어처럼 다루기
운영적 요소들은 평가를 반복 가능하게 만듭니다.
- 데이터셋과 실험: 버전 관리된 평가 세트, 분할, 그리고 회귀 델타를 포함한 나란한 실험 비교.
- CI 평가: 프롬프트나 모델 변경이 에이전트 품질을 임계값 이상으로 회귀시키면 빌드를 실패시키는 pytest 플러그인.
- 자동화 규칙: 들어오는 프로덕션 트레이스를 규칙에 따라 데이터셋, 평가기, 또는 어노테이션 큐로 라우팅.
- 의미 기반 큐레이션: "이 실패와 유사한 트레이스 찾기"를 위한 임베딩 인덱스와 저장된 동적 슬라이스.
받는 방법
pip install --upgrade potato-annotation각각의 새로운 표면은 examples/agent-traces/ 아래에 실행 가능한 예제를 제공하며, 여기에는 interaction-graph/, failure-attribution/, gui-trajectory/, temporal-grounding/이 포함됩니다. 스키마가 실행되는 모습을 보려면 Potato를 그중 하나로 가리키세요.
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000도구를 저울질하고 있다면, Potato vs LangSmith와 Langfuse의 비교와 가이드 오픈소스 어노테이션 도구 비교가 각각이 어디에 적합한지를 설명합니다. 질문과 우리가 지원해야 할 트레이스 포맷은 GitHub 저장소에서 언제든 환영합니다.