멀티 에이전트 실패 디버깅: 단계별 안내
Potato로 멀티 에이전트 LLM 시스템이 왜 실패했는지 찾는 방법: 상호작용 그래프, 실패 귀인, 핸드오프 검토, 에이전트별 스코어카드, 도구 경합 타임라인, 그리고 창발 행동 태깅.
에이전트 팀이 실패할 때 어려운 부분은 실패를 알아차리는 것이 아니라, 어느 에이전트가 어느 단계에서 그것을 일으켰는지, 그리고 진짜 문제가 각자 따로 보면 멀쩡했던 두 에이전트 사이의 잘못된 핸드오프였는지를 찾아내는 것입니다. 이 안내서는 바로 그것을 위해 만들어진 여섯 가지 Potato 표면을, 실제로 망가진 실행에서 사용하게 될 순서대로 살펴봅니다. 여기 있는 모든 것은 YAML로 구성되며 여러분 자신의 서버에서 실행됩니다. 전체 스키마 레퍼런스는 멀티 에이전트 팀 평가입니다.
멀티 에이전트 시스템은 서로 다른 역할(플래너, 코더, 리뷰어)을 가진 여러 LLM 에이전트가 메시지를 주고받고 제어를 넘기는 시스템입니다. 이러한 시스템이 왜 망가지는지에 관한 연구인 MAST 분류 체계(Why Do Multi-Agent LLM Systems Fail?)는 대부분의 실패가 에이전트 간에서 일어난다는 것을 발견했습니다. 핸드오프에서 떨어뜨린 제약 조건, 자기 작업을 결코 검증하지 않는 팀, 서로 엇갈려 말하는 에이전트들이 그것입니다. 평평한 채팅 대화록은 바로 그런 것들을 가립니다. 잘못된 것이 두 메시지 사이의 공간에 살아 있고, 어느 한쪽 메시지 안에 있지 않기 때문입니다.
 실패는 에이전트 사이, 핸드오프에 있으며 하나의 대화록 안에 있지 않다
실패는 에이전트 사이, 핸드오프에 있으며 하나의 대화록 안에 있지 않다
멀티 에이전트 실행의 구조를 어떻게 보나요?
텍스트가 아니라 실행의 형태에서 시작하세요. agent_interaction_graph 스키마는 전체 실행을 방향 그래프로 렌더링합니다. 노드는 에이전트, 엣지는 그들 사이의 핸드오프이며, 더 굵은 엣지는 더 많은 트래픽을 의미합니다. 노드를 클릭하면 임계 경로에 표시하고, 엣지를 클릭하면 정상에서 임계, 그리고 문제 있음으로 순환시킵니다.
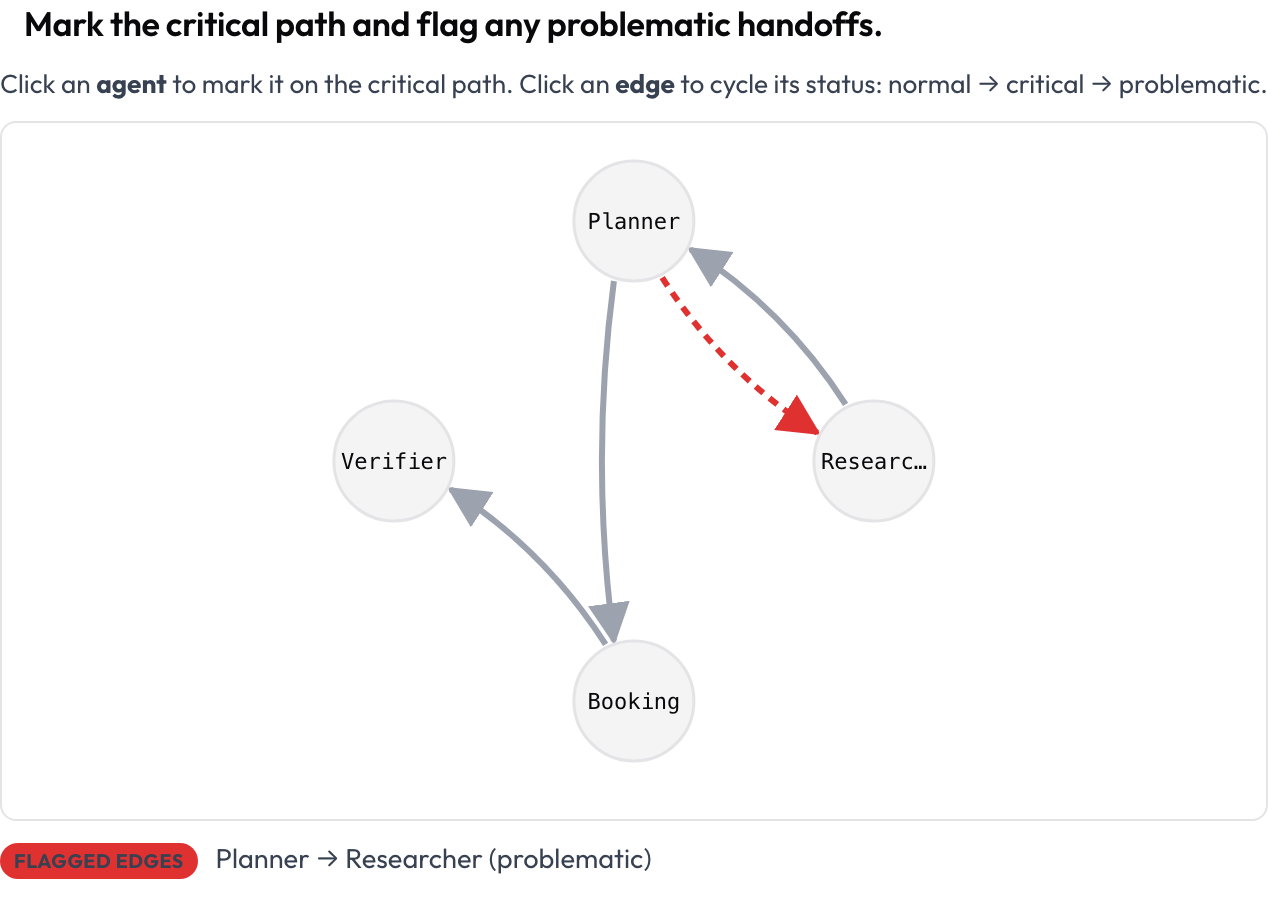 임계 경로를 표시하고 문제가 있는 핸드오프를 플래그하기
임계 경로를 표시하고 문제가 있는 핸드오프를 플래그하기
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agent그래프는 트레이스로부터 자동으로 배치되므로 아무것도 그릴 필요가 없습니다. 모든 노드와 엣지는 키보드 포커스가 가능하며, 텍스트 요약이 임계 노드와 플래그된 엣지를 나열하므로 의미가 결코 색상에만 의존하지 않습니다. 이 뷰는 "무엇이 무엇과 대화했고, 경로가 어디서 어긋났는가"에 답하는 가장 빠른 방법입니다.
멀티 에이전트 실패를 어떻게 하나의 에이전트에 귀인하나요?
실행을 볼 수 있게 되면, 실패를 못 박아 두세요. failure_attribution 스키마는 실패 귀인 문헌(Zhang 외, Which Agent Causes Task Failures and When?, ICML 2025, Who&When 데이터셋)에서 나온 트리플을 요청합니다. 책임 에이전트, 결정적 단계, 그리고 이유입니다. 에이전트 드롭다운과 단계 선택기는 트레이스 자체의 턴에서 채워지므로, 실제로 일어난 에이전트와 단계에만 실패를 귀인할 수 있습니다.
 책임 에이전트, 결정적 단계, 그리고 이유로 실패를 귀인하기
책임 에이전트, 결정적 단계, 그리고 이유로 실패를 귀인하기
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agent귀인을 성공/실패 라디오와 짝지으면 트리플이 실패한 실행에서만 수집되므로, 어노테이터의 시간이 신호를 담은 사례에 집중됩니다.
핸드오프 자체는요?
귀인은 하나의 결정적 단계를 지목합니다. 핸드오프 검토는 모든 제어 이전을 살펴봅니다. 연속된 턴 사이에서 행동하는 에이전트가 바뀌는 곳마다 Potato는 핸드오프 카드 A → B를 내보내며, 여러분은 그 이전에서 무엇이 잘못되었는지(정보 손실, 떨어뜨린 제약 조건, 왜곡, 목표 표류)를 플래그하고 품질을 평가합니다. 실패 유형은 MAST의 에이전트 간 범주와 "에코잉" 현상(Zhang 외, 2025)에서 나옵니다.
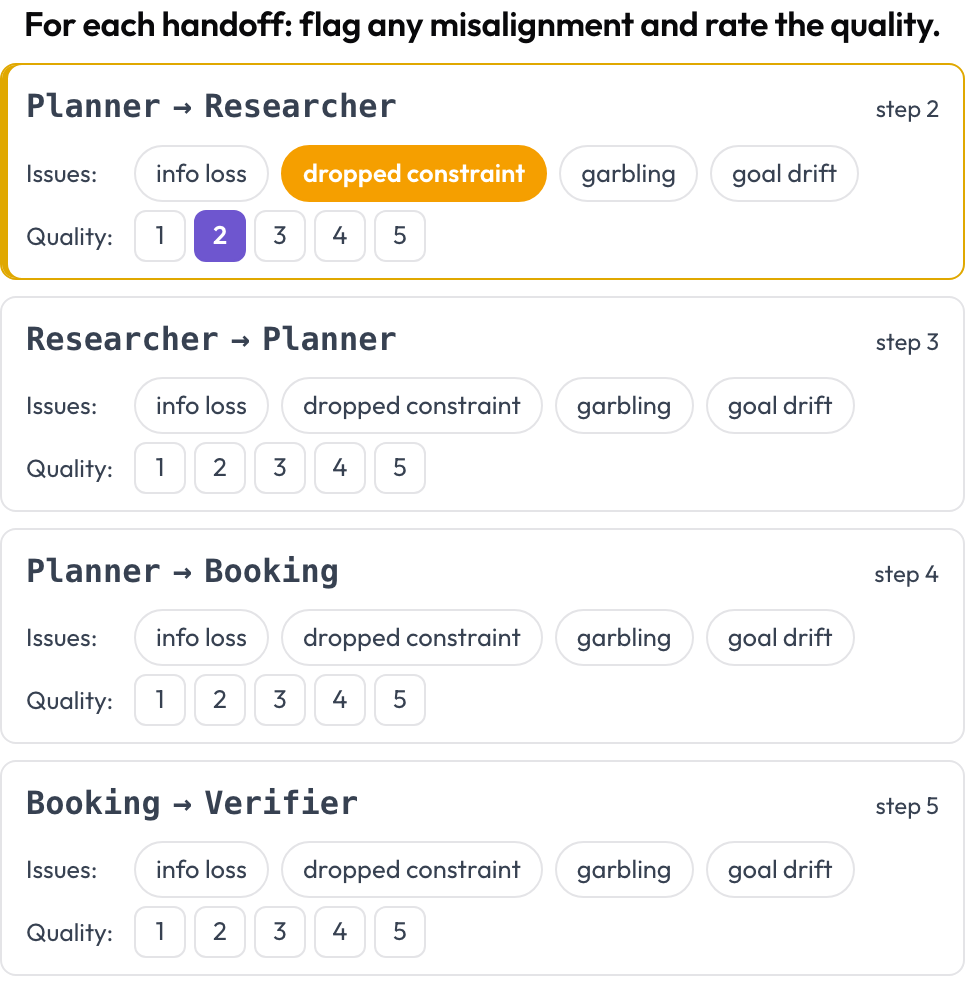 모든 핸드오프에서 에이전트 간 불일치를 플래그하고 품질을 평가하기
모든 핸드오프에서 에이전트 간 불일치를 플래그하고 품질을 평가하기
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5핸드오프는 렌더링 시점에 도출되므로 수동 설정이 없습니다. 보통 여기서 "각 에이전트는 멀쩡해 보였는데 팀은 여전히 실패했다"는 사례가 해소됩니다. 제약 조건이 에이전트 A에서는 살아 있었고 에이전트 B에 이르러서는 사라진 것입니다.
에이전트와 팀을 어떻게 점수 매기나요?
실패는 한 번에 무엇이 망가졌는지 알려줍니다. 스코어카드는 여러 실행에 걸쳐 설계가 좋은지를 알려줍니다. agent_scorecard 스키마는 두 수준을 동시에 점수 매깁니다(MultiAgentBench, Zhou 외, ACL 2025). 각 에이전트를 역할 충실도, 기여도, 협업으로, 그리고 팀을 자체 공유 차원으로, 선택적 마일스톤과 함께 점수 매깁니다. 에이전트 행은 트레이스에서 나오므로, 행렬이 실제로 참여한 주체와 일치합니다.
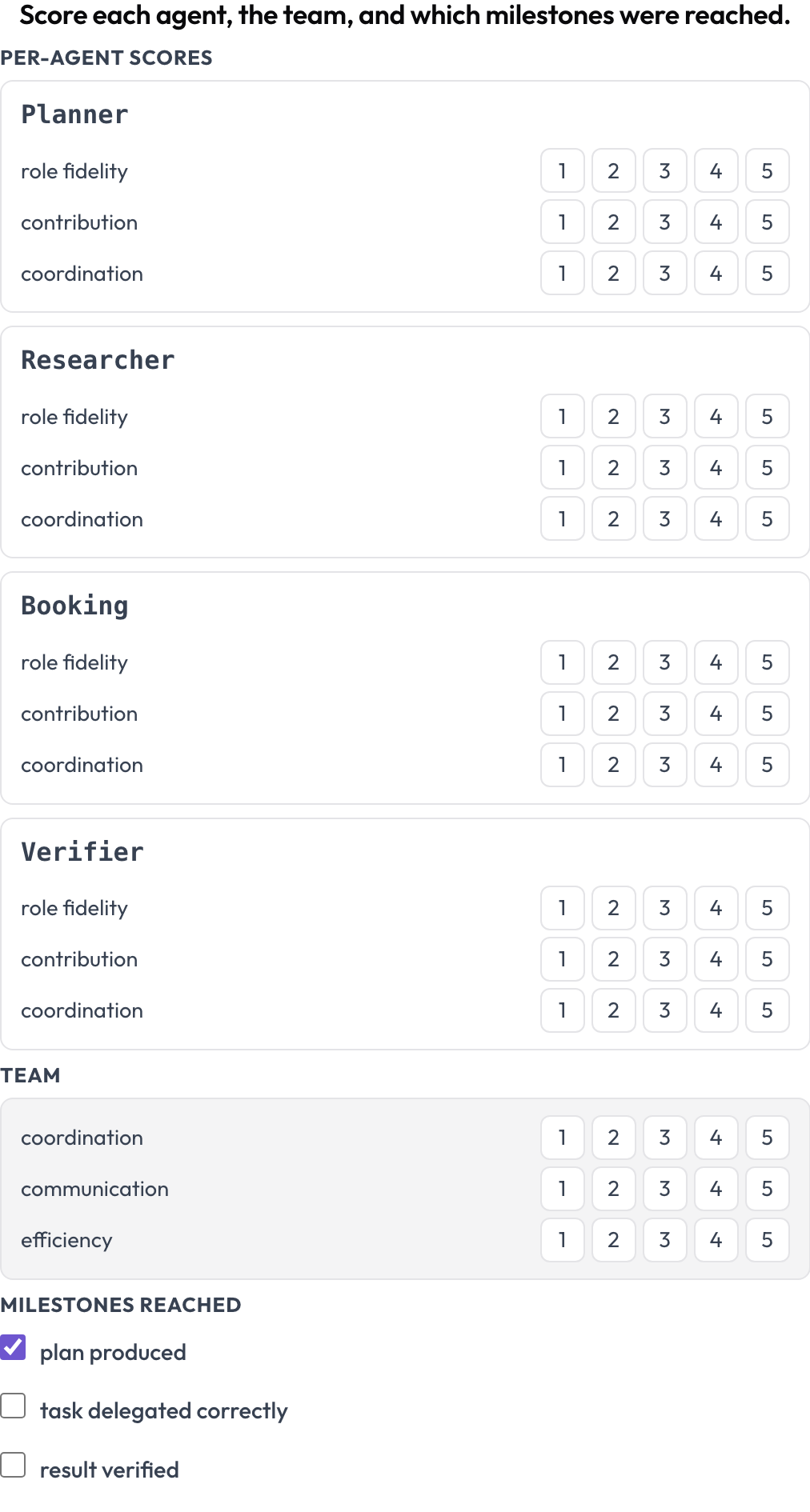 각 에이전트를 역할 충실도, 기여도, 협업으로 점수 매기고, 팀도 함께 점수 매기기
각 에이전트를 역할 충실도, 기여도, 협업으로 점수 매기고, 팀도 함께 점수 매기기
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]협업이 잘 안 되는 팀 안에 갇힌 강한 에이전트는 여기서 높은 에이전트 행 옆에 낮은 팀 차원으로 나타납니다. 같은 작업에서 순차형, 계층형, 그룹 채팅형 오케스트레이션을 비교할 때 여러분이 원하는 패턴이 바로 이것입니다.
동시성과 집단적 실패는요?
두 가지 표면이 턴별 읽기로는 잡을 수 없는 실패를 더 잡아냅니다. tool_contention 타임라인은 각 에이전트를 자체 레인에 놓고, 두 호출이 동일한 리소스를 겹치는 시간에 건드리는 영역을 강조합니다. 여러분은 이를 교착, 순환 대기, 경쟁 상태, 또는 무해함으로 분류합니다(DPBench, 2026).
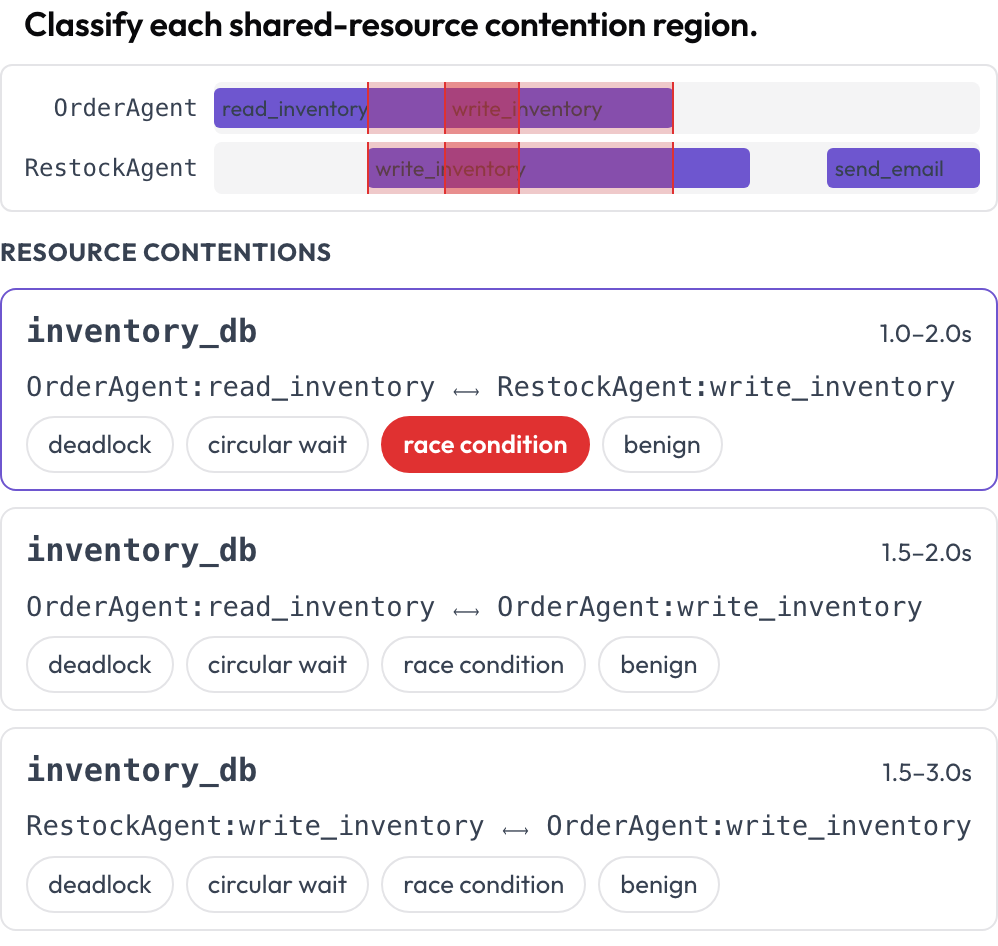 에이전트별 도구 호출 타임라인에서 교착과 경쟁 상태를 포착하기
에이전트별 도구 호출 타임라인에서 교착과 경쟁 상태를 포착하기
그리고 emergent_behavior는 하나의 단계에 위치하지 않고 집단적인 실패(결탁, 집단사고, 연쇄 오류, 역할 표류)를 다룹니다. 창발 행동은 연속된 구간이 아니라, 어쩌면 서로 다른 에이전트에서 나온, 참여하는 턴들의 집합입니다. 그래서 참여하는 턴을 체크하고 메모를 추가합니다.
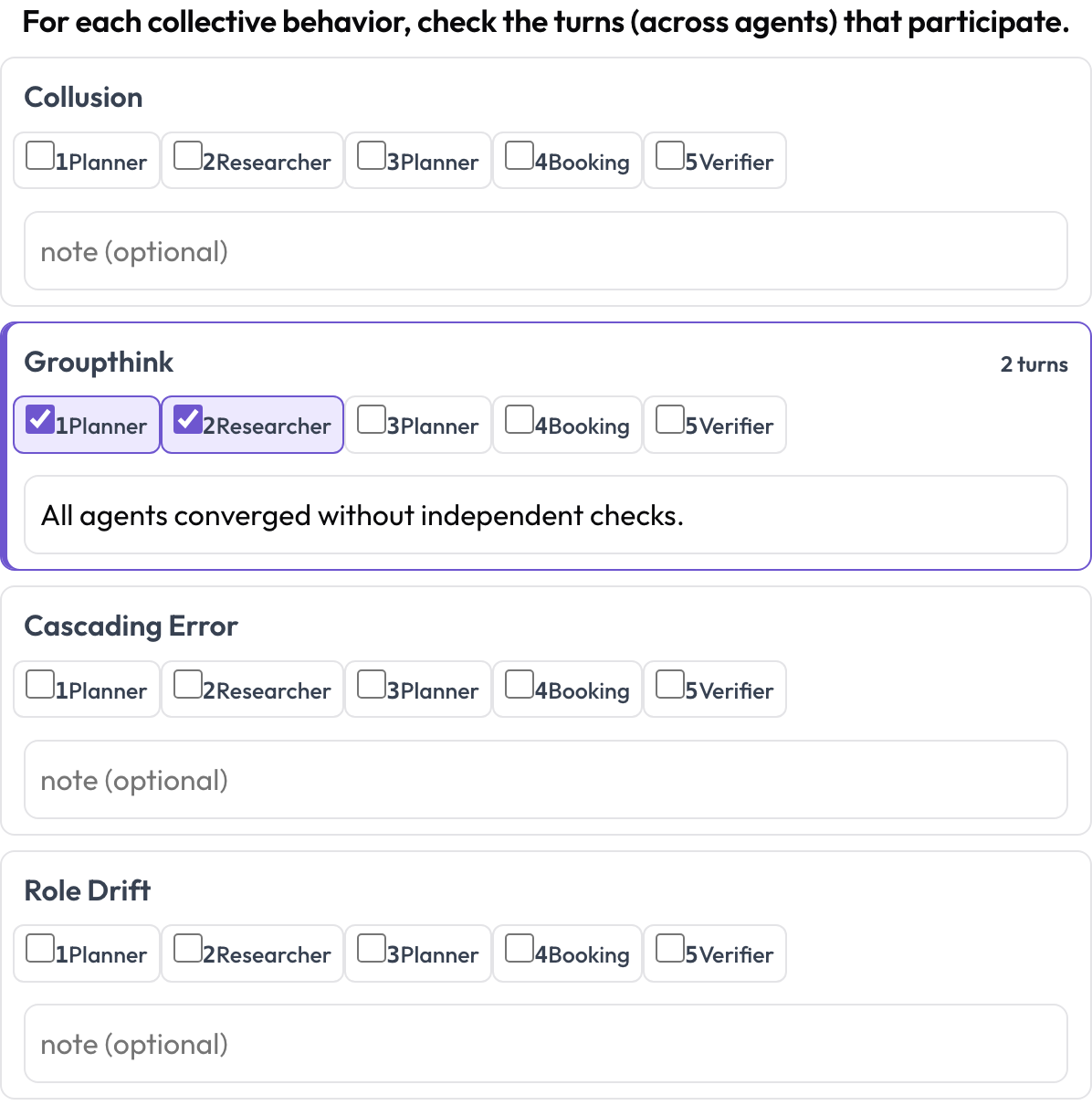 에이전트와 턴에 걸친 결탁, 집단사고, 연쇄 오류를 태깅하기
에이전트와 턴에 걸친 결탁, 집단사고, 연쇄 오류를 태깅하기
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: true순서대로 놓기
실제로 망가진 실행에서 순서는 보통 이렇습니다. 상호작용 그래프를 읽어 형태를 보고, 실패 귀인을 사용해 결정적 단계를 지목하고, 결정적 단계가 이전이었다면 핸드오프 검토를 열고, 실패가 타이밍이나 집단에 관한 것이고 하나의 에이전트에 관한 것이 아니라면 경합 타임라인이나 창발 행동 태깅을 꺼내 듭니다. 하나의 실행을 디버깅하는 것이 아니라 설계를 비교하게 되면 스코어카드로 점수를 매깁니다. 귀인에 대한 합의는 다른 주관적 라벨과 마찬가지로 측정하세요. 어노테이터 간 일치도를 참고하십시오.
더 읽을거리
- 멀티 에이전트 팀 평가 — 각 표면에 대한 YAML을 포함한 전체 스키마 레퍼런스
- 멀티 에이전트 시스템 평가 방법 — 언제 어느 방법을 쓸지에 대한 결정 가이드
- Potato 2.6.2: 완전한 오픈소스 에이전트 평가 제품군 — 2.6.x 라인 전반에 걸쳐 출시된 모든 것
- 에이전트 트래젝토리 어노테이션 — 단계 단위의 MAST 태깅을 포함한 단계별 오류 분류 체계