컴퓨터 사용 에이전트 평가, 단계별로
Potato에서 컴퓨터 사용 및 GUI 에이전트에 대한 휴먼 평가 안내: 각 동작 판정하기, 스크린샷에서 클릭 그라운딩 확인하기, 그리고 도구 호출을 하나씩 검토하기.
컴퓨터 사용 에이전트는 스크린샷을 읽고, 동작을 결정하고, 클릭합니다. 하나를 평가한다는 것은 각 단계를 확인하는 것입니다. 동작이 옳았는가, 그리고 클릭이 그것이 지목한 요소에 실제로 떨어졌는가입니다. 단지 작업이 결국 성공했는지가 아닙니다. 작업 성공은 잘못된 버튼을 눌렀지만 어쨌든 진행된 클릭과, 운으로 옳았던 동작을 숨깁니다. Potato는 이러한 실행을 목적에 맞게 만들어진 GUI 트래젝토리 표면과 도구 호출 검토로 검토하며, 둘 다 YAML로 구성됩니다.
컴퓨터 사용 에이전트는 GUI 또는 OS 에이전트라고도 불리며, 화면을 픽셀이나 DOM으로 보고 사람이 가진 것과 동일한 컨트롤을 통해 동작합니다. OSWorld, ScreenSpot, AndroidWorld 같은 벤치마크는 작업 완료를 자동으로 점수 매깁니다. 자동 점수는 저렴하고 실행할 가치가 있지만, 실행이 왜 실패했는지 알려줄 수도, 운 좋은 통과를 잡아낼 수도 없습니다. 그것이 휴먼 단계 검토가 채우는 간극입니다.
 동작과 클릭이 그것이 지목한 요소에 떨어졌는지를 판정하기
동작과 클릭이 그것이 지목한 요소에 떨어졌는지를 판정하기
GUI 트래젝토리에서 실제로 무엇을 판정하나요?
각 단계는 스크린샷(에이전트가 본 것)과 동작(에이전트가 한 것)을 짝짓습니다. 여러분은 동작을 판정하고, 단계가 클릭 좌표를 담고 있을 때 Potato가 스크린샷 위에 그리는 그라운딩 마커를 확인합니다.
- 동작 정확성 — 옳음, 잘못된 요소, 잘못된 동작, 또는 환각.
- 클릭 그라운딩 — 좌표가 동작이 지목한 요소에 떨어졌는가?
- 결과 — 실행이 작업을 완료했는가, 그리고 어느 단계에서 처음으로 잘못되었는가?
 각 단계 검토하기: 스크린샷 위에서 동작 정확성과 클릭 그라운딩
각 단계 검토하기: 스크린샷 위에서 동작 정확성과 클릭 그라운딩
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot
action_key: action
coord_space: normalized
verdict_options: [correct, wrong_element, wrong_action, hallucinated]각 단계는 screenshot, action, 그리고 선택적인 x/y(또는 중첩된 click: {x, y})를 제공합니다. 그라운딩 마커는 자동화 지표가 가장 자주 놓치는 부분입니다. 모델은 올바른 동작 라벨을 출력하면서도 타깃에서 10픽셀 벗어난 곳을 클릭할 수 있는데, 최종 화면에 대한 통과/실패는 그것을 결코 드러내지 못합니다.
왜 첫 번째 잘못된 단계가 최종 결과보다 더 중요한가요?
그 단계가 여러분이 고치거나 학습 대상으로 삼을 부분이기 때문입니다. 3단계에서 대화상자를 잘못 읽었기 때문에 9단계에서 실패한 실행은 실은 3단계 문제이며, 그것을 9단계에서 라벨링하면 잘못된 교훈을 가르치게 됩니다. 첫 번째 분기를 포착하는 것은 프로세스 보상 모델의 동일한 발상입니다. 모든 단계에서의 신호가 전체 트래젝토리를 하나의 숫자로 뭉개는 대신 오류를 국소화합니다.
에이전트의 도구 호출을 어떻게 검토하나요?
GUI 에이전트는 도구와 함수도 호출하며, 그것들은 자기 나름의 방식으로 실패합니다. 의도는 옳지만 잘못된 도구, 옳은 도구지만 잘못된 인수, 옳은 호출이지만 잘못된 순서입니다. tool_call_review 스키마는 각 호출을 트레이스에서 끌어내어 도구 이름과 보기 좋게 출력된 인수가 있는 카드를 부여하므로, 하나씩 판정할 수 있습니다(BFCL v4 / MCPMark을 반영).
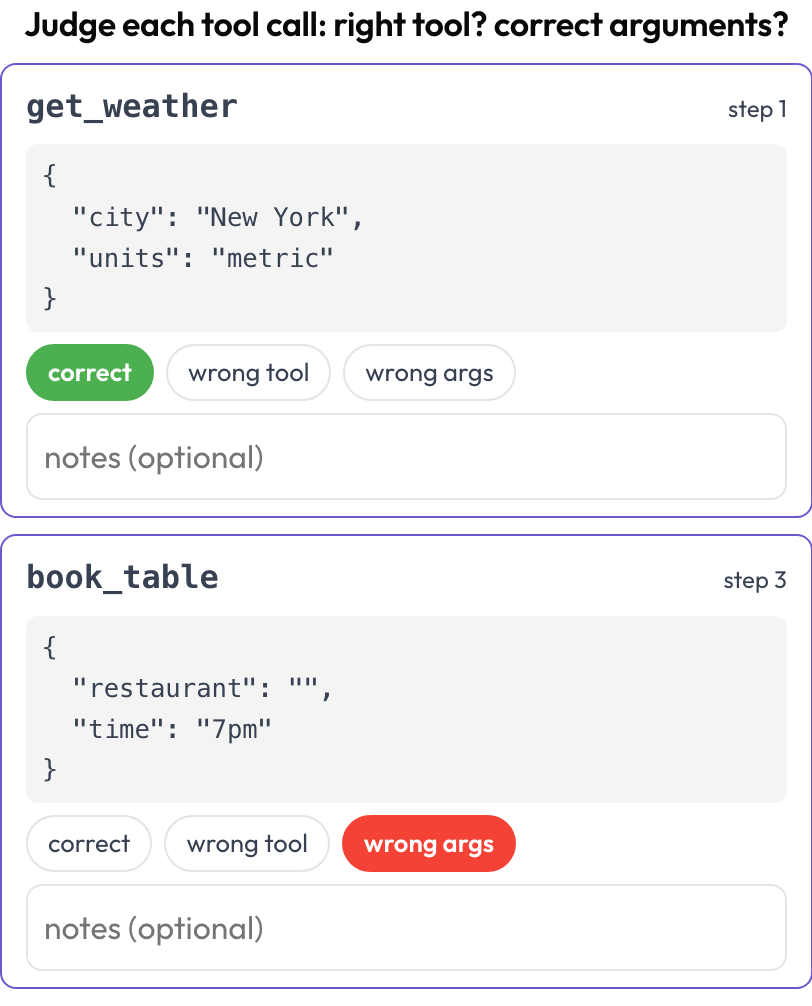 모든 도구 호출 판정하기: 옳은 도구, 올바른 인수, 옳은 순서
모든 도구 호출 판정하기: 옳은 도구, 올바른 인수, 옳은 순서
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order]도구 호출은 각 단계의 tool_calls, tool_call, 또는 action 필드에서 렌더링 시점에 추출되므로, UI 클릭과 API 호출을 섞은 트래젝토리를 하나의 작업에서 두 축 모두로 검토할 수 있습니다.
어떻게 설정하나요?
각각의 표면은 examples/agent-traces/ 아래에 실행 가능한 예제를 제공합니다. 샘플 데이터로 스키마를 보려면 Potato를 그중 하나로 가리키세요.
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/gui-trajectory/config.yaml -p 8000여러분 자신의 데이터는 단계 목록으로 들어가며, 각 단계에는 스크린샷 URL 또는 데이터 URI와 동작 문자열이 있습니다. 원시 스크린샷이 아니라 렌더링된 페이지로 작업하는 더 넓은 웹 에이전트는 웹 에이전트 평가를 참고하십시오.
더 읽을거리
- 멀티모달 에이전트 평가 — GUI, 음성, 비디오, 문서 에이전트를 위한 전체 스키마 레퍼런스
- 컴퓨터 사용 및 멀티모달 에이전트 평가 — 스키마 선택 표가 있는 가이드
- 음성 및 비디오 에이전트 평가 — 멀티모달 표면의 나머지 절반
- Potato 2.6.2: 완전한 오픈소스 에이전트 평가 제품군 — 전체 2.6.x 라인