에이전트 평가를 위한 Potato vs LangSmith 및 Langfuse: 실전 비교
에이전트 평가를 위해 Potato를 LangSmith, Langfuse, Labelbox, Scale AI와 비교합니다: 트레이스 렌더링, 단계별 및 멀티 에이전트 어노테이션, 멀티모달 에이전트 리뷰, 코딩 에이전트, 실시간 관찰, 가격, 자체 호스팅.
세 가지 도구, 세 가지 철학
Potato, LangSmith, Langfuse는 모두 에이전트 평가와 맞닿아 있지만, 서로 다른 출발점에서 접근합니다.
- Potato는 어노테이션을 중심으로 합니다. AI 출력에 대한 구조화된 인간 판단을 수집하기 위해 만들어졌고, 이후 에이전트 트레이스, 코드 diff, 실시간 관찰을 지원하도록 확장되었습니다. 그 강점은 어노테이션 스키마의 깊이와 구성 가능성에 있습니다.
- LangSmith는 관찰 가능성을 중심으로 합니다. LangChain 애플리케이션을 프로덕션에서 계측하고, 추적하고, 디버깅하기 위해 만들어졌습니다. 어노테이션 기능은 LangChain 생태계 내 평가 워크플로를 지원하기 위해 나중에 추가되었습니다.
- Langfuse는 오픈소스 관찰 가능성 도구입니다. 모든 LLM 애플리케이션에 대해 트레이싱, 프롬프트 관리, 평가를 다룹니다. 어노테이션 기능이 동작하기는 하지만 모니터링에 비해 부차적입니다.
이 중 어느 것도 보편적으로 더 낫지는 않습니다. 올바른 선택은 주로 어노테이션이 필요한지, 관찰 가능성이 필요한지, 아니면 둘 다 필요한지에 달려 있으며, 특정 프레임워크 생태계에 묶여 있는지에도 달려 있습니다.
기능 비교
아래 표는 AI 에이전트 평가와 관련된 역량을 비교합니다. 팀들이 흔히 함께 검토하는 Label Studio, Argilla, Scale AI도 포함했습니다.
| 기능 | Potato | LangSmith | Langfuse | Label Studio | Argilla | Scale AI |
|---|---|---|---|---|---|---|
| 주요 목적 | 어노테이션 | 관찰 가능성 | 관찰 가능성 | 어노테이션 | 어노테이션 | 어노테이션 |
| 트레이스 포맷 지원 | 13개 포맷 | LangChain 네이티브 | Langfuse SDK | 없음 | 없음 | 커스텀 |
| 단계별 어노테이션 | 완전 지원 (trajectory_eval) | span별 점수 + 코멘트 | span 수준의 구조화된 점수 | 예 (트레이스 가져오기) | 채팅 턴만 | 커스텀 |
| 실시간 에이전트 관찰 | 예 | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 에이전트 일시정지/재개/인계 | 예 | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 코드 diff 렌더링 | 예 (통합 diff, 구문 강조) | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 터미널 출력 렌더링 | 예 (ANSI 색상 지원) | 아니오 | 부분적 | 아니오 | 아니오 | 아니오 |
| PRM 데이터 수집 | 예 (단계별 정확성 라벨) | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 인라인 코멘트가 있는 코드 리뷰 | 예 (라인 단위, 분류됨) | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 쌍대 비교 | 3가지 모드 (나란히, 순차, 블라인드) | 제한적 (1가지 모드) | 아니오 | 아니오 | 예 (1가지 모드) | 예 (1가지 모드) |
| 다기준 루브릭 | 예 (구성 가능한 차원, 척도) | 아니오 | 아니오 | 아니오 | 부분적 | 예 |
| 오류 분류 체계 | 계층적, 구성 가능 | 아니오 | 범주형 점수 구성 | 아니오 | 아니오 | 커스텀 |
| 심각도 점수화 | 예 (가중치 적용, 누적 점수) | 아니오 | 숫자 점수만 | 아니오 | 아니오 | 커스텀 |
| 멀티 에이전트 상호작용 그래프 (어노테이터 편집 가능) | 예 | 아니오 | 시각화만 ¹ | 아니오 | 아니오 | 아니오 |
| 교차 에이전트 실패 귀인 | 예 | 아니오 | 우회책만 | 아니오 | 아니오 | 관리형만 |
| 핸드오프 리뷰 (일급 객체) | 예 | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 에이전트별 + 팀별 스코어카드 | 예 | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 컴퓨터 사용 궤적 (클릭 그라운딩) | 예 | 아니오 | 아니오 | 범용 이미지 도구 | 아니오 | 관리형 데이터셋 ² |
| 풀 듀플렉스 음성 (끼어들기 점수화) | 예 | 아니오 | 재생만 | 아니오 | 아니오 | 턴 기반만 ³ |
| 비디오 시간적 그라운딩 (실시간 IoU) | 예 | 아니오 | 아니오 | IoU는 어노테이터 간 일치도만 | 아니오 | 아니오 |
| 자체 호스팅 | 예 (완전 지원) | 엔터프라이즈 등급만 | 예 (오픈소스) | 예 (오픈소스) | 예 (오픈소스) | VPC (엔터프라이즈) |
| 무료 | 예 (완전한 오픈소스) | 아니오 (무료 등급 제한적) | 부분적 (오픈소스 코어) | 부분적 (오픈소스 코어) | 예 (오픈소스) | 아니오 |
| 프레임워크 종속성 | 없음 | LangChain 생태계 | 없음 | 없음 | 없음 | 없음 |
¹ Langfuse "Agent Graphs"(베타)는 멀티 에이전트 실행을 그래프로 렌더링하지만, 읽기 전용 디버깅 뷰입니다. 어노테이터가 임계 경로를 표시하거나 엣지를 플래그할 수 있는 문서화된 방법은 없습니다. ² Scale AI는 GUI/컴퓨터 사용 궤적을 관리형 데이터 작업으로 어노테이션하며(예: CVAT에서의 CUA-Suite 작업), 직접 구성하는 셀프 서비스 기능이 아닙니다. ³ Scale의 "Voice Showdown"은 턴 기반이며, 풀 듀플렉스 끼어들기/중첩 점수화는 아직 제공되지 않고 계획으로만 명시되어 있습니다(2026-03-20 기준).
비교는 2026-06-24에 LangSmith(docs.langchain.com), Langfuse(MIT 코어, 지속적 릴리스), Label Studio 1.23.0, Argilla 2.8.0, Scale AI 제품 페이지를 대상으로 확인했습니다. 이 도구들은 빠르게 출시되므로, 여기 내용이 오래되었다면 GitHub 저장소에서 정정을 환영합니다.
이 도구들 가운데 Potato는 적절한 diff 포맷팅으로 코딩 에이전트 트레이스를 렌더링하는 유일한 도구입니다.
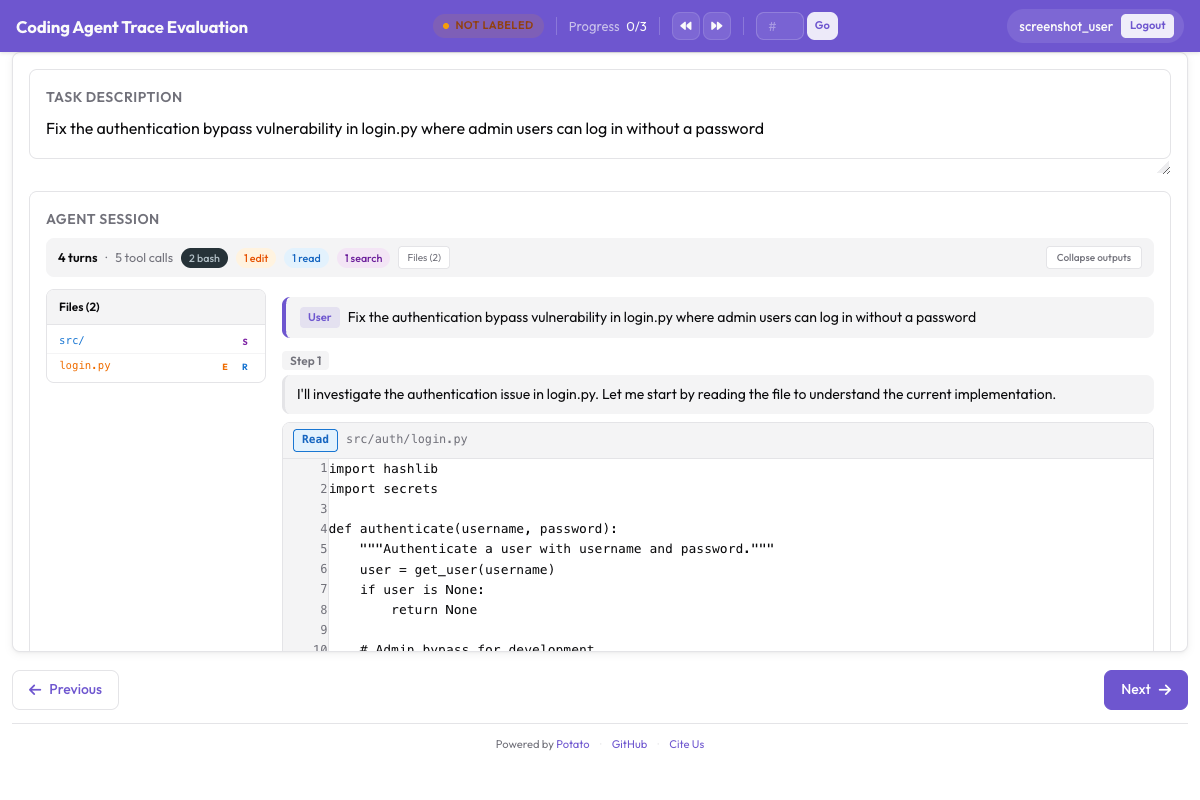 통합 diff 렌더링, 구문 강조, 파일 트리를 갖춘 Potato의 CodingTraceDisplay
통합 diff 렌더링, 구문 강조, 파일 트리를 갖춘 Potato의 CodingTraceDisplay
트레이스 포맷 지원 상세
가장 큰 실질적 차이 중 하나는 각 도구가 네이티브로 지원하는 에이전트 트레이스 포맷의 개수입니다.
Potato는 13개 포맷에 대한 변환기를 포함합니다.
# See all available converters
python -m potato.convert_traces --list-formats
# Available formats:
# react - ReAct-style (Thought/Action/Observation)
# openai - OpenAI function calling / tool use
# anthropic - Anthropic Messages API with tool_use
# langchain - LangChain run traces
# langfuse - Langfuse trace exports
# langsmith - LangSmith dataset exports
# autogen - Microsoft AutoGen conversations
# crewai - CrewAI task outputs
# swe_agent - SWE-Agent trajectories
# claude_code - Claude Code session logs
# aider - Aider chat histories
# webarena - WebArena episode traces
# custom - User-defined format with mapping configLangSmith는 LangChain 트레이스와 네이티브로 동작합니다. 에이전트가 LangChain이나 LangGraph로 구축되었다면 트레이스가 자동으로 흘러 들어옵니다. 그렇지 않다면 LangSmith SDK로 코드를 수동으로 계측하거나 트레이스를 LangSmith 포맷으로 변환해야 합니다.
Langfuse는 Langfuse SDK로 계측된 트레이스와 네이티브로 동작합니다. Python, JavaScript를 지원하며 LangChain, LlamaIndex, OpenAI와의 통합을 갖추고 있습니다. LangSmith와 마찬가지로, 사후 트레이스 변환이 아니라 코드 수준의 계측이 필요합니다.
LangSmith 또는 Langfuse 트레이스를 Potato로 가져오기
이미 LangSmith나 Langfuse에 트레이스가 있고 Potato의 어노테이션 기능을 사용하고 싶다면, 변환기가 이를 처리합니다.
# Export from LangSmith and convert
python -m potato.convert_traces \
--input langsmith_export.jsonl \
--output data/traces.jsonl \
--format langsmith
# Export from Langfuse and convert
python -m potato.convert_traces \
--input langfuse_traces.json \
--output data/traces.jsonl \
--format langfuse따라서 프로덕션 모니터링에는 LangSmith나 Langfuse를 계속 사용하고, 상세한 인간 평가가 필요할 때 트레이스를 Potato로 가져올 수 있습니다.
단계별 어노테이션: 격차가 가장 큰 지점
가장 두드러진 역량 차이는 단계별 어노테이션의 깊이에 있습니다.
Potato는 다음을 갖춘 trajectory_eval 스키마를 제공합니다.
- 단계별 정확성 라벨 (correct/incorrect)
- 계층적 오류 분류 체계 선택
- 구성 가능한 가중치가 적용된 심각도 수준
- 단계마다 갱신되는 누적 점수
- 단계별 자유 텍스트 근거
- 이 모든 것이 YAML로 구성 가능
# Potato: rich per-step annotation
annotation_schemes:
- annotation_type: "trajectory_eval"
name: "step_eval"
step_correctness:
labels: ["correct", "incorrect"]
error_taxonomy:
- category: "reasoning"
types:
- name: "logical_error"
- name: "incorrect_assumption"
- category: "action"
types:
- name: "wrong_tool"
- name: "wrong_arguments"
severity_levels:
- name: "minor"
weight: -1
- name: "major"
weight: -5
- name: "critical"
weight: -10
running_score:
initial: 100LangSmith는 트레이스 내 개별 실행에 숫자 점수나 범주형 라벨을 붙일 수 있게 해줍니다. 기본적인 품질 추적에는 유용하지만 오류 분류 체계, 심각도 가중치, 누적 점수는 지원하지 않습니다. 내장된 단계별 리뷰 인터페이스는 없으며, 트레이스 상세 보기에서 실행에 점수를 매깁니다.
Langfuse는 트레이스 수준과 관찰(span) 수준에서 점수화를 지원하며, 범주형 *점수 구성(score configs)*을 통해 고정된 라벨 집합(사용 가능한 오류 분류 체계)을 정의하고 여러 개의 이름 붙은 점수를 같은 span에 붙일 수 있습니다. 일급 스키마로 제공되지 않는 것은 계층적 분류 체계나 단계에 걸쳐 누적되는 심각도 가중 누적 점수입니다. 이런 것들은 평면적인 점수 구성으로 직접 조립해야 합니다.
그래서 격차에 대한 정직한 버전은 예전보다 좁아졌습니다. Langfuse와 Label Studio(이제 단계별 리뷰를 위해 LangGraph/CrewAI/AutoGen 트레이스를 가져옵니다)는 둘 다 구조화된 단계별 점수화를 수행합니다. Potato가 여전히 목적에 맞게 만들어진 지점은 그 조합입니다. 하나의 trajectory_eval 스키마 안에 계층적 오류 분류 체계, 심각도 가중치, 누적 점수가 함께 들어 있는데, 이는 PRM 학습 데이터를 구축하거나 에이전트가 처음 잘못되는 지점을 짚어내는 데 필요한 것입니다.
코딩 에이전트 지원
코딩 에이전트(Claude Code, Aider, SWE-Agent, Devin, OpenHands)를 평가하려면 리뷰가 빠르게 진행되도록 코드 diff와 터미널 출력을 렌더링해야 합니다. 바로 이 지점에서 Potato가 다른 도구들을 앞섭니다.
Potato는 다음을 렌더링합니다.
- 빨강/초록 강조와 구문 강조가 적용된 통합 diff
- ANSI 색상 코드 지원이 있는 터미널 출력
- 특정 라인에 고정된 인라인 diff 코멘트
- 파일 수준 품질 평가
- 승인/변경 요청에 대한 PR 스타일 판정
LangSmith는 도구 호출의 입력과 출력을 포맷된 JSON으로 표시합니다. 코드 diff는 도구 출력 안의 원시 텍스트 문자열로 나타납니다. diff 렌더링, 구문 강조, 인라인 코멘트는 없습니다.
Langfuse 역시 트레이스 데이터를 구조화된 JSON으로 표시합니다. 코드 내용은 일반 텍스트로 나타납니다. diff나 터미널 출력에 대한 전용 렌더링은 없습니다.
코딩 에이전트의 경우 이것이 리뷰어의 하루를 바꿉니다. 구문 강조가 적용된 통합 diff 뷰에서 인라인 코멘트와 함께 50줄짜리 diff를 리뷰하는 것은 같은 diff를 JSON 문자열로 읽는 데 드는 시간의 일부면 됩니다.
웹 에이전트 트레이스에는 SVG 오버레이가 있는 스크린샷과 필름스트립 탐색이 포함됩니다.
 SVG 액션 오버레이가 있는 스크린샷과 필름스트립 탐색을 보여주는 웹 에이전트 트레이스 뷰어
SVG 액션 오버레이가 있는 스크린샷과 필름스트립 탐색을 보여주는 웹 에이전트 트레이스 뷰어
실시간 에이전트 관찰
Potato는 실행 중인 에이전트를 실시간으로 관찰할 수 있는데, 이는 LangSmith도 Langfuse도 어노테이션 워크플로에서 하지 못하는 일입니다.
Potato의 실시간 관찰 모드에서 어노테이터는 에이전트가 한 단계씩 작업하는 것을 지켜보고, 일시정지하여 현재 상태를 검토하고, 이후에 다시 재개하고, 세션을 인계받아 방향을 바로잡거나 손수 작업을 마칠 수 있습니다.
이는 몇 가지 상황에서 도움이 됩니다. 에이전트가 파괴적인 무언가를 하기 전에 멈추는 것(안전), 인간의 수정을 시연 데이터로 기록하는 것(학습), 그리고 도중에 개입했을 때 에이전트가 어떻게 반응하는지 보는 것(대화형 평가)입니다.
# Enable live observation in Potato config
live_observation:
enabled: true
agent_endpoint: "http://localhost:5000/agent"
allow_pause: true
allow_takeover: true
auto_pause_on:
- action_type: "delete"
- action_type: "execute"
- confidence_below: 0.3LangSmith와 Langfuse는 완료된 트레이스의 사후 분석을 위해 설계되었으며, 실행 중인 에이전트와의 실시간 상호작용을 위한 것은 아닙니다.
쌍대 비교
두 에이전트 출력을 나란히 비교하는 것은 흔한 평가 패턴이며, 특히 모델 버전의 A/B 테스트나 에이전트 아키텍처 비교에 쓰입니다.
Potato는 세 가지 비교 모드를 제공합니다.
- 나란히: 두 트레이스가 동시에 보이며 스크롤이 동기화됨
- 순차: 트레이스 A를 먼저 보고, 그다음 트레이스 B를 본 뒤 판단함
- 블라인드: 트레이스에 모델 표시 없이 무작위로 "A"와 "B"가 붙음
annotation_schemes:
- annotation_type: "pairwise"
name: "comparison"
mode: "side_by_side" # or "sequential" or "blind"
labels:
- name: "A is better"
- name: "B is better"
- name: "Tie"
criteria:
- "Which agent completed the task more efficiently?"
- "Which agent's output is higher quality?"LangSmith는 평가 실험의 "비교 뷰"를 통해 기본적인 쌍대 비교를 지원합니다. 서로 다른 모델 버전 간 실행을 비교할 수 있지만, 인터페이스는 구조화된 선호도 어노테이션보다는 나란한 실행 점검을 위해 설계되었습니다.
Langfuse에는 어노테이션을 위한 내장 쌍대 비교 기능이 없습니다.
각 도구를 언제 사용할까
Potato를 사용해야 할 때:
- 어노테이션이 주된 목표일 때: 단순한 모니터링이 아니라 구조화된 인간 판단이 필요함
- 코딩 에이전트 지원이 필요할 때: diff 렌더링, 인라인 코멘트, 터미널 출력 표시
- PRM 학습 데이터를 수집할 때: 누적 점수를 갖춘 단계별 정확성 라벨
- 자체 호스팅이 필요할 때: 데이터가 자체 인프라에 머물고 클라우드 의존성이 없음
- 여러 에이전트 프레임워크로 작업할 때: 단일 프레임워크 종속이 아닌 13개 트레이스 포맷 변환기
- 풍부한 평가 스키마가 필요할 때: 궤적 평가, 루브릭 평가, 코드 리뷰, 쌍대 비교
- 예산이 제약일 때: 완전 무료에 오픈소스
LangSmith를 사용해야 할 때:
- 이미 LangChain/LangGraph를 사용 중일 때: 트레이스가 설정 없이 자동으로 흘러 들어옴
- 프로덕션 모니터링이 주된 필요일 때: 실시간 트레이싱, 지연 시간 추적, 비용 모니터링
- 어노테이션이 부차적일 때: 깊은 평가 스키마가 아니라 기본 점수화와 피드백이 필요함
- 관리형 서비스를 원할 때: 유지할 인프라가 없음
- 팀이 작을 때: 가벼운 평가에는 무료 등급으로 충분할 수 있음
Langfuse를 사용해야 할 때:
- 오픈소스 관찰 가능성이 필요할 때: 자체 호스팅 모니터링과 트레이싱
- 여러 LLM 제공자를 사용할 때: OpenAI, Anthropic, LangChain, LlamaIndex 전반에 걸친 좋은 통합
- 어노테이션이 주된 사용 사례가 아닐 때: 점수화가 가능하지만 초점은 아님
- 트레이싱과 함께 프롬프트 관리를 원할 때: Langfuse는 프롬프트 버전 관리를 관찰 가능성과 묶어 제공함
- 모니터링용 LangSmith의 무료 대안이 필요할 때: Langfuse의 오픈소스 코어가 대부분의 모니터링 요구를 충족함
보완적 접근: 관찰 가능성 + 어노테이션
많은 팀에게 실용적인 구성은 프로덕션 모니터링에는 관찰 가능성 도구(LangSmith 또는 Langfuse)를, 상세한 인간 평가에는 Potato를 사용하는 것입니다. 워크플로는 다음과 같습니다.
- 프로덕션 트레이싱을 위해 LangSmith나 Langfuse로 에이전트를 계측합니다
- 인간 리뷰가 필요한 트레이스를 샘플링합니다(실패, 엣지 케이스, 무작위 샘플)
- 관찰 가능성 도구에서 그 트레이스를 내보냅니다
- 내장 변환기를 사용해 Potato로 변환 및 가져오기를 합니다
- Potato의 풍부한 어노테이션 스키마로 인간 평가를 수행합니다
- 결과를 개발 주기로 다시 피드백합니다
# Example: sample 100 failed traces from Langfuse and import to Potato
python -m potato.convert_traces \
--input langfuse_failed_traces.json \
--output data/traces_to_review.jsonl \
--format langfuse \
--sample 100이렇게 하면 관찰 가능성 플랫폼의 실시간 가시성과 함께, 어노테이션을 위해 만들어진 도구의 어노테이션 깊이를 함께 얻게 됩니다.
주요 차별점 요약
이 두 가지 화면이 그 주장이 가장 강력한 지점입니다. 저희가 조사한 모든 도구(상용 및 오픈소스) 가운데, Potato는 멀티 에이전트 팀 구조와 멀티모달 에이전트 리뷰를 위한 어노테이터 구성 가능 화면을 제공하는 유일한 도구입니다.
- 클릭 가능하고 어노테이터가 편집할 수 있는 멀티 에이전트 상호작용 그래프 — 임계 경로를 표시하고, 잘못된 핸드오프를 플래그합니다. 다른 곳에서 가장 비슷한 것인 Langfuse의 "Agent Graphs"는 읽기 전용 디버깅 뷰입니다.
- 교차 에이전트 실패 귀인, 일급 객체로서의 핸드오프 리뷰, 에이전트별 및 팀별 스코어카드, 도구 경합 타임라인, 그리고 창발적 동작 태깅 — 이 가운데 어느 것도 다른 도구들은 내장 어노테이션 구성으로 제공하지 않습니다.
- 클릭 그라운딩이 있는 컴퓨터 사용 궤적, 끼어들기 점수화가 있는 풀 듀플렉스 음성 타임라인, 그리고 실시간 IoU가 있는 비디오 시간적 그라운딩. Scale AI는 GUI 그라운딩과 음성 평가를 수행하지만 관리형 데이터셋 작업으로 제공하며, 그 음성 아레나는 여전히 턴 기반입니다.
이에 더해, Potato는 코딩 에이전트 diff 렌더링과 인라인 코멘트, PRM 데이터 수집, 일시정지/재개/인계가 가능한 실시간 관찰, 어떤 프레임워크든 지원하는 트레이스 수집, 심각도 가중 누적 점수를 갖춘 계층적 오류 분류 체계, 세 가지 쌍대 비교 모드, PR 스타일 코드 리뷰를 결합한 유일한 무료 자체 호스팅 도구로 남아 있습니다.
이 모든 것을 한데 묶은 다른 도구는, 오픈소스든 상용이든 저희가 아는 한 없습니다. 2026-06-24 기준으로 LangSmith, Langfuse, Labelbox, Scale AI, Label Studio, Argilla, Braintrust를 대상으로 확인했습니다(비교 표 아래의 날짜가 적힌 각주를 참고하십시오). LangSmith와 Langfuse는 강력한 관찰 가능성 도구이며, 그 어노테이션 기능은 span 범위의 점수이지 에이전트 구조 화면이 아닙니다. Label Studio와 Argilla는 범용 어노테이션 도구입니다. Label Studio는 트레이스 가져오기를 덧붙였지만, 둘 다 위의 멀티 에이전트나 멀티모달 에이전트 화면을 제공하지 않습니다. Labelbox와 Scale은 에이전트 평가 데이터 제품을 제공하지만, 연구 팀이 실행하고 커스터마이징할 수 있는 자체 호스팅 도구가 아니라 유료 클라우드 또는 관리형 서비스입니다.
여러분의 목표가 에이전트가 어떻게, 왜 성공하거나 실패하는지 이해하고, 그것을 개선할 학습 데이터를 수집하는 것이라면, Potato는 다른 도구들이 열어둔 채로 남겨두는 공백을 메웁니다.
마이그레이션 경로
LangSmith에서 Potato로 (어노테이션용)
# 1. Export your dataset from LangSmith
langsmith export dataset my_eval_dataset -o langsmith_data.jsonl
# 2. Convert to Potato format
python -m potato.convert_traces \
--input langsmith_data.jsonl \
--output data/traces.jsonl \
--format langsmith
# 3. Create your Potato config and start annotating
potato start config.yaml -p 8000Langfuse에서 Potato로 (어노테이션용)
# 1. Export traces from Langfuse via API
import requests
response = requests.get(
"https://cloud.langfuse.com/api/public/traces",
headers={"Authorization": "Bearer your_api_key"},
params={"limit": 500}
)
with open("langfuse_traces.json", "w") as f:
json.dump(response.json()["data"], f)# 2. Convert to Potato format
python -m potato.convert_traces \
--input langfuse_traces.json \
--output data/traces.jsonl \
--format langfuse
# 3. Start annotating
potato start config.yaml -p 8000Label Studio 또는 Argilla에서 (에이전트 평가용)
현재 범용 어노테이션에 Label Studio나 Argilla를 사용하고 있고 에이전트 평가 역량을 추가하고 싶다면, Potato를 기존 도구와 나란히 실행할 수 있습니다. 에이전트와 무관한 어노테이션 작업(NER, 분류 등)에는 Label Studio나 Argilla를 사용하고, 트레이스 렌더링, 단계별 어노테이션, 코드 리뷰가 필요한 에이전트 전용 평가에는 Potato를 사용하십시오.
결론
Potato, LangSmith, Langfuse 중에서 고르는 일은 추상적으로 무엇이 최선인지의 문제가 아닙니다. 주로 무엇이 필요한지에 달려 있습니다.
- 프로덕션에서 에이전트를 모니터링하려면 LangSmith나 Langfuse를 사용하십시오.
- 구조화된 인간 어노테이션으로 에이전트 동작을 평가하려면 Potato를 사용하십시오.
- 둘 다 필요하다면 함께 실행하십시오. 서로를 보완합니다.
던져야 할 질문은 주된 목표가 에이전트가 무엇을 하는지 관찰하는 것인지, 아니면 얼마나 잘하는지 평가하는 것인지입니다. 평가라면 Potato가 바로 그것을 위해 만들어졌습니다.
더 완전한 나란한 비교는 비교 문서와 에이전트 평가 가이드를 참고하십시오.