从评估到训练数据:用于 SFT 和 DPO 的轨迹编辑
大多数智能体评估止步于一个分数。Potato 2.6 的 trajectory_edit 模式让标注者重写错误的步骤,而不是给它打分,并将每次修正导出为监督微调目标和 DPO 偏好对。
智能体评估通常以一个数字收场。标注者读完一条轨迹,判定第三步出了错,于是记下一个低分或标记一种错误类型。这个数字对于衡量智能体失败的频率很有用,但对于修复智能体却帮助不大,因为"第三步错了"并没有告诉模型第三步本该是什么。
即将发布的 Potato 2.6 加入了一种索要答案而非评分的模式。借助 trajectory_edit,标注者可以重写 agent trace(智能体轨迹)中的步骤——修正搞砸的推理步骤、修复打错的 tool call(工具调用),或加强薄弱的最终答案——而 Potato 会把修正后的轨迹保留在原始轨迹旁边。随后,trajectory_correction 导出器会把每个 (original, corrected) 对转化为训练数据:监督微调 目标和 直接偏好优化 偏好对。
这正是本文要讲的转变。它把一个评估工具变成了训练数据生产工具,也改变了人类标注者的时间所产出的东西:不再是一个标签,而是一个学习信号。
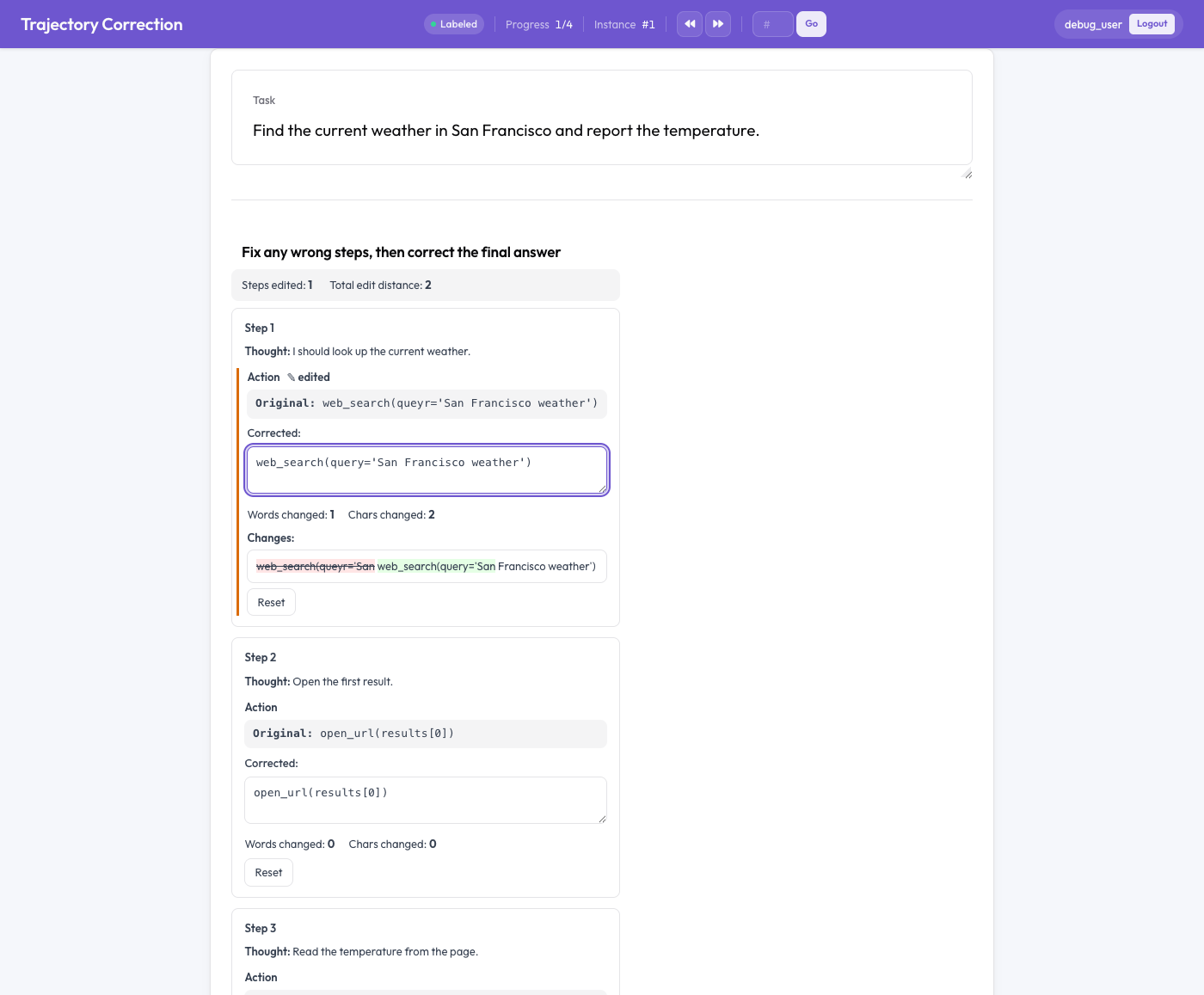 轨迹修正编辑器
轨迹修正编辑器
编辑而非打分
每个智能体步骤都呈现为一张卡片,分为两半:原始文本(只读),以及一个预填了原始内容的可编辑修正框。标注者直接编辑修正框。在输入时,会同时发生三件事:
- 实时的逐词差异对比,以绿色高亮新增内容、以红色删除线标记删除内容,
- 统计被改动的词数和字符数,以及
- 任何发生改动的字段上都会出现一个"已编辑"标记。
如果标注者改变主意,"Reset"按钮可以将某个字段恢复为原始内容。关键在于,所有内容都不是必填的。读完一条轨迹后认为它正确的标注者只需原样放着不动,而未经编辑的轨迹不会产生任何训练对。信号只来自真实的修正。
配置
该模式指向你数据中的步骤列表,并指定哪些字段可编辑:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer默认情况下,只有每个步骤的 action 是可编辑的。当你希望标注者既修正智能体的动作、也修正它的推理时,把 thought 加入 editable_fields;当你希望为每次改动附上书面理由时,设置 require_reason_on_edit: true,这在修正本身也需要被审查时很有帮助。
数据格式就是你的轨迹原本的样子。该模式从 steps_key 指定的字段读取步骤;每个步骤都是一个对象,其字段可被编辑:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}queyr 中的拼写错误正是标注者会在修正框中修复的那类问题,它会产生一个只改一个 token 的修正,供模型学习。
从仓库根目录运行内置示例:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000从修正到训练文件
trajectory_correction 导出器会写出三个文件,分别用于不同的下游用途:
trajectory_corrections.json保存完整记录:original_trace、重建后的corrected_trace,以及带有编辑距离和理由的逐字段edits。这是你的审计追踪。trajectory_sft.jsonl每条被编辑的轨迹占一行,{"prompt": <task>, "completion": <corrected_trace>}。修正后的轨迹成为模型被微调去复现的目标。trajectory_dpo.jsonl每条被编辑的轨迹占一行,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}。人类的编辑定义了偏好:修正版优于原始版。
 编辑如何变成 SFT 和 DPO 训练数据
编辑如何变成 SFT 和 DPO 训练数据
DPO 文件是这里白送的部分。在普通的偏好数据流水线中,你必须生成或收集一个更差的响应,来与更好的响应配对。而在这里,更差的响应已经存在(就是智能体产出的那条原始轨迹),人类的编辑就是修正版被偏好的证据。一次标注同时产出一个 SFT 目标和一个 DPO 对。
哪些会被跳过,以及为什么重要
未编辑的轨迹会被计数,但会从 SFT 和 DPO 文件中排除。在未改动的轨迹上训练对模型毫无教益,更糟的是,它会让偏好数据集充斥着 chosen == rejected 的对,平添噪声。被跳过的数量仍会出现在导出统计中,因此你能看到这一批中有多少已经是正确的——这本身就是关于智能体质量的有用信号。在多名标注者的情形下,每个对某条轨迹做过编辑的标注者都会产出一条 SFT/DPO 记录,因此各自独立的修正都会贡献进来。
几处需要留意的棱角
- 差异对比是逐词的。对于不含空格、形似代码的工具调用,即使只改一个字符,单个 token 也可能显示为整体被改。在这些情况下,字符距离计数器才是精确的信号;对于密集的工具调用,请相信它而非可视化的差异对比。
- 编辑天然与打分搭配。如果你还想在同一条轨迹上获得逐步的正确性标签或一套错误分类,可以让一个步骤级的打分模式与编辑器并行运行,这样一遍处理就能同时产出诊断和修复。
为什么这很重要
智能体调优循环在"它本该怎么做"这一步上一直存在瓶颈。分数告诉你模型在哪里失败;它们并不产出可供训练的修正后行为,于是团队最终要么撰写合成修正,要么为第二轮标注付费。轨迹编辑把这一步并入了评估本身。本来会去给轨迹打分的同一个人,转而去修复它,而这份修复就是训练数据。
轨迹编辑随 Potato 2.6 发布。完整选项列表见 轨迹编辑文档,编辑前快速阅读轨迹请看 eval_trace 显示,导出器细节请见 导出格式参考。