将质性编码引入 Potato:码本、备忘录与原生码
了解 QDA 模式——即将随 Potato 2.6 推出的质性数据分析工作区:动态码本、原生编码、分析备忘录、案例,以及面向整个语料库的全文检索。
如果你曾经编码过访谈转录稿,那你一定熟悉这套软件的故事。那些严肃的质性数据分析(QDA)工具,比如 NVivo、ATLAS.ti、MAXQDA 和 Dedoose,功能强大但价格不菲。它们只能在桌面端运行,把你的项目锁进专有文件格式里,还让协作变成一场授权谈判。于是不少研究者干脆改用电子表格编码,结果做到一半就理不清头绪,因为电子表格根本不知道什么叫"码"。
Potato 出身于另一边的阵营,最初是一款面向 NLP 和机器学习数据集的文本标注工具。在最近几个版本里,它逐渐长出了质性工作流所需的部件:覆盖段落的跨度(span)、共享的码本、一致性指标。即将发布的 2.6 版本把这些部件整合成一个模式,贴合质性研究者真实的工作方式。
本文将带你了解 QDA 模式:它会启用什么、各部件如何协同,以及配置文件长什么样。如果你想查阅参考资料,QDA 模式文档列出了完整的选项清单。
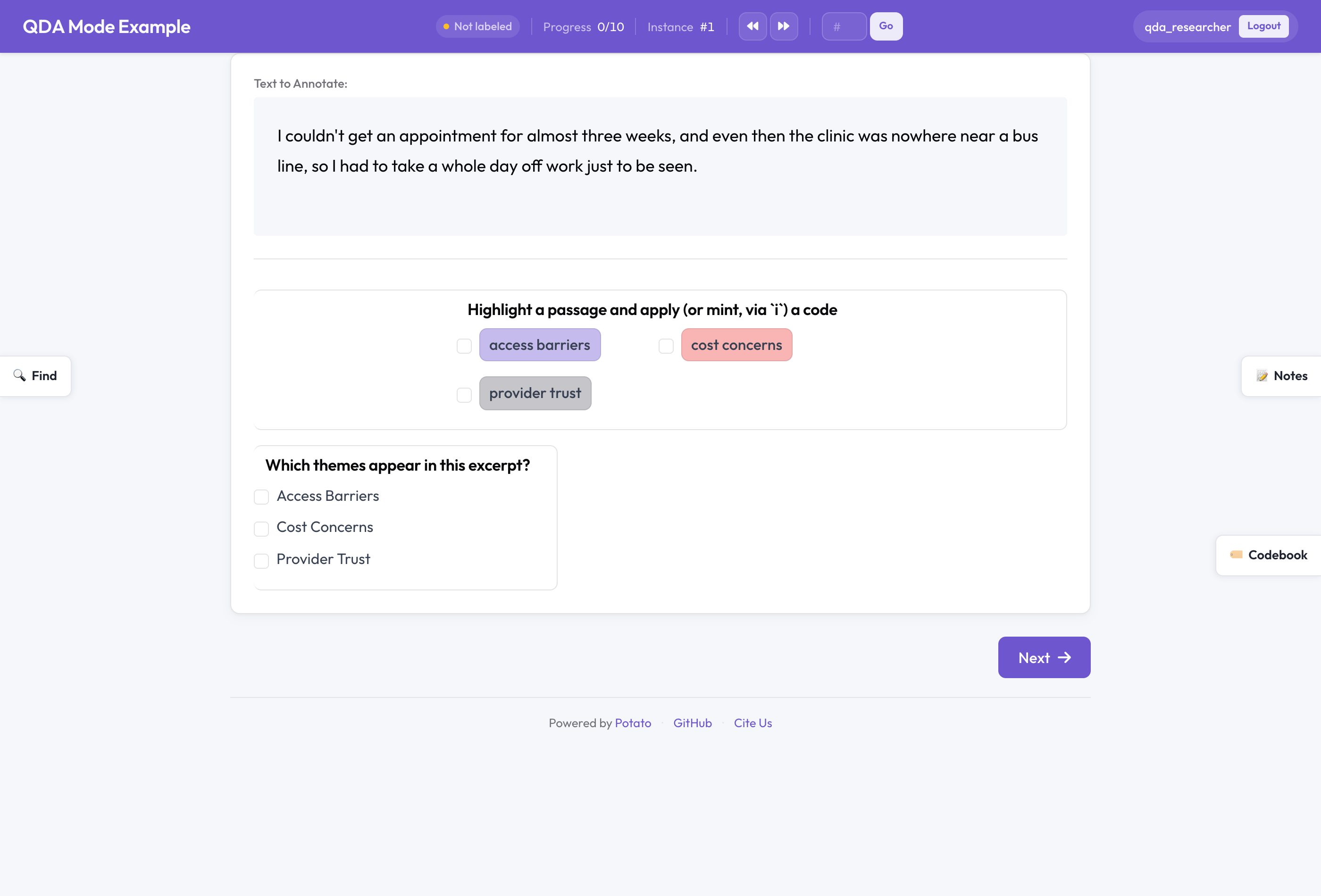 处于 QDA 模式下的 Potato
处于 QDA 模式下的 Potato
一个开关,质性的默认值
Potato 的大部分机制在差异极大的任务之间是共享的。同一套跨度方案,既能为 NER 数据集标注命名实体,也能为访谈中的段落打标。这两项工作的区别不在于功能集,而在于姿态。一个众包的 NER 项目想要的是固定的标签集,以及用于测量一致性的重叠抽样;而一位独自编码二十份访谈的研究者,想要的是边读边发明码,并对自己的观察保留私人笔记。
QDA 模式就是那个假定采取第二种姿态的单一开关:
qda_mode:
enabled: true # compose codebook + memos + cases + search设置 qda_mode.enabled: true 会把 Potato 的通用功能切换到它们的质性默认值。码本变得可以边编码边编辑,而不再被锁定。备忘录侧边栏开启。案例开启,并带自动检测。在任何你标记为以码本为支撑的跨度方案上,原生编码都变得可用。
| 功能 | 标准默认值 | QDA 模式下 |
|---|---|---|
| 码本模式 | fixed | open:随时新增、重命名、改色、移动或删除码 |
| 备忘录侧边栏 | 关闭 | 开启 |
| 案例 | 关闭 | 开启,带自动检测 |
| 标注者检索并认领 | 关闭 | 可用(search.annotator_claim: true) |
| 原生编码快捷键 | i | 在任何以码本为支撑的跨度方案上激活 |
这些都不是写死的。QDA 模式只改变起点;每一项默认值都可以被覆盖。唯一的例外是一道护栏:如果你接入了 Prolific 或 Mechanical Turk 这类众包后端,Potato 会强制把码本锁定为 fixed,这样付费标注者就无法在你不知情的情况下重塑共享方案。
各个部件
动态码本
在扎根理论式的编码中,码本不是你事先写好的东西。它随着你的阅读而生长。你注意到一个反复出现的想法,给它命名,一周后又发现其中两个码其实是同一个,于是把它们合并。
当你为一个跨度方案打上标记时,它就成了码本的一部分:
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]这些 labels 是一组起点,而不是牢笼。在 open 码本模式下,你可以边工作边新增、重命名、改色、移动和删除码。extensible 模式允许编码者添加码,但不能删除共享的码;fixed 则是那个锁定的经典模式,适用于你已经确定好方案的情况。
原生编码
原生编码(in-vivo coding)直接把参与者自己的话语当作码。有人说"我就是等不到回电",于是"等不到回电"就原封不动地成了码。
在以码本为支撑的跨度方案上选中一段文字,按下原生编码快捷键(codebook_invivo_key,默认为 i)。Potato 会直接从高亮的文本中铸造出一个码。当你在整个语料库中反复这样做时,碎片化就成了大敌:你会得到"没回电""等不到回电"和"始终没人回"这三个码,指向的却是同一个想法。代码合成器会反向制衡这一点——在你输入时浮现出近似重复的码,让你复用已有的码,而不是再生出一个新的。
备忘录
没有笔记的编码会丢失码背后的推理。备忘录是附在某个实例上、或附在某段具体文本选区上的分析性笔记。你可以把它们保密,也可以与团队共享。"我当初为什么这样编码"就活在这里,而且它们会与引文一同导出,让你的审计轨迹在项目结束后依然留存。
案例
案例把若干摘录归并为一个分析单位:一位参与者、一份文档、一次实地访问。摘录归组之后,案例层级的属性会被提升上来,于是你就能将码与参与者变量进行交叉列表。如果每份访谈都带有一个 condition 字段,管理端的交叉表就能显示某个码在不同条件之间的分布。
cases:
enabled: true
key: participant_id
attributes: [condition]检索
只有当你能跳转到某个词的任意一处出现时,语料库才是可导航的。QDA 模式内置了面向整个数据集的 FTS5 全文检索。在 annotator_claim: true 的情况下,编码者可以把任意检索命中项直接拉进自己的队列——这正是一位分析者按主题而非严格从头到尾通读来推进整个语料库的方式。
search:
enabled: true
annotator_claim: true各部件如何协同
在底层,码本、备忘录、案例和检索读写的都是同一个项目数据库,因此在某一处铸造的码,会立即在其他每一处变得可检索、可导出。
 QDA 模式如何在共享存储之上组合其各个部件
QDA 模式如何在共享存储之上组合其各个部件
一份完整的配置
下面是一项小而完整的研究。cases、search 和备忘录代码块都是可选的(QDA 模式本已开启案例和备忘录),所以你只在需要调整某个默认值(如案例键)时才写它们。
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]安装好 2.6 后,从仓库根目录运行它:
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000把你的编码成果导出来
两个导出器能把已编码的数据转化为质性论文所需的交付物:
codebook为每个码输出一行,包含其层级、描述、颜色和使用计数。quotation_report为每个已编码的跨度输出一行:引文、其字符偏移量、来源实例以及编码者。加上include_memos=true即可附上你的备忘录。
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csv如果同一份材料由不止一人编码,你会需要一个信度数值。Potato 会针对这些码报告 Cohen's 和 Fleiss' kappa,这一功能随 2.5 版本与上述导出器一同推出。
它的定位
QDA 模式并不打算在每一个维度上都超越 NVivo 的功能。它提供的是一种不同的权衡:免费、开源、基于 Web、可协作,并且与你的机器学习标注和智能体评估栖身于同一款工具之中。如果你的实验室已经在用 Potato 做标注,那么质性编码现在只差一个配置代码块,而不再是一套需要授权的独立桌面软件。