闭环:将智能体错误和评判分歧重新交给人工
在智能体评估中,人工审查时间是最稀缺的资源。Potato 2.6 将基于信号的分流队列与评判者—人工对齐结合起来,让最糟糕的轨迹优先送达人工,并让你的 LLM 评判者持续变得更好。
一旦你开始大规模评估智能体,瓶颈就不再是"我们能不能标注它",而是"我们把注意力花在谁、花在什么上"。你有成千上万条生产环境轨迹,却只有寥寥几名审查者。LLM 评判者可以对所有内容进行预筛,但它并不完美,而它判断错误的那些情况,恰恰是值得人工花时间处理的情况。
Potato 2.6 中有两项功能协同应对这种稀缺。基于信号的分流队列决定人工最先看到什么。评判者—人工对齐衡量你能在多大程度上依赖评判者,并使其不断改进。把两者一起运行,你就得到一个主动评估闭环:评判者处理大量简单内容,可疑案例插队送达人工,而分歧又反馈回去,造就更好的评判者。
本文将介绍这两个部分以及它们如何衔接。
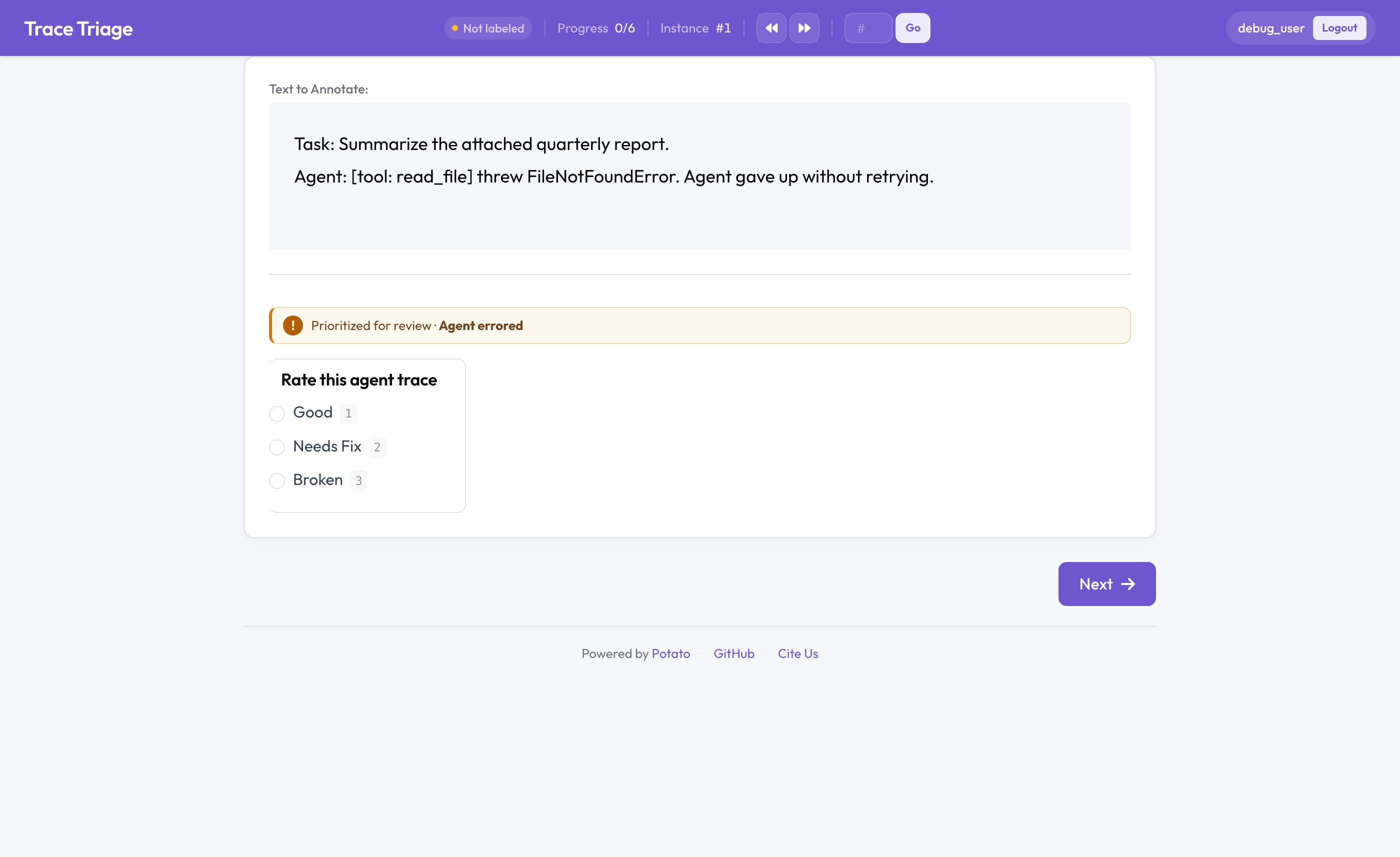 Potato 中的分流队列徽章
Potato 中的分流队列徽章
分流部分:最糟糕的优先,而非先进先出
默认情况下,标注队列是 FIFO(先进先出):条目按加载顺序被分发。当审查时间稀缺时,这是错误的顺序。一条干净的轨迹和一条智能体抛出错误的轨迹,所值得的人工注意力截然不同,而 FIFO 对它们一视同仁。
分流队列按每个条目的质量信号对队列重新排序。该信号可以是智能体错误、生产环境中的点踩、较低的自动评分,或你数据中的任何字段:
triage:
enabled: true
order: desc # high priority first (default)
show_badge: true # banner during annotation explaining the priority
rules: # evaluated in order; highest matching priority wins
- name: "Agent errored"
priority: 100
when:
field: status
equals: error
- name: "Negative feedback"
priority: 80
when:
field: feedback
in: [thumbs_down, negative]
- name: "Low quality score"
priority: 60
when:
field: score
lt: 0.5
assignment_strategy: priority规则自上而下评估,匹配到的最高优先级胜出,因此一条既出错又带有负面反馈的轨迹仍会落在 100。如果你完全省略 rules,Potato 会回退到一套合理的默认规则(错误状态为 100,负面反馈为 80,评分低于 0.5 为 60),所以在你调优之前,开箱即用的行为就已经很合理。
条件运算符覆盖了你实际需要的各种比较:
| Operator | 含义 |
|---|---|
equals | 精确匹配(字符串不区分大小写) |
in | 值是列表中的某一项 |
contains | 列表包含,或子串匹配 |
lt / lte / gt / gte | 数值比较 |
exists | 字段存在或不存在 |
当信号本身就是数字时,你可以直接从字段读取,而无需编写规则:
triage:
enabled: true
signal_field: quality_score
invert_signal: true # lower score => higher priority它同样适用于实时流量
优先级分数在条目加载或被摄取时计算一次,随后存储在条目上,因此分配过程始终很轻量。同样的设计意味着运行时摄取可以直接生效:通过 webhook 端点或 Langfuse 轮询器在会话中途推入的轨迹,会在到达时被评分,并按优先级顺序就位。一条在下午两点到达的低分或出错轨迹,会插到今早就在等待的那些干净轨迹之前。设置 assignment_strategy: priority 才能让队列真正按该顺序分发;show_badge 是独立的,因此即使你保留另一种策略,"为何被标记"的横幅也会显示。
对齐部分:该多大程度上信任评判者
分流决定人工看到什么。对齐决定其余部分有多少可以无人监督地交给评判者,并随时间收紧评判者。
评判者对齐会在标注者已经标注过的实例上运行一个可配置的 LLM 评判者,然后报告 Cohen's κ(科恩 kappa 一致性系数)、一个混淆矩阵,以及一份针对人工金标准的分歧列表。标准做法(让评判者对齐约 100–200 条金标准标签、检查它在哪里产生分歧、改写 rubric 评分标准,然后重新运行)正是这套机制所围绕的闭环。
ai_support:
enabled: true
endpoint_type: "ollama"
ai_config:
model: "llama3.2"
temperature: 0.0
judge_alignment:
enabled: true
schemas:
correctness:
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]你可以从管理 API 运行评判者,预测结果会按提示词版本缓存,因此重新运行成本很低:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'当你想要校准时,传入一个编辑过的 rubric。这会创建一个新的提示词版本,因此你可以跨多轮比较 κ,真正看出你的改写是否有帮助:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'该报告可以 JSON 形式获取,或在 /admin/judge-alignment 查看渲染页面,它会显示带 Landis–Koch 解读的 κ、混淆矩阵、一份附带评判者推理的分歧表格,以及一段提示词版本历史,从而让校准进展跨多轮可见。
内联模式将其呈现在标注者面前
启用 inline.enabled 后,每个标注页面都会在人工标签旁边显示评判者的缓存裁决(它的选择、置信度,以及可展开的推理),并附上该任务的实时 κ。点击"接受"会填入相匹配的选项。每一次人工保存都会记录一次人工↔评判者的比较,并汇入实时一致性,因此你正在调优趋近的那个 κ 会随着人们工作而更新。
将两者结合起来
这两项功能在设计上可以组合成一个闭环:
 主动评估闭环:分流、人工审查、评判者对齐、rubric 改进
主动评估闭环:分流、人工审查、评判者对齐、rubric 改进
- 分流将出错和低置信度的轨迹推到人工队列的最前面。
- 人工审查这些高价值条目,恰好在系统最不确定的地方产出新鲜的金标准标签。
- 对齐用这些金标准为评判者打分,分歧列表精确显示评判者与人工在何处产生分歧。
- 你改进 rubric、重新运行、观察 κ 的变化,然后让校准更好的评判者吸收更多简单内容,使人工时间持续流向困难案例。
闭环的每一次循环都把人工注意力花在最有价值的地方,并将其转化为一个你可以更进一步信任的评判者。这正是全部要点:不是把人从智能体评估中移除,而是为他们指明方向。
这两项功能都包含在 Potato 2.6 中。完整参考请参阅分流队列文档和评判者对齐文档,以及用于快速阅读优先轨迹的 eval_trace 显示。