Potato 2.6.2: Uma suíte completa e de código aberto para avaliação de agentes
A linha 2.6.x transforma o Potato em uma plataforma completa e gratuita de avaliação de agentes: ingestão de traces do OpenTelemetry, LangGraph, CrewAI e AutoGen, anotação de equipes multiagente com um grafo de interação clicável, esquemas para agentes multimodais de GUI, voz e vídeo, além de uma arena de modelos, gating em CI e curadoria.
O Potato 2.6 trouxe a primeira onda de avaliação de agentes: calibração de LLM-como-juiz, edição de trajetórias para dados de treinamento e a exibição eval_trace de três painéis. As versões pontuais da linha 2.6.x desde então preenchem o restante. A partir da 2.6.2, o Potato é uma plataforma completa de avaliação de agentes: você pode capturar traces dos seus próprios agentes, anotar agentes individuais, equipes multiagente e agentes multimodais, julgá-los com LLMs em que você pode confiar, classificar modelos em uma arena e fazer gating de lançamentos em CI. Tudo isso é configurado em YAML e permanece no seu próprio servidor.
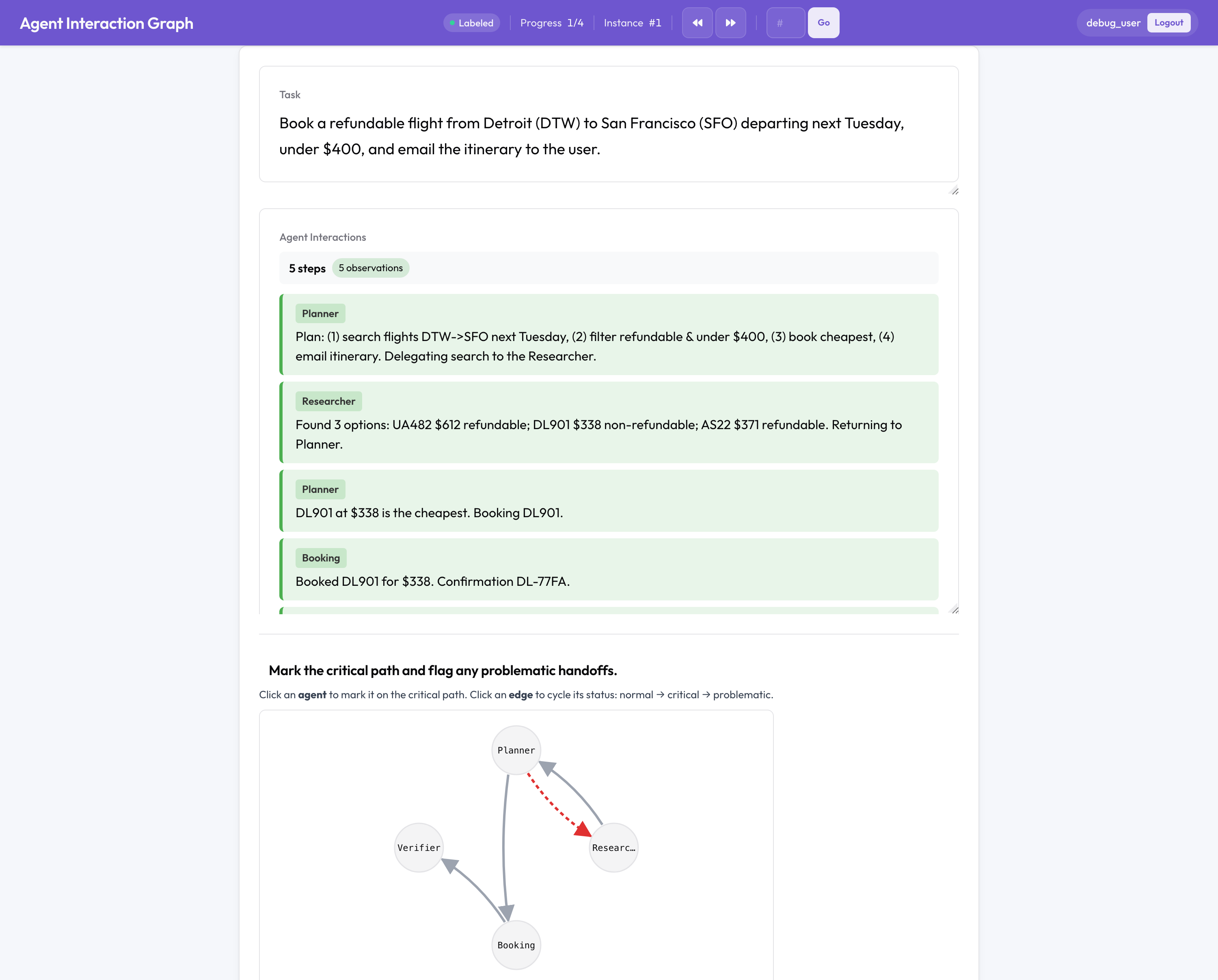 Avaliação multiagente do Potato
Avaliação multiagente do Potato
A maioria desses recursos é algo que as pessoas pagam hoje a uma plataforma hospedada para obter. O Potato os oferece de graça e auto-hospedados. Veja o que chegou ao longo da linha 2.6.x.
 A suíte de avaliação de agentes da 2.6.x, de ponta a ponta
A suíte de avaliação de agentes da 2.6.x, de ponta a ponta
Traga os traces para dentro: um SDK de captura e padrões abertos
A avaliação começa com execuções reais. O novo SDK potato_trace instrumenta qualquer agente: decore uma função com @traceable (síncrona ou assíncrona) e as chamadas aninhadas são capturadas e enviadas ao endpoint de ingestão do Potato, com uma exportação opcional para OpenTelemetry. O Potato também ingere spans de OpenTelemetry / OpenInference e formatos de execução do LangGraph, CrewAI e AutoGen, de modo que os traces do framework que você já usa chegam à fila de anotação sem código de cola. Novos traces podem chegar por um webhook, um poller ou um diretório monitorado e tornam-se atribuíveis aos anotadores conforme chegam.
Referência: SDK de tracing, Regras de automação.
Veja a equipe inteira: avaliação multiagente
Esta é a parte sem equivalente em código aberto. Uma execução multiagente falha de maneira diferente de um agente individual, entre agentes, em uma transferência, no modo como a equipe foi organizada, então o Potato anota a estrutura da equipe em vez de uma transcrição plana:
- Um grafo de interação clicável de agentes e transferências, onde você marca o caminho crítico e sinaliza arestas problemáticas.
- Atribuição de falhas: escolha o agente responsável, o passo decisivo e o motivo, a tripla (agente, passo, motivo) do trabalho de atribuição Who&When.
- Revisão de transferências: cada transferência de controle vira um cartão para sinalizar desalinhamento entre agentes e avaliar a qualidade.
- Boletins por agente e por equipe: fidelidade ao papel, contribuição e coordenação por agente, além de dimensões compartilhadas da equipe e marcos.
- Uma linha do tempo de contenção de ferramentas que revela deadlocks e disputas onde agentes acessam o mesmo recurso ao mesmo tempo.
- Marcação de comportamento emergente para conluio, pensamento de grupo e erros em cascata que abrangem vários agentes e turnos.
 Atribuição de falhas: qual agente, qual passo e por quê
Atribuição de falhas: qual agente, qual passo e por quê
O conjunto completo, com YAML para cada um, está em Avaliação de equipes multiagente, e a análise aprofundada Depurando falhas multiagente percorre cada superfície de ponta a ponta. O guia Como avaliar sistemas multiagente cobre quando usar cada método.
Além do texto: avaliação de agentes multimodais
Os agentes agora operam GUIs, assistem a vídeo e mantêm conversas faladas, e cada um precisa de uma superfície de revisão que um widget de texto não pode oferecer:
- Trajetórias de GUI / uso de computador: captura de tela e ação por passo, um veredito da ação e um marcador de ancoragem de clique que mostra se o clique caiu no elemento certo.
- Linhas do tempo de voz full-duplex: uma linha do tempo de duas faixas usuário/agente com detecção de barge-in e pontuação de alternância de turnos.
- Ancoragem temporal de vídeo: marque os intervalos de eventos de referência com um IoU ao vivo contra o intervalo previsto pelo modelo.
- Marcação de erros em transcrições de fala, raciocínio multimodal intercalado com sinalizadores de alucinação visual e estrutura de tabela-grade de documentos.
 Revisão de uso de computador: correção da ação mais ancoragem do clique
Revisão de uso de computador: correção da ação mais ancoragem do clique
Duas análises aprofundadas as percorrem: Avaliando agentes de uso de computador para agentes de GUI e de SO, e Avaliando agentes de voz e vídeo para agentes de fala, vídeo e documentos. A referência é Avaliação de agentes multimodais, e o guia é Avaliando agentes de uso de computador e multimodais.
Juízes em que você pode confiar, e uma arena
Usar um LLM para avaliar saídas é rotina; o trabalho da 2.6.x trata de saber até onde confiar nele. A calibração de juízes executa uma passagem humana cega contra os rótulos do modelo e reporta acurácia, kappa e Erro de Calibração Esperado (ECE). O alinhamento de juízes ajusta um único juiz contra seus rótulos de referência. E os avaliadores programáticos pontuam trajetórias e texto automaticamente (correspondência de trajetória, correção do uso de ferramentas, LLM-como-juiz sem referência e heurísticas) sem um servidor em execução.
Para comparação direta, a Arena de modelos envia um prompt a vários modelos, coleta preferências e constrói um placar de taxa de vitórias entre OpenAI, Anthropic, Gemini, Ollama e vLLM.
Trate a avaliação como software
As peças operacionais tornam a avaliação repetível:
- Conjuntos de dados e experimentos: conjuntos de avaliação versionados, divisões e comparação lado a lado de experimentos com deltas de regressão.
- Avaliação em CI: um plugin do pytest que falha o build quando uma mudança de prompt ou de modelo regride a qualidade do agente além de um limite.
- Regras de automação: roteie traces de produção que chegam para conjuntos de dados, avaliadores ou a fila de anotação por regra.
- Curadoria semântica: um índice de embeddings para "encontrar traces como esta falha" e fatias dinâmicas salvas.
Como obter
pip install --upgrade potato-annotationCada nova superfície inclui um exemplo executável em examples/agent-traces/, incluindo interaction-graph/, failure-attribution/, gui-trajectory/ e temporal-grounding/. Aponte o Potato para um deles para ver o esquema em funcionamento:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000Se você está avaliando ferramentas, a comparação em Potato vs LangSmith e Langfuse e o guia Ferramentas de anotação de código aberto comparadas mostram onde cada uma se encaixa. Dúvidas e formatos de trace que deveríamos suportar são bem-vindos no repositório do GitHub.