Depurando falhas multiagente: um passo a passo
Como descobrir por que um sistema multiagente de LLM falhou usando o Potato: o grafo de interação, a atribuição de falhas, a revisão de transferências, os boletins por agente, a linha do tempo de contenção de ferramentas e a marcação de comportamento emergente.
Quando uma equipe de agentes falha, a parte difícil não é perceber a falha — é descobrir qual agente a causou, em qual passo, e se o problema real foi uma transferência ruim entre dois agentes que estavam bem cada um por si. Este passo a passo percorre as seis superfícies do Potato construídas para isso, na ordem em que você de fato as usaria em uma execução quebrada. Tudo aqui é configurado em YAML e roda no seu próprio servidor; a referência completa de esquemas está em Avaliação de equipes multiagente.
Um sistema multiagente é composto por vários agentes de LLM com papéis distintos — um planejador, um programador, um revisor — trocando mensagens e transferindo controle. A pesquisa sobre por que esses sistemas quebram, a taxonomia MAST (Why Do Multi-Agent LLM Systems Fail?), constatou que a maioria das falhas é entre agentes: uma restrição perdida em uma transferência, uma equipe que nunca verifica o próprio trabalho, agentes que falam sem se entender. Uma transcrição de chat plana esconde exatamente isso, porque o que deu errado vive no espaço entre duas mensagens, não dentro de nenhuma delas.
 A falha está entre agentes, em uma transferência, não dentro de uma transcrição
A falha está entre agentes, em uma transferência, não dentro de uma transcrição
Como vejo a estrutura de uma execução multiagente?
Comece pelo formato da execução, não pelo texto. O esquema agent_interaction_graph renderiza a execução inteira como um grafo direcionado: os nós são agentes, as arestas são as transferências entre eles, e arestas mais grossas significam mais tráfego. Você clica em um nó para marcá-lo no caminho crítico e clica em uma aresta para alterná-la de normal para crítica e para problemática.
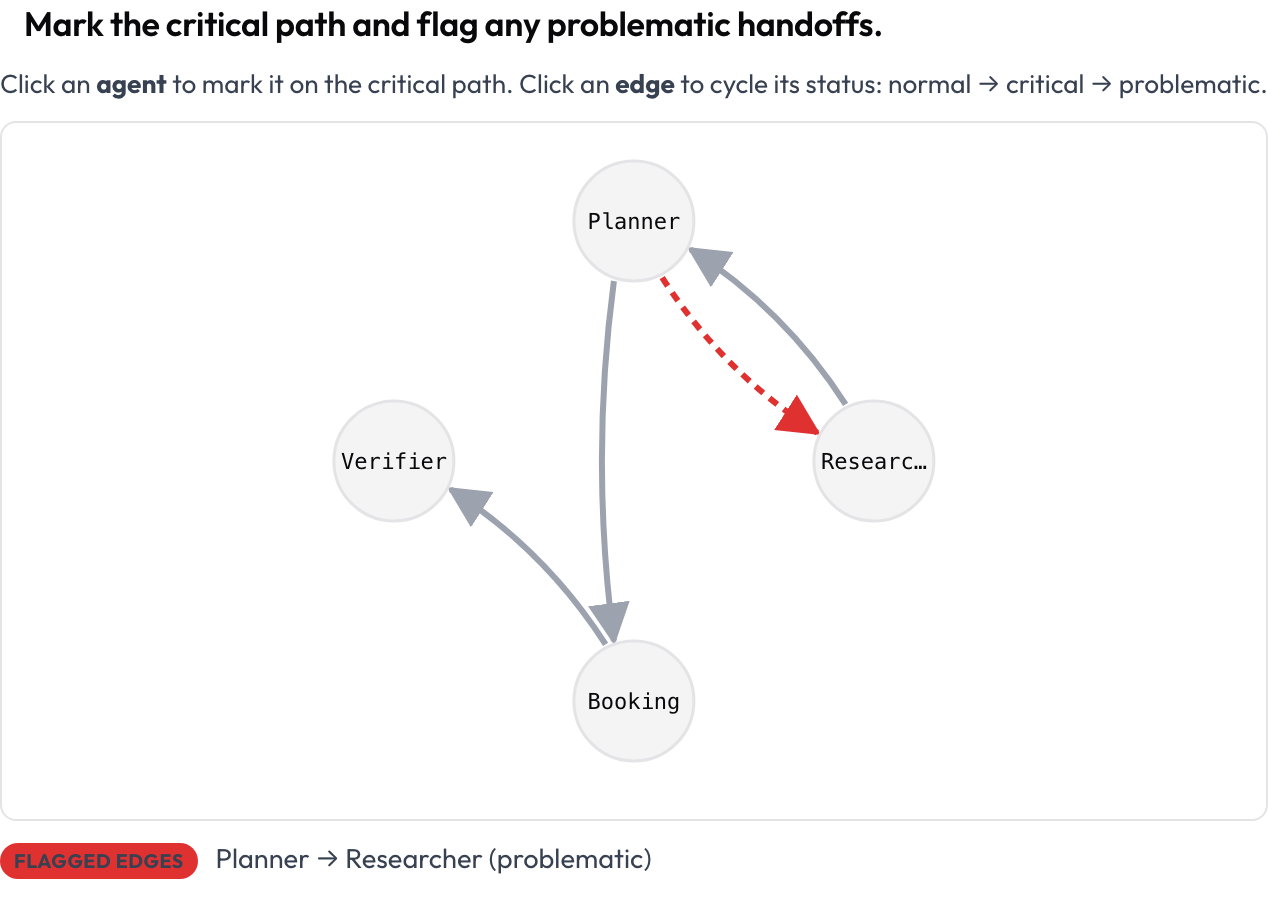 Marque o caminho crítico e sinalize transferências problemáticas
Marque o caminho crítico e sinalize transferências problemáticas
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentO grafo é disposto automaticamente a partir do trace, então você não desenha nada. Cada nó e aresta pode receber foco por teclado, e um resumo em texto lista os nós críticos e as arestas sinalizadas, de modo que o significado nunca depende apenas da cor. Esta visão é a maneira mais rápida de responder "o que conversou com o quê, e onde o caminho saiu dos trilhos."
Como atribuo uma falha multiagente a um único agente?
Depois de conseguir ver a execução, identifique a falha com precisão. O esquema failure_attribution pede a tripla da literatura de atribuição de falhas (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, o conjunto de dados Who&When): o agente responsável, o passo decisivo e o motivo. O menu suspenso de agentes e o seletor de passos são preenchidos a partir dos próprios turnos do trace, então você só pode atribuir a falha a um agente e a um passo que de fato ocorreram.
 Atribua a falha ao agente responsável, ao passo decisivo e ao porquê
Atribua a falha ao agente responsável, ao passo decisivo e ao porquê
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agentCombinar a atribuição com um botão de rádio de sucesso/falha significa que a tripla só é coletada nas execuções que falharam, o que mantém o tempo do anotador nos casos que carregam sinal.
E quanto às transferências em si?
A atribuição nomeia um passo decisivo. A revisão de transferências examina cada transferência de controle. Sempre que o agente em ação muda entre turnos consecutivos, o Potato emite um cartão de transferência A → B, e você sinaliza o que deu errado na passagem — perda de informação, uma restrição descartada, distorção, desvio de objetivo — e avalia a qualidade. Os modos de falha vêm da categoria entre agentes do MAST e do fenômeno de "eco" (Zhang et al., 2025).
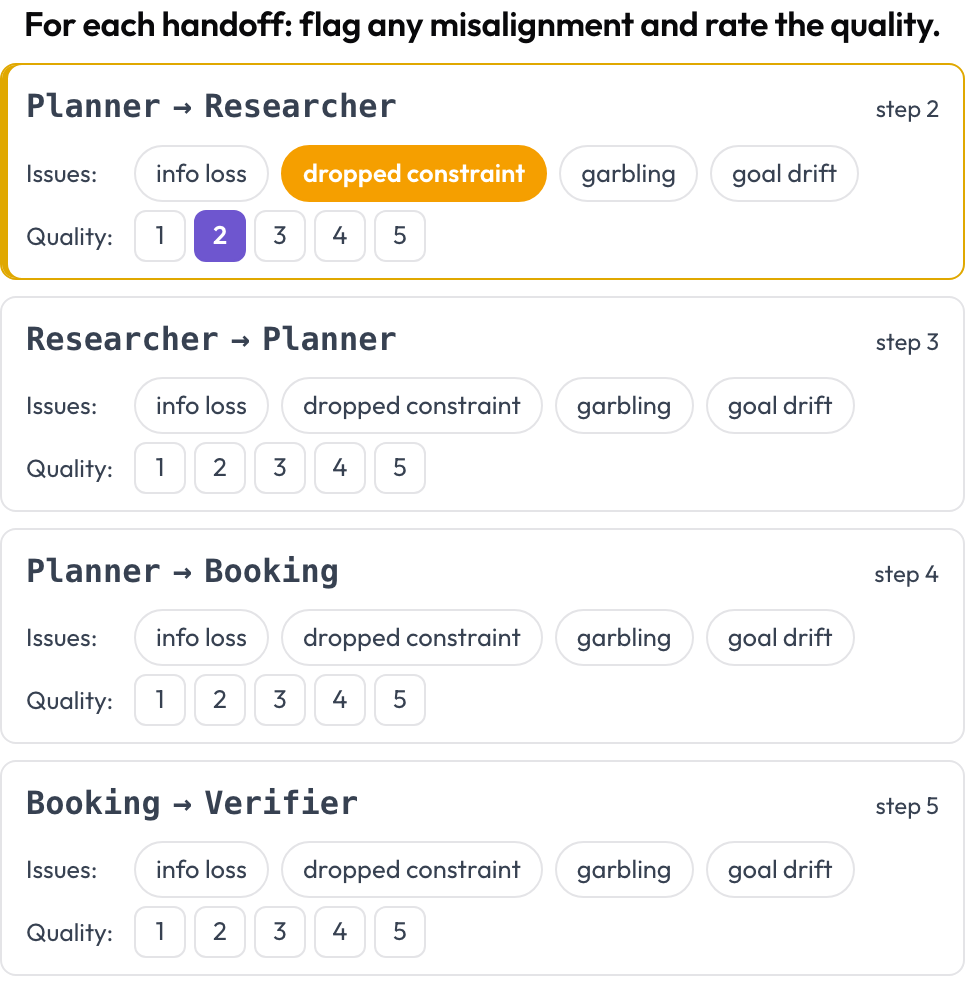 Sinalize o desalinhamento entre agentes em cada transferência e avalie sua qualidade
Sinalize o desalinhamento entre agentes em cada transferência e avalie sua qualidade
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5As transferências são derivadas em tempo de renderização, então não há configuração manual. É geralmente aqui que se resolvem os casos de "cada agente parecia bem, e a equipe ainda assim falhou": a restrição estava viva no agente A e desapareceu até o agente B.
Como pontuo os agentes e a equipe?
Uma falha diz o que quebrou uma vez. Um boletim diz se um design é bom ao longo de muitas execuções. O esquema agent_scorecard pontua dois níveis ao mesmo tempo (MultiAgentBench, Zhou et al., ACL 2025): cada agente em fidelidade ao papel, contribuição e coordenação, e a equipe em suas próprias dimensões compartilhadas, com marcos opcionais. As linhas dos agentes vêm do trace, então a matriz corresponde a quem de fato participou.
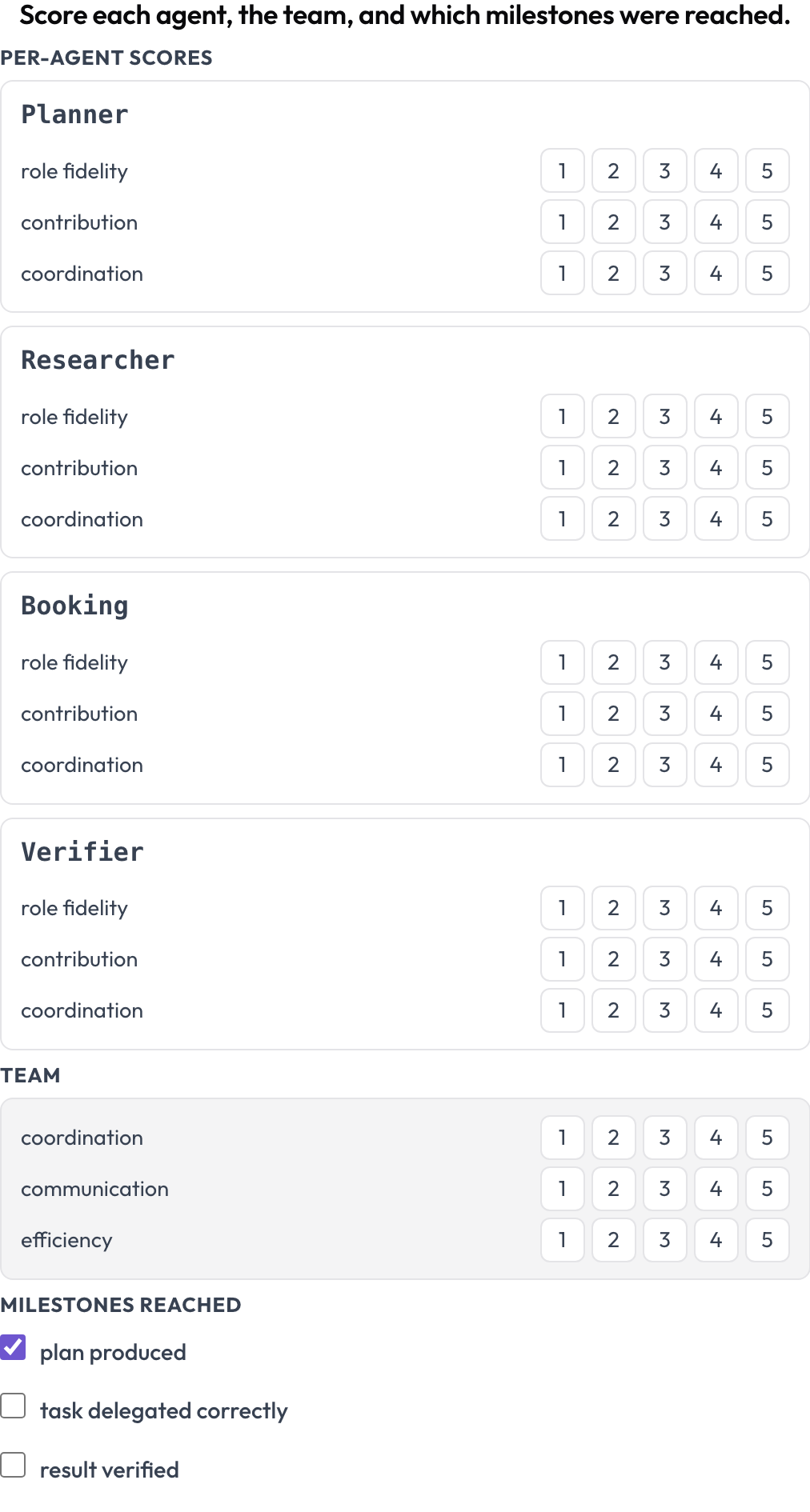 Pontue cada agente em fidelidade ao papel, contribuição e coordenação, além da equipe
Pontue cada agente em fidelidade ao papel, contribuição e coordenação, além da equipe
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]Um agente forte preso dentro de uma equipe mal coordenada aparece aqui como uma linha de agente alta ao lado de dimensões de equipe baixas, que é o padrão que você quer enxergar quando está comparando orquestração sequencial, hierárquica e de chat em grupo nas mesmas tarefas.
E quanto à concorrência e às falhas coletivas?
Mais duas superfícies capturam falhas que uma leitura turno a turno não consegue. A linha do tempo tool_contention coloca cada agente em sua própria faixa e destaca as regiões em que duas chamadas tocam o mesmo recurso em tempos sobrepostos, que você classifica como deadlock, espera circular, condição de corrida ou benigna (DPBench, 2026).
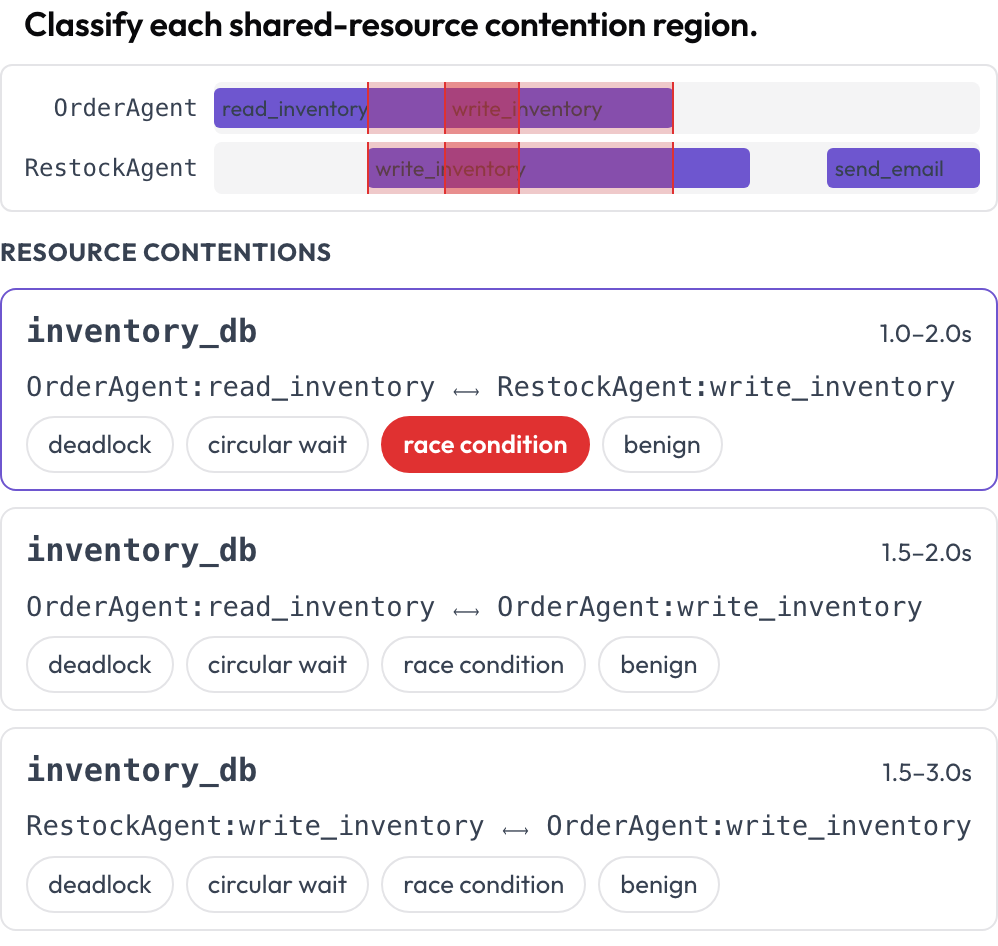 Identifique deadlocks e condições de corrida em uma linha do tempo de chamadas de ferramentas por agente
Identifique deadlocks e condições de corrida em uma linha do tempo de chamadas de ferramentas por agente
E o emergent_behavior trata das falhas que são coletivas em vez de localizadas em um passo — conluio, pensamento de grupo, erros em cascata, desvio de papel. Um comportamento emergente não é um trecho contíguo; é um conjunto de turnos participantes, possivelmente de agentes diferentes, então você marca os turnos que participam e adiciona uma nota.
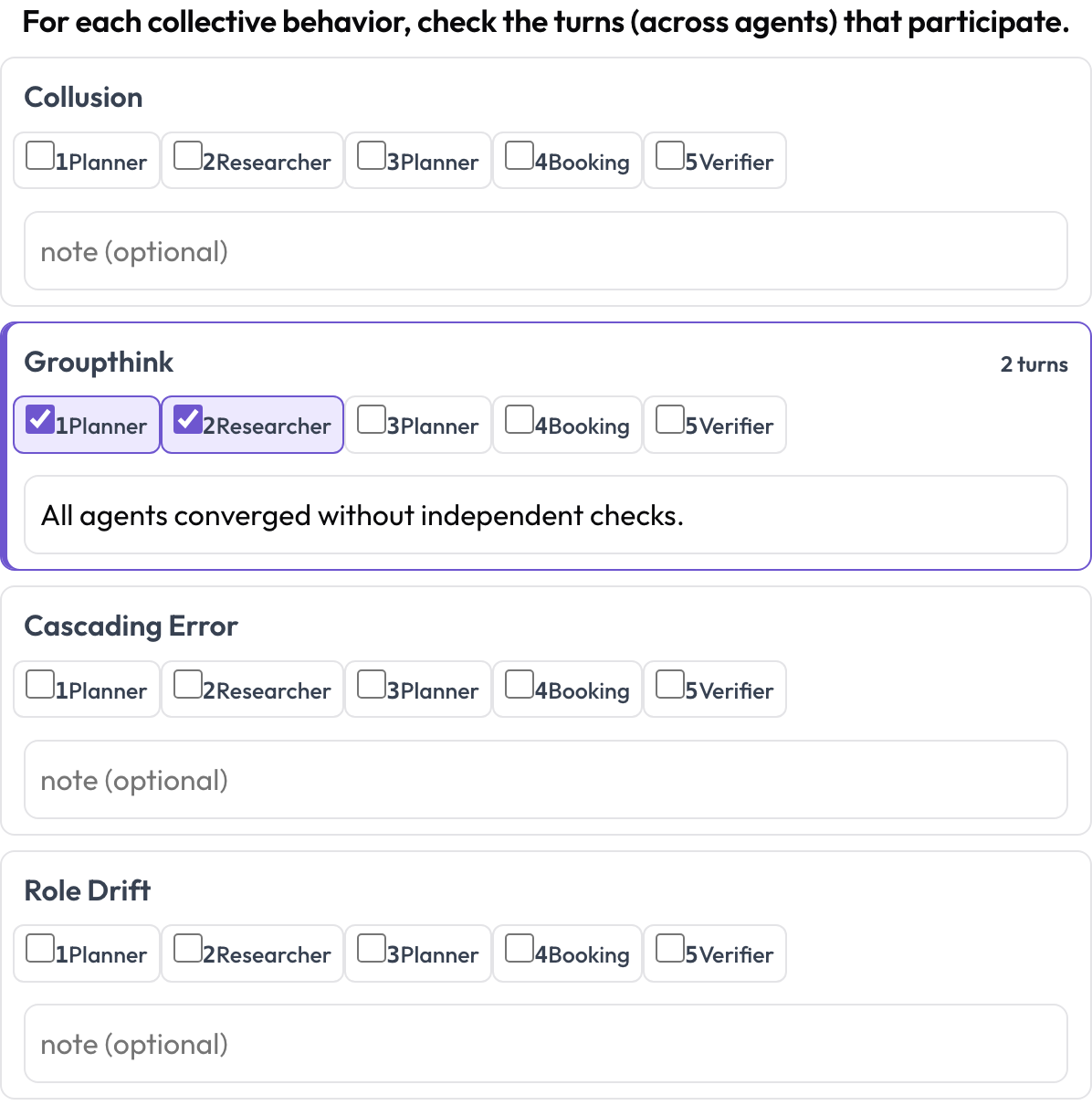 Marque conluio, pensamento de grupo e erros em cascata entre agentes e turnos
Marque conluio, pensamento de grupo e erros em cascata entre agentes e turnos
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueColocando em ordem
Em uma execução realmente quebrada, a sequência costuma ser: ler o grafo de interação para ver o formato, usar a atribuição de falhas para nomear o passo decisivo, abrir a revisão de transferências se o passo decisivo foi uma transferência, e recorrer à linha do tempo de contenção ou à marcação de comportamento emergente quando a falha tem a ver com timing ou com o grupo em vez de um único agente. Pontue com o boletim quando você estiver comparando designs em vez de depurar uma execução. Meça a concordância na atribuição como faria com qualquer rótulo subjetivo; veja Concordância entre anotadores.
Leitura adicional
- Avaliação de equipes multiagente — a referência completa de esquemas com YAML para cada superfície
- Como avaliar sistemas multiagente — o guia de decisão sobre qual método usar e quando
- Potato 2.6.2: Uma suíte completa e de código aberto para avaliação de agentes — tudo o que chegou ao longo da linha 2.6.x
- Anotando trajetórias de agentes — taxonomias de erro por passo, incluindo a marcação MAST na granularidade de passo