Avaliando agentes de uso de computador, passo a passo
Um passo a passo da avaliação humana para agentes de uso de computador e de GUI no Potato: julgando cada ação, verificando a ancoragem do clique na captura de tela e revisando chamadas de ferramentas uma de cada vez.
Um agente de uso de computador lê uma captura de tela, decide uma ação e clica. Avaliar um deles significa verificar cada passo: a ação estava certa e o clique de fato caiu no elemento que ele nomeou — não apenas se a tarefa acabou tendo sucesso. O sucesso da tarefa esconde o clique que acertou o botão errado mas avançou mesmo assim, e a ação que estava certa por sorte. O Potato revisa essas execuções com uma superfície de trajetória de GUI feita sob medida e uma revisão de chamadas de ferramentas, ambas configuradas em YAML.
Um agente de uso de computador — também chamado de agente de GUI ou de SO — vê a tela como pixels ou um DOM e age através dos mesmos controles que uma pessoa tem. Benchmarks como o OSWorld, o ScreenSpot e o AndroidWorld pontuam a conclusão de tarefas automaticamente. A pontuação automática é barata e vale a pena rodar, mas não consegue dizer por que uma execução falhou, nem detectar a aprovação por sorte. É essa a lacuna que a revisão humana por passo preenche.
 Julgue a ação e se o clique caiu no elemento que ela nomeou
Julgue a ação e se o clique caiu no elemento que ela nomeou
O que você de fato julga em uma trajetória de GUI?
Cada passo associa uma captura de tela (o que o agente viu) a uma ação (o que ele fez). Você julga a ação e, quando o passo carrega coordenadas de clique, verifica o marcador de ancoragem que o Potato desenha na captura de tela:
- Correção da ação — correta, elemento errado, ação errada ou alucinada.
- Ancoragem do clique — as coordenadas caíram no elemento que a ação nomeou?
- Resultado — a execução concluiu a tarefa e em qual passo ela deu errado pela primeira vez?
 Revise cada passo: correção da ação mais ancoragem do clique na captura de tela
Revise cada passo: correção da ação mais ancoragem do clique na captura de tela
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot
action_key: action
coord_space: normalized
verdict_options: [correct, wrong_element, wrong_action, hallucinated]Cada passo fornece screenshot, action e, opcionalmente, x/y (ou um click: {x, y} aninhado). O marcador de ancoragem é a parte que as métricas automatizadas mais costumam deixar passar: um modelo pode emitir o rótulo de ação certo enquanto clica dez pixels fora do alvo, e um aprovado/reprovado na tela final nunca vai revelar isso.
Por que o primeiro passo errado importa mais do que o resultado final?
Porque esse é o passo que você corrigiria ou treinaria. Uma execução que falha no passo 9 porque o passo 3 leu mal uma caixa de diálogo é, na verdade, um problema do passo 3, e rotulá-la no passo 9 ensina a lição errada. Capturar a primeira divergência é a mesma ideia por trás dos modelos de recompensa de processo: um sinal em cada passo localiza o erro em vez de colapsar a trajetória inteira em um único número.
Como reviso as chamadas de ferramentas de um agente?
Os agentes de GUI também chamam ferramentas e funções, e essas falham de suas próprias maneiras: intenção certa, ferramenta errada; ferramenta certa, argumentos malformados; chamada certa, ordem errada. O esquema tool_call_review extrai cada chamada do trace e a coloca em um cartão com o nome da ferramenta e os argumentos formatados, de modo que você as julga uma de cada vez (espelhando o BFCL v4 / MCPMark).
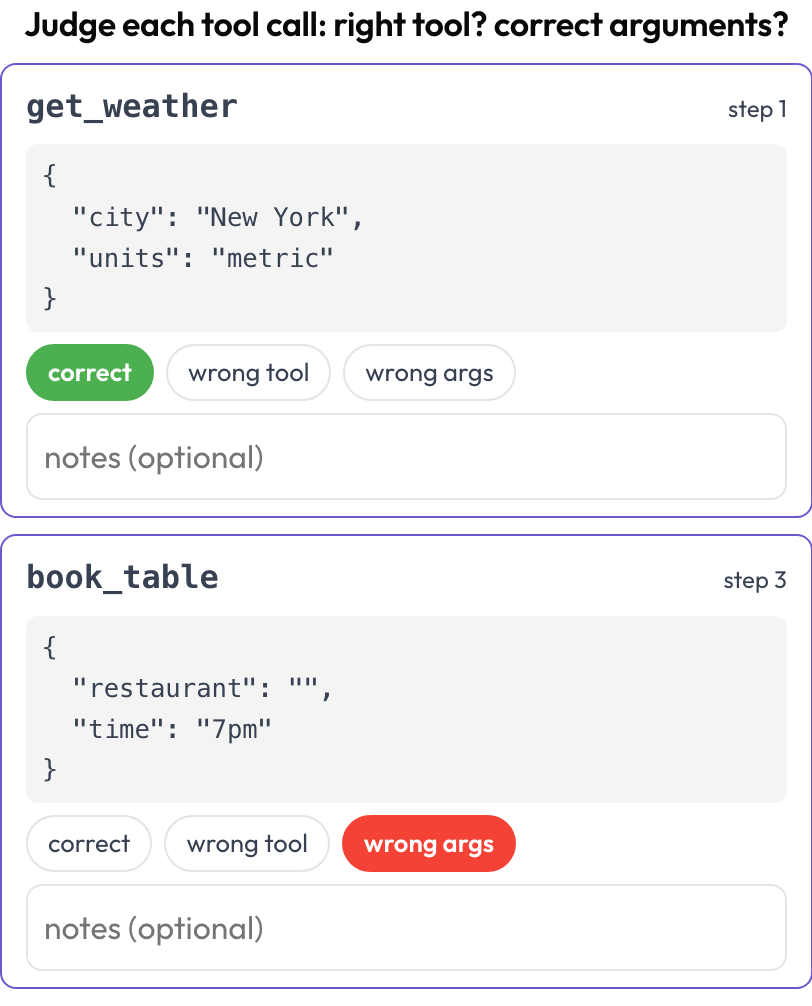 Julgue cada chamada de ferramenta: ferramenta certa, argumentos corretos, ordem certa
Julgue cada chamada de ferramenta: ferramenta certa, argumentos corretos, ordem certa
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order]As chamadas de ferramentas são extraídas em tempo de renderização do campo tool_calls, tool_call ou action de cada passo, então uma trajetória que mistura cliques de UI e chamadas de API pode ser revisada em ambos os eixos em uma única tarefa.
Como faço a configuração?
Cada superfície inclui um exemplo executável em examples/agent-traces/. Aponte o Potato para um deles para ver o esquema com dados de exemplo:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/gui-trajectory/config.yaml -p 8000Seus próprios dados entram como uma lista de passos, cada um com uma URL de captura de tela ou data-URI e uma string de ação. Para agentes web mais amplos que trabalham a partir de páginas renderizadas em vez de capturas de tela brutas, veja Avaliação de agentes web.
Leitura adicional
- Avaliação de agentes multimodais — a referência completa de esquemas para agentes de GUI, voz, vídeo e documentos
- Avaliando agentes de uso de computador e multimodais — o guia, com uma tabela de seleção de esquemas
- Avaliando agentes de voz e vídeo — a outra metade das superfícies multimodais
- Potato 2.6.2: Uma suíte completa e de código aberto para avaliação de agentes — toda a linha 2.6.x