Avaliando agentes de voz e vídeo
Um passo a passo da avaliação humana para agentes de fala, vídeo e documentos no Potato: pontuando a alternância de turnos em uma linha do tempo de duas faixas, ancorando eventos de vídeo com IoU ao vivo, marcando erros de fala e demarcando a estrutura de tabelas.
Agentes que falam, assistem a vídeo e leem documentos falham de maneiras que uma caixa de texto não consegue mostrar. Os erros de um agente de voz vivem nas costuras entre turnos; a resposta de um agente de vídeo é um intervalo de tempo, não uma frase; o erro de um agente de documentos é uma célula de tabela lida errado. Cada um deles precisa de uma superfície de revisão moldada para a modalidade. O Potato adiciona quatro dessas superfícies — voz, vídeo, fala e documento — ao lado de suas exibições já existentes de imagem e áudio. A referência completa é Avaliação de agentes multimodais.
 Um widget de texto simples não consegue expressar um barge-in, um intervalo de evento ou uma célula de tabela
Um widget de texto simples não consegue expressar um barge-in, um intervalo de evento ou uma célula de tabela
Como avalio a alternância de turnos de um agente de voz?
Os agentes falados quebram nos limites: cortando o usuário, falando por cima dele ou pausando por tanto tempo que o usuário desiste. O esquema voice_interaction dispõe a conversa como uma linha do tempo de duas faixas — uma faixa do usuário e uma faixa do agente — e destaca as regiões de sobreposição em que ambos falam ao mesmo tempo (Full-Duplex-Bench, 2025). Você classifica cada sobreposição e avalia a alternância de turnos geral; o áudio toca inline quando fornecido.
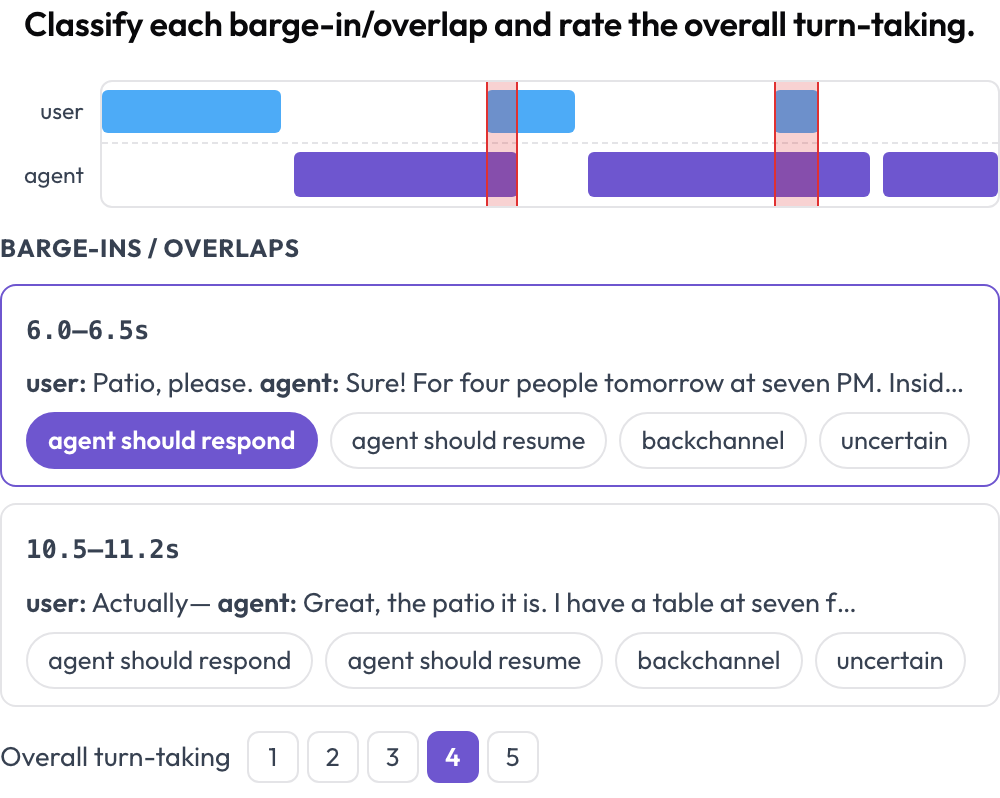 Linha do tempo de voz de duas faixas com detecção de barge-in e pontuação de alternância de turnos
Linha do tempo de voz de duas faixas com detecção de barge-in e pontuação de alternância de turnos
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5As sobreposições são calculadas a partir dos tempos dos turnos em tempo de renderização, então uma conversa full-duplex que uma transcrição plana achataria em "os dois disseram coisas" torna-se um conjunto de momentos concretos e rotuláveis.
Como pontuo a ancoragem temporal de um agente de vídeo?
A resposta de um agente de vídeo para "quando o objetivo acontece?" é um intervalo, então você o pontua como tal. O esquema temporal_grounding oferece um cursor de busca onde você marca o [start, end] de referência para cada prompt de evento, capturando a posição da reprodução ou digitando segundos. Quando os dados carregam o intervalo previsto pelo modelo, um IoU ao vivo e uma minilinha do tempo de duas barras se atualizam conforme você ajusta (TimeScope, 2025).
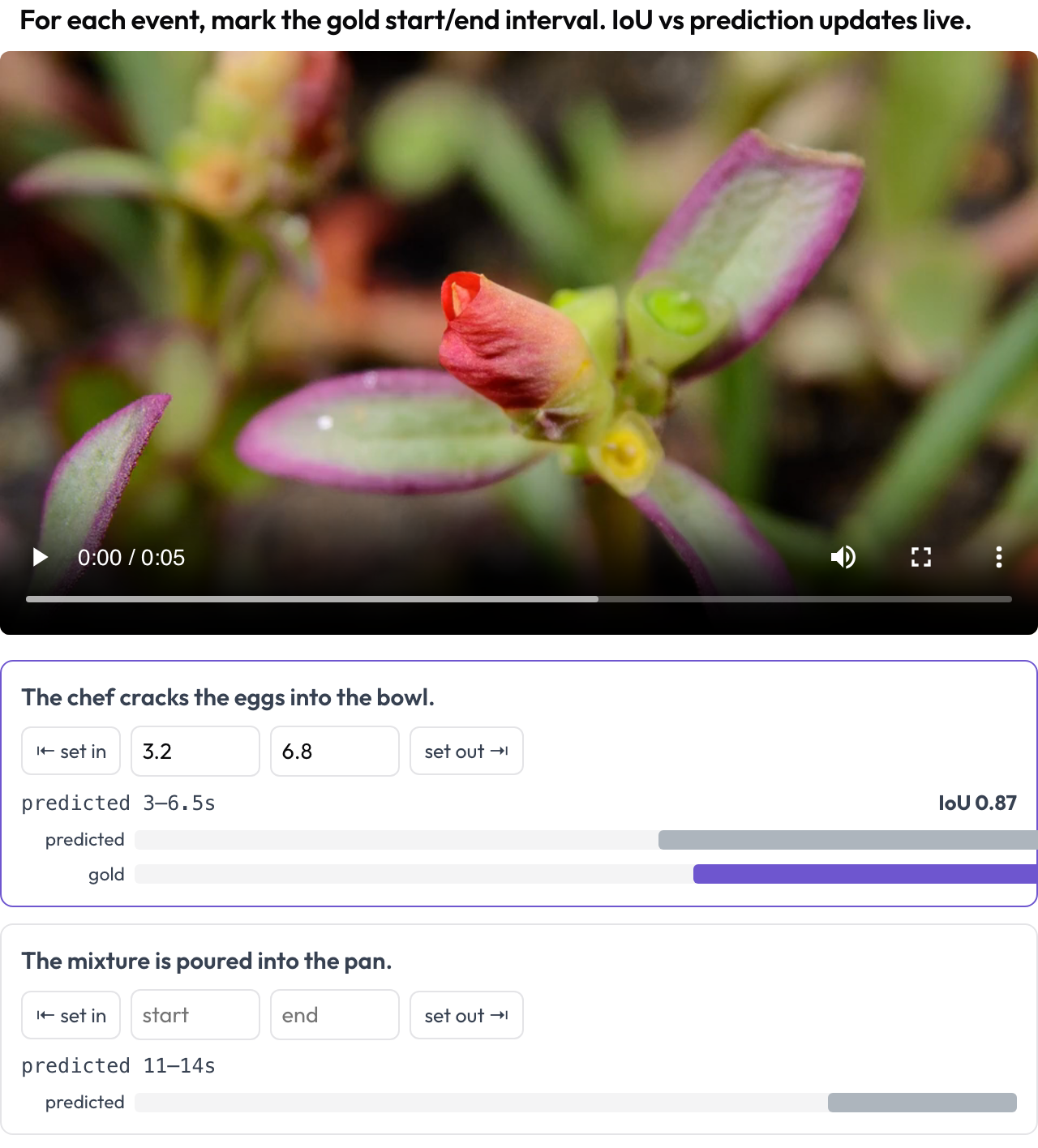 Marque os intervalos de eventos de referência no vídeo com um IoU ao vivo contra a previsão do modelo
Marque os intervalos de eventos de referência no vídeo com um IoU ao vivo contra a previsão do modelo
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsIsso é feito para a localização prevista contra a de referência, que é um trabalho diferente da rotulagem geral de segmentos: você está pontuando quão próximo o trecho do modelo está da verdade, e ver o IoU se mover enquanto você arrasta a fronteira torna isso imediato.
E quanto a transcrições de fala, raciocínio e tabelas?
Mais três superfícies cobrem o restante do espectro multimodal:
- Transcrições de fala (
speech_transcript): cada segmento alinhado no tempo é um cartão; você marca erros de ASR/TTS, pronúncias incorretas e disfluências e corrige o texto inline (Speak & Improve, 2025). Este é o complemento em nível de segmento da visão de alternância de turnos. - Raciocínio intercalado (
multimodal_reasoning): um trace de texto-imagem-ferramenta renderizado como blocos tipados; você avalia a coerência de cada passo e sinaliza alucinações visuais onde o raciocínio não decorre da imagem (Multimodal RewardBench 2, 2025). - Tabelas de documentos (
table_grid): você define as dimensões da grade e clica nas células para marcar seu papel — dado, cabeçalho de coluna, cabeçalho de linha, vazia — capturando a estrutura que caixas delimitadoras não conseguem.
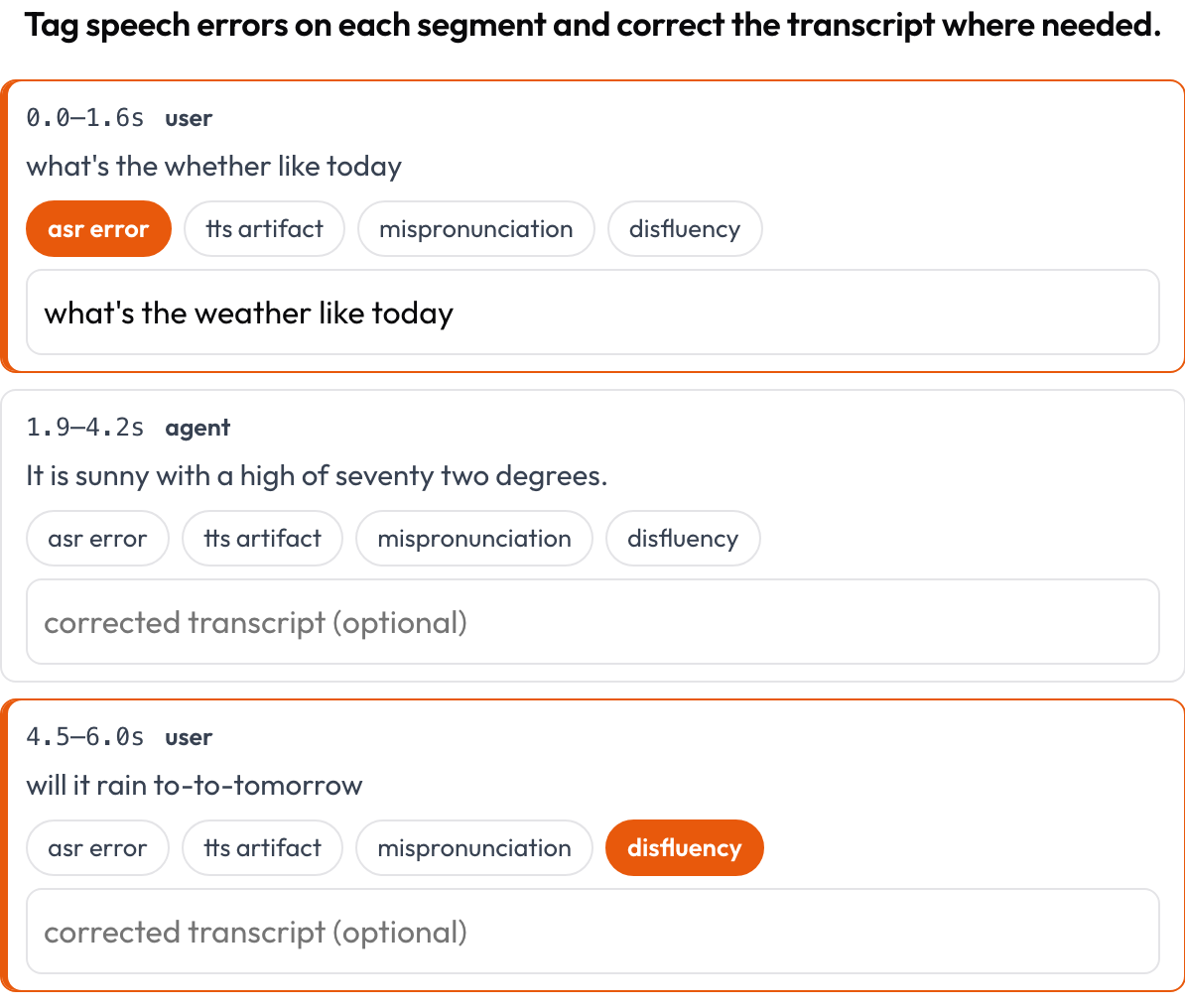 Marque erros de ASR/TTS/pronúncia por segmento e corrija a transcrição inline
Marque erros de ASR/TTS/pronúncia por segmento e corrija a transcrição inline
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true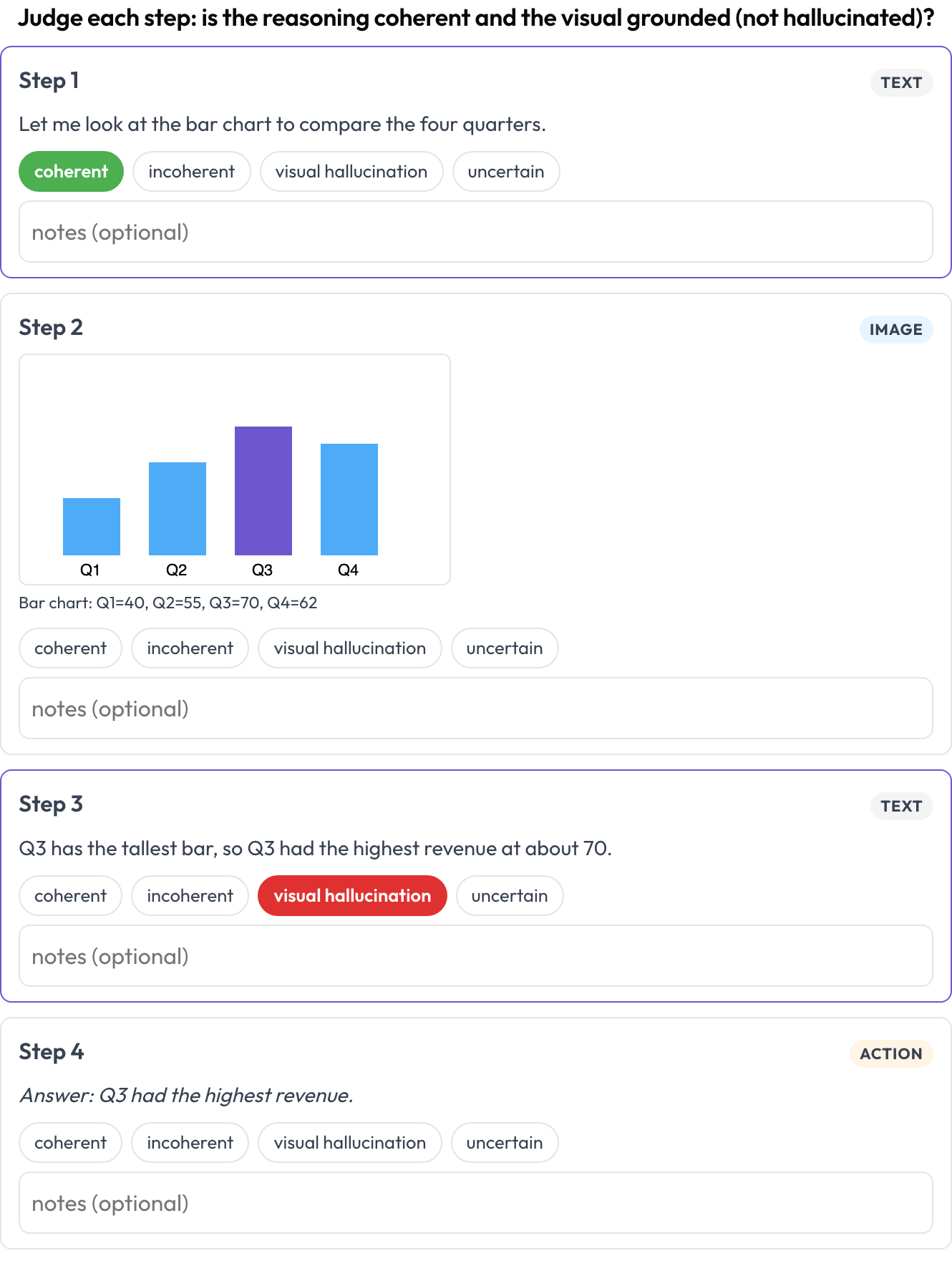 Avalie cada passo de um trace de raciocínio de texto-imagem-ferramenta quanto à coerência e à alucinação visual
Avalie cada passo de um trace de raciocínio de texto-imagem-ferramenta quanto à coerência e à alucinação visual
Vários desses esquemas podem rodar na mesma tarefa, então uma única execução de agente de documentos pode ser pontuada quanto à estrutura da tabela e à coerência do raciocínio ao mesmo tempo.
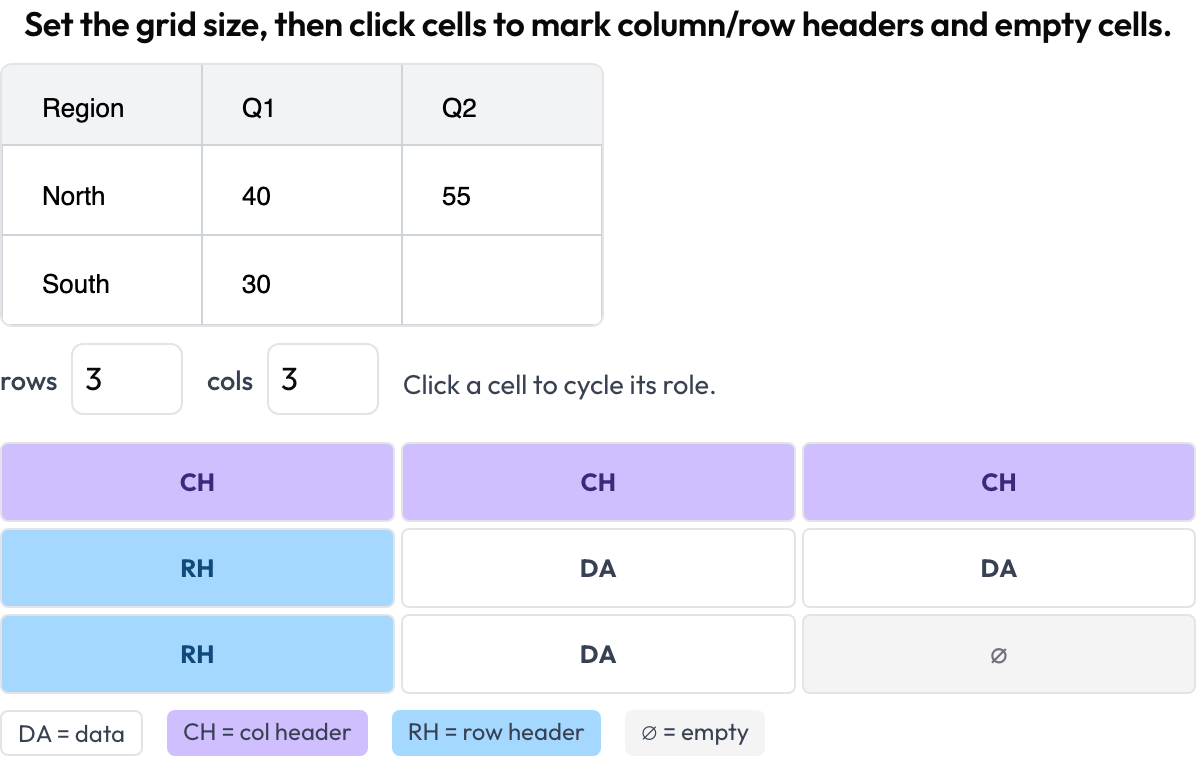 Anote a estrutura de células de tabelas de documentos: cabeçalhos de coluna e de linha, dados e células vazias
Anote a estrutura de células de tabelas de documentos: cabeçalhos de coluna e de linha, dados e células vazias
Como faço a configuração?
Cada superfície inclui um exemplo executável em examples/agent-traces/:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000Seus dados entram como turnos, segmentos ou eventos com timestamps; a superfície deriva sua linha do tempo a partir deles em tempo de renderização. Para agentes de GUI e de SO, a peça companheira é Avaliando agentes de uso de computador.
Leitura adicional
- Avaliação de agentes multimodais — a referência completa de esquemas
- Avaliando agentes de uso de computador e multimodais — o guia, com uma tabela de seleção de esquemas
- Avaliando agentes de uso de computador, passo a passo — a metade de GUI e SO das superfícies multimodais
- Potato 2.6.2: Uma suíte completa e de código aberto para avaliação de agentes — tudo na linha 2.6.x