評価から訓練データへ:SFT と DPO のための軌跡編集
ほとんどのエージェント評価はスコアで止まる。Potato 2.6 の trajectory_edit スキーマは、アノテーターが誤ったステップを評価する代わりに書き直し、各修正を教師ありファインチューニングのターゲットと DPO の選好ペアとしてエクスポートできるようにする。
エージェントの評価はたいてい数字で終わる。アノテーターが軌跡を読み、3 番目のステップが間違っていると判断し、低いスコアを記録するかエラータイプをタグ付けする。その数字は、エージェントがどれくらいの頻度で失敗するかを測るには役立つ。しかしエージェントを修正する役にはあまり立たない。なぜなら「3 番目のステップが間違っていた」は、3 番目のステップがどうあるべきだったかをモデルに教えてくれないからだ。
まもなくリリースされる Potato 2.6 は、採点ではなく答えを求めるスキーマを追加する。trajectory_edit を使うと、アノテーターは agent trace(エージェントの軌跡)のステップを書き直すことができ(しくじった推論ステップを直したり、打ち間違えた tool call(ツール呼び出し)を修復したり、弱い最終回答を強化したりする)、Potato は修正後の軌跡を元の軌跡の隣に保持する。続いて trajectory_correction エクスポーターが、各 (original, corrected) ペアを訓練データに変換する。すなわち 教師ありファインチューニング のターゲットと、直接選好最適化 の選好ペアである。
本稿が扱うのは、まさにこの転換だ。評価ツールを訓練データ生成ツールへと変え、人間のアノテーターの時間が生み出すものを変える。すなわちラベルではなく、学習信号を生み出すのだ。
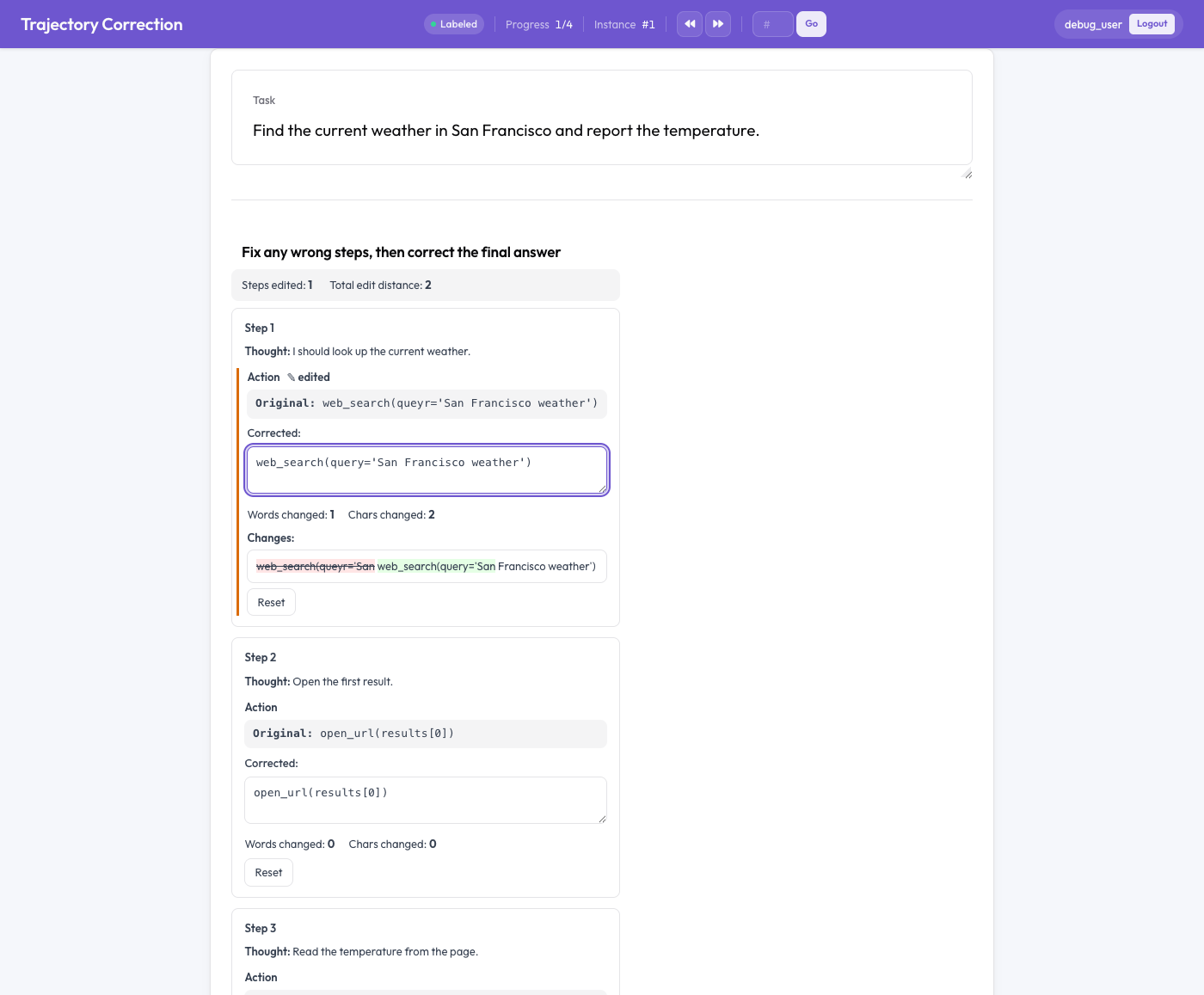 軌跡修正エディター
軌跡修正エディター
採点ではなく編集する
各エージェントステップは、2 つの半分からなるカードとして表示される。読み取り専用の**元(original)テキストと、元の内容があらかじめ入力された編集可能な修正(corrected)**ボックスだ。アノテーターは修正ボックスを直接編集する。入力すると、3 つのことが同時に起こる。
- ライブの語単位の差分が、挿入を緑で、削除を赤の取り消し線でハイライトし、
- 変更された語数と文字数がカウントされ、
- 変更されたフィールドには「edited(編集済み)」フラグが表示される。
アノテーターが考えを変えた場合は、「Reset」ボタンでそのフィールドを元の内容に戻せる。重要なのは、何も必須ではないということだ。軌跡を読んで正しいと判断したアノテーターは、それをそのまま放置すればよく、編集されていない軌跡は訓練ペアを生み出さない。信号は本物の修正からのみ生じる。
設定
このスキーマは、データ内のステップリストを指し示し、どのフィールドが編集可能かを指定する。
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerデフォルトでは、各ステップの action だけが編集可能だ。アノテーターにエージェントのアクションだけでなく推論も修正してほしい場合は thought を editable_fields に追加し、各変更に書面での根拠を添えてほしい場合は require_reason_on_edit: true を設定する。これは修正そのものがレビューされる場合に役立つ。
データ形式は、あなたの軌跡がすでに持っている形そのままでよい。このスキーマは steps_key で指定されたフィールドからステップを読み取る。各ステップはオブジェクトであり、そのフィールドは編集できる。
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}queyr のタイプミスは、アノテーターが修正ボックスで直すまさにそうした類のものであり、モデルが学べる 1 トークンの修正を生み出す。
リポジトリのルートから、同梱のサンプルを実行する。
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000修正から訓練ファイルへ
trajectory_correction エクスポーターは、それぞれ異なる下流の用途に向けて 3 つのファイルを書き出す。
trajectory_corrections.jsonは完全な記録を保持する。original_trace、再構成されたcorrected_trace、そして編集距離と理由を伴うフィールドごとのeditsだ。これがあなたの監査証跡となる。trajectory_sft.jsonlは編集された軌跡 1 件につき 1 行で、{"prompt": <task>, "completion": <corrected_trace>}を持つ。修正後の軌跡は、モデルが再現するようにファインチューニングされるターゲットになる。trajectory_dpo.jsonlは編集された軌跡 1 件につき 1 行で、{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}を持つ。人間の編集が選好を定義する。すなわち修正版が原版より好まれる。
 編集がどのように SFT と DPO の訓練データになるか
編集がどのように SFT と DPO の訓練データになるか
DPO ファイルは、ここでは無償で手に入る部分だ。通常の選好データのパイプラインでは、より良い応答と対にするために、より悪い応答を生成または収集しなければならない。ここでは、より悪い応答はすでに存在する(エージェントが生成した元の軌跡がそれだ)し、人間の編集が、修正版のほうが好まれるという証拠になる。1 件のアノテーションが、SFT のターゲットと DPO のペアの両方を生み出す。
何がスキップされるか、そしてそれがなぜ重要か
編集されていない軌跡はカウントされるが、SFT および DPO ファイルからは除外される。変更のない軌跡で訓練してもモデルは何も学ばないし、さらに悪いことに、chosen == rejected のペアで選好データセットを溢れさせ、ノイズを加えてしまう。スキップされた件数はエクスポートの統計に依然として表示されるので、そのバッチのうちどれだけがすでに正しかったかが分かる。これ自体、エージェントの品質に関する有用な信号だ。複数のアノテーターがいる場合、ある軌跡を編集した各アノテーターがそれぞれ 1 件の SFT/DPO レコードを生み出すので、独立した修正がすべて寄与する。
いくつかの鋭い角
- 差分は語単位だ。空白のないコードのような tool call(ツール呼び出し)では、1 文字だけの修正であっても、単一のトークンが丸ごと変更されたように表示されることがある。そうした場合は文字距離カウンターが正確な信号だ。密なツール呼び出しでは、視覚的な差分よりもこちらを信頼してほしい。
- 編集は採点と自然に組み合わさる。同じ軌跡上でステップごとの正誤ラベルやエラー分類体系も欲しい場合は、ステップレベルの採点スキーマをエディターと並べて実行すれば、一度のパスで診断と修正の両方が得られる。
なぜこれが重要なのか
エージェントのチューニングループには、「本来どうすべきだったか」というステップに常にボトルネックがあった。スコアはモデルがどこで失敗するかを教えてくれるが、訓練すべき修正後の振る舞いを生み出してはくれない。そのため、チームは結局、合成の修正を書いたり、2 度目のラベリングの作業に費用を払ったりすることになる。軌跡編集は、それを評価そのものの中へ畳み込む。軌跡を採点していたはずの同じ人間が、代わりにそれを修復し、その修復が訓練データになる。
軌跡編集は Potato 2.6 で出荷される。オプションの全リストは 軌跡編集ドキュメント を、編集前に軌跡を素早く読むには eval_trace 表示 を、エクスポーターの詳細は エクスポート形式リファレンス を参照してほしい。