Potato に質的コーディングを:コードブック、メモ、イン・ヴィヴォ・コード
QDA モードを紹介します。Potato 2.6 で登場予定の質的データ分析ワークスペースで、生きたコードブック、イン・ヴィヴォ・コーディング、分析メモ、ケース、そしてコーパス全体に対する全文検索を備えています。
インタビューの書き起こしをコーディングしたことがあれば、そのソフトウェア事情はご存じでしょう。質的データ分析(QDA)向けの本格的なツール、たとえば NVivo、ATLAS.ti、MAXQDA、Dedoose は、高機能ですが高価です。デスクトップに常駐し、プロジェクトを独自形式のファイルに閉じ込め、共同作業をライセンス交渉に変えてしまいます。結局、多くの研究者は表計算ソフトでコーディングし、途中で筋を見失うことになります。表計算ソフトには「コード」とは何かという概念がないからです。
Potato はその反対側、つまり NLP や機械学習データセット向けのテキストアノテーションツールとして出発しました。ここ数回のリリースで、質的ワークフローに必要な部品が育ってきました。パッセージにかけるスパン、共有コードブック、一致度の指標です。近く公開される 2.6 リリースは、それらを束ねて、質的研究者が実際に働くやり方に合わせたモードに仕上げます。
本稿では QDA モードを順に見ていきます。何が有効になるのか、各部品がどう噛み合うのか、そして設定ファイルがどんな見た目になるのかです。リファレンスが必要なら、QDA モードのドキュメントに全オプション一覧があります。
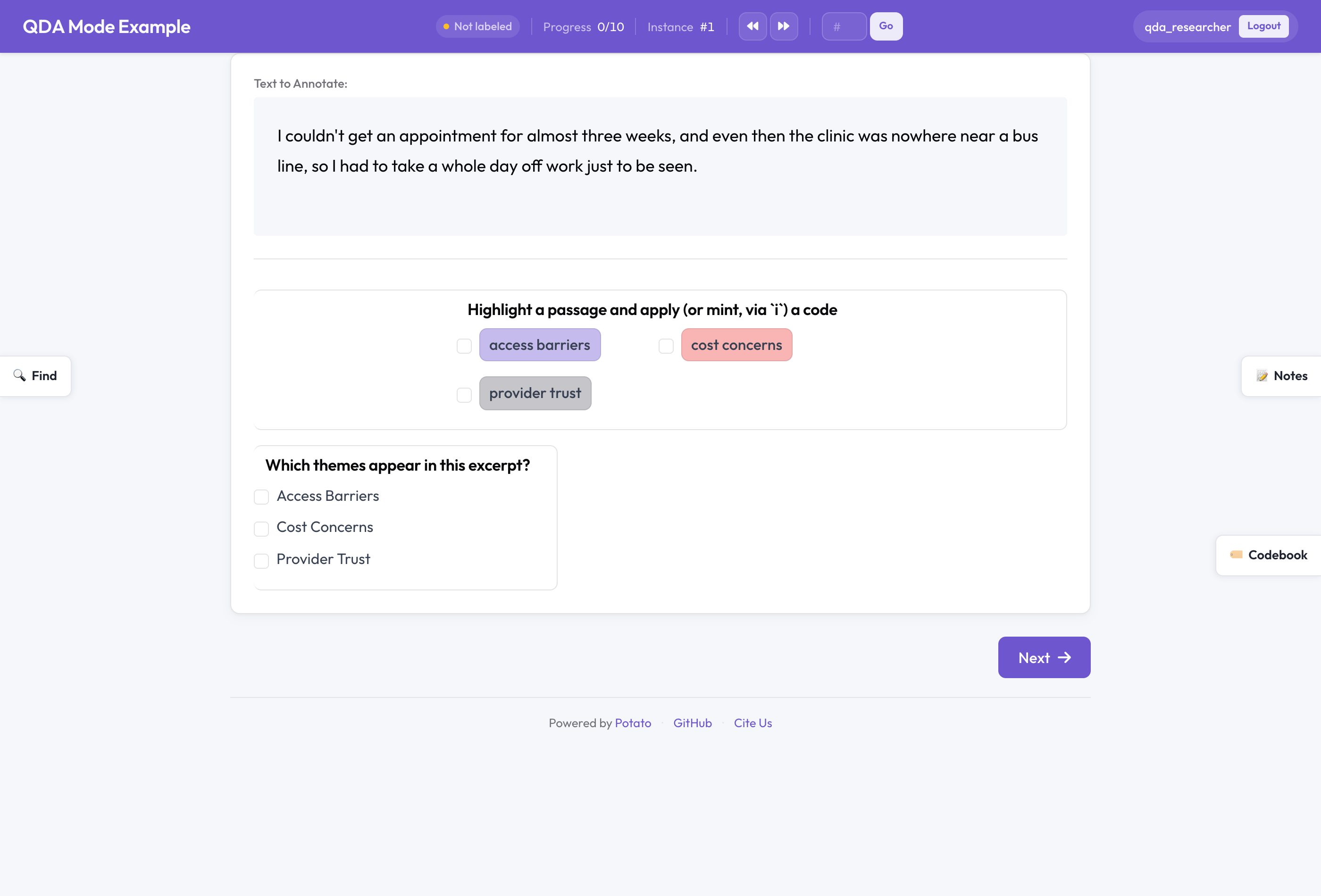 QDA モードの Potato
QDA モードの Potato
ひとつのスイッチ、質的なデフォルト
Potato の仕組みの大部分は、まったく異なるタスク間で共有されています。NER データセットの固有表現にラベルを付けるのと同じスパンスキームが、インタビューのパッセージにもラベルを付けられます。この 2 つの仕事の違いは機能セットではなく、構えにあります。クラウドソーシングの NER プロジェクトは、固定のラベルセットと、一致度を測るためのオーバーラップサンプリングを求めます。一方、20 件のインタビューを一人でコーディングする研究者は、読みながらコードを生み出し、目にしたものについて私的なメモを残したいのです。
QDA モードは、その後者の構えを前提とする単一のスイッチです。
qda_mode:
enabled: true # compose codebook + memos + cases + searchqda_mode.enabled: true を設定すると、Potato の汎用機能が質的なデフォルトへ切り替わります。コードブックはロックされる代わりに、コーディング中に編集できるようになります。メモのサイドバーがオンになります。ケースが自動検出付きでオンになります。コードブック連携と印を付けた任意のスパンスキームで、イン・ヴィヴォ・コーディングが利用できるようになります。
| 機能 | 標準デフォルト | QDA モード下 |
|---|---|---|
| コードブックモード | fixed | open:作業しながらコードの追加・改名・色変更・移動・削除が可能 |
| メモのサイドバー | オフ | オン |
| ケース | オフ | オン、自動検出付き |
| アノテーターの検索と取得 | オフ | 利用可能(search.annotator_claim: true) |
| イン・ヴィヴォ・コーディングのキー | i | コードブック連携の任意のスパンスキームで有効 |
これらは固定されているわけではありません。QDA モードは出発点を変えるだけで、どのデフォルトも上書きできます。唯一の例外はガードレールです。Prolific や Mechanical Turk のようなクラウドソーシングのバックエンドを接続すると、Potato はコードブックを強制的に fixed にロックします。そうすることで、有償のアノテーターが共有スキームをあなたの知らないところで作り変えられないようにしています。
各部品
生きたコードブック
グラウンデッド・セオリー流のコーディングでは、コードブックは前もって書き上げるものではありません。読むにつれて成長していきます。繰り返し現れるアイデアに気づいて名前を付け、一週間後に 2 つのコードが実は同じものだと気づいてマージする、という具合です。
スパンスキームに印を付けると、それはコードブックの一部になります。
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]これらの labels は出発点のセットであって、檻ではありません。open コードブックモードでは、作業しながらコードを追加・改名・色変更・移動・削除できます。extensible モードでは、コーダーはコードを追加できますが、共有されたコードは削除できません。fixed は、スキームを固めた段階向けのロックされた定番モードです。
イン・ヴィヴォ・コーディング
イン・ヴィヴォ・コーディングは、参加者自身の言葉をそのままコードにします。誰かが「とにかく折り返しの電話がもらえなかった」と言えば、「折り返しの電話がもらえなかった」がそのままコードになります。
コードブック連携のスパンスキーム上でパッセージを選択し、イン・ヴィヴォ・キー(codebook_invivo_key、デフォルトは i)を押します。Potato はハイライトしたテキストから直接コードを鋳造します。コーパス全体でこれを繰り返すと、断片化が敵になります。「折り返しなし」「折り返しの電話がもらえなかった」「結局かかってこなかった」が、ひとつのアイデアに対する 3 つのコードになってしまうのです。コードコンポーザーはこれに歯止めをかけます。入力中に重複に近いコードを浮かび上がらせ、新たなコードを生む代わりに既存のコードを再利用するよう促します。
メモ
メモなしのコーディングは、コードの背後にある推論を失います。メモは、インスタンスや特定のテキスト選択範囲に紐づく分析メモです。私的に保つことも、チームと共有することもできます。「なぜこう(このように)コーディングしたのか」が宿る場所であり、引用と一緒にエクスポートされるので、監査証跡がプロジェクトの後も残ります。
ケース
ケースは、抜粋を分析単位にまとめます。参加者、ドキュメント、現地訪問などです。抜粋がまとめられると、ケースレベルの属性が引き上げられ、参加者の変数に対してコードを集計できるようになります。各インタビューに condition フィールドが付いていれば、管理画面のクロス集計で、あるコードが条件ごとにどう分布しているかを示せます。
cases:
enabled: true
key: participant_id
attributes: [condition]検索
コーパスは、ある語のどの出現箇所にも飛べてこそナビゲートできます。QDA モードには、データセット全体に対する FTS5 全文検索が含まれています。annotator_claim: true にすると、コーダーは任意の検索ヒットを自分のキューへ直接引き込めます。これが、一人の分析者が前から順に読むのではなく、テーマごとにコーパスを進めていくやり方です。
search:
enabled: true
annotator_claim: trueどう噛み合うのか
内部では、コードブック、メモ、ケース、検索はすべて同じプロジェクトデータベースを読み書きします。そのため、ある場所で鋳造されたコードは、ほかのあらゆる場所で即座に検索・エクスポート可能になります。
 QDA モードが共有ストアの上で各部品をどう組み合わせるか
QDA モードが共有ストアの上で各部品をどう組み合わせるか
完全な設定例
小さいながらも完結した研究の例です。cases、search、メモのブロックは省略可能で(QDA モードはケースとメモをすでにオンにしています)、ケースキーのようなデフォルトを調整したいときにだけ書きます。
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]2.6 をインストールしたら、リポジトリのルートから実行します。
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000コーディング結果を取り出す
2 つのエクスポーターが、コーディング済みのデータを質的論文に必要な成果物へと変えます。
codebookは、各コードについて 1 行を出力し、その階層、説明、色、使用回数を含みます。quotation_reportは、コーディングされたスパンごとに 1 行を出力します。引用、その文字オフセット、出典のインスタンス、コーダーです。include_memos=trueを追加すると、メモも付け加えられます。
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csv同じ素材を複数の人がコーディングする場合は、信頼性の数値が欲しくなるでしょう。Potato はコードについて Cohen's と Fleiss' kappa を報告します。この機能は、これらのエクスポーターとともに 2.5 リリースで登場しました。
どこに位置づけられるか
QDA モードは、あらゆる軸で NVivo を機能面で上回ろうとはしていません。提供するのは別のトレードオフです。無料、オープンソース、Web ベース、共同作業可能で、機械学習のアノテーションやエージェント評価と同じツールの中に収まっています。すでにラボでラベリングのために Potato を動かしているなら、質的コーディングは、ライセンスされた別個のデスクトップソフトではなく、設定ブロックひとつ分の距離になりました。
QDA モードは Potato 2.6 に搭載されます。完全なドキュメントはすべてのオプションを網羅し、アノテーター間一致度のガイドは信頼性の指標を解説します。