Potato 2.6.2 : une suite complète et open source d'évaluation d'agents
La série 2.6.x fait de Potato une plateforme d'évaluation d'agents complète et gratuite : ingestion de traces depuis OpenTelemetry, LangGraph, CrewAI et AutoGen, annotation d'équipes multi-agents avec un graphe d'interaction cliquable, schémas d'agents multimodaux pour le GUI, la voix et la vidéo, ainsi qu'une arène de modèles, un contrôle en CI et de la curation.
Potato 2.6 a apporté la première vague d'évaluation d'agents : calibration du LLM-juge, édition de trajectoires pour les données d'entraînement et l'affichage à trois panneaux eval_trace. Les versions mineures 2.6.x parues depuis comblent le reste. Avec la 2.6.2, Potato est une plateforme d'évaluation d'agents complète : vous pouvez capturer des traces depuis vos propres agents, annoter des agents seuls, des équipes multi-agents et des agents multimodaux, les juger avec des LLM auxquels vous pouvez vous fier, classer des modèles dans une arène et bloquer des releases en CI. Tout cela se configure en YAML et reste sur votre propre serveur.
 Évaluation multi-agents de Potato
Évaluation multi-agents de Potato
La plupart de ces fonctionnalités sont aujourd'hui payantes sur des plateformes hébergées. Potato les propose gratuitement et en auto-hébergement. Voici ce qui est arrivé tout au long de la série 2.6.x.
 La suite d'évaluation d'agents 2.6.x, de bout en bout
La suite d'évaluation d'agents 2.6.x, de bout en bout
Faire entrer les traces : un SDK de capture et des standards ouverts
L'évaluation commence par de vraies exécutions. Le nouveau SDK potato_trace instrumente n'importe quel agent : décorez une fonction avec @traceable (synchrone ou asynchrone) et les appels imbriqués sont capturés puis envoyés au point d'ingestion de Potato, avec un export OpenTelemetry optionnel. Potato ingère aussi les spans OpenTelemetry / OpenInference ainsi que les formats d'exécution LangGraph, CrewAI et AutoGen, de sorte que les traces du framework que vous utilisez déjà arrivent dans la file d'annotation sans code de liaison. Les nouvelles traces peuvent arriver via un webhook, un poller ou un répertoire surveillé, et deviennent assignables aux annotateurs au fur et à mesure.
Référence : SDK de traçage, Règles d'automatisation.
Voir toute l'équipe : l'évaluation multi-agents
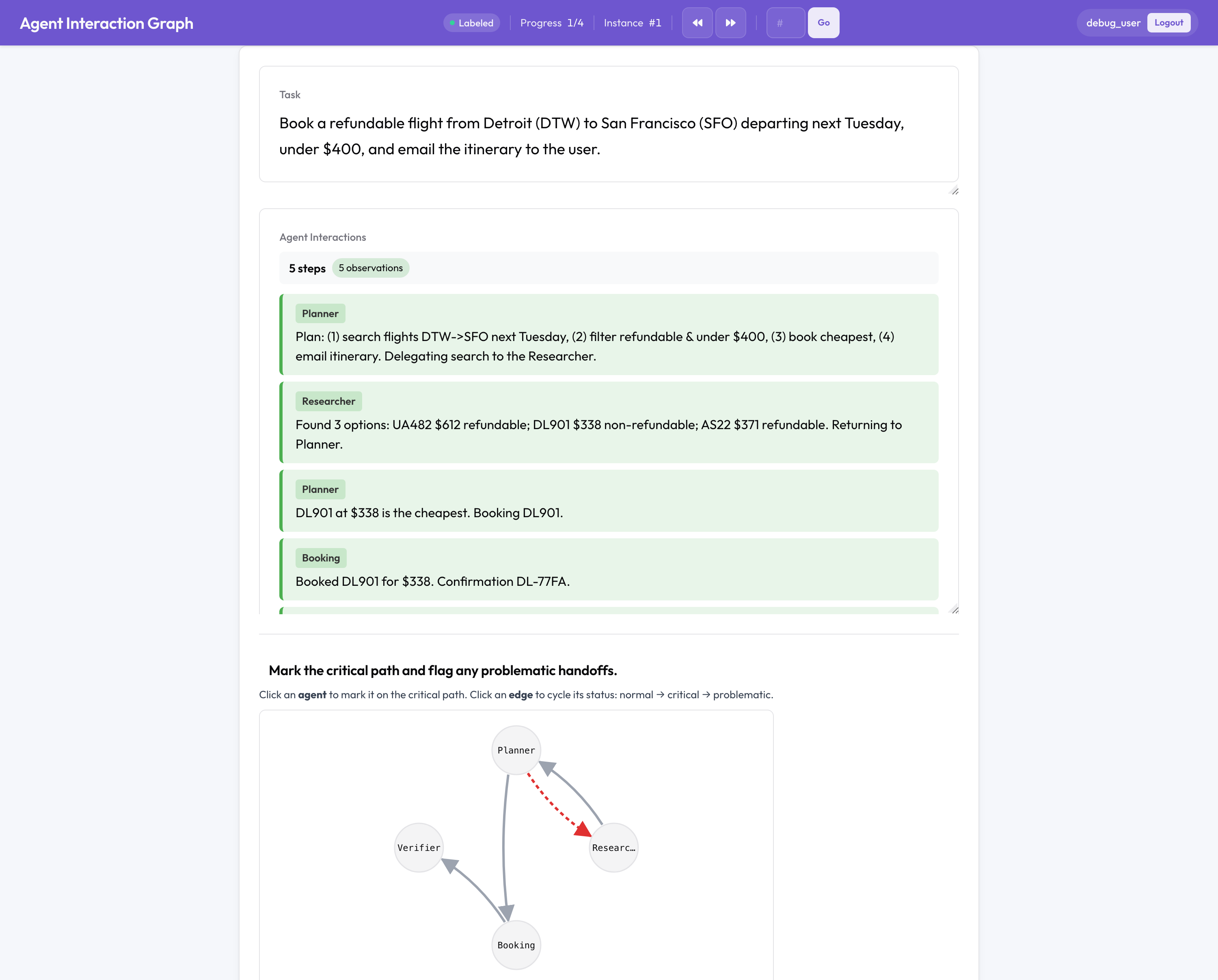
C'est la partie sans équivalent open source. Une exécution multi-agents échoue autrement qu'un agent seul : entre les agents, lors d'un passage de relais, dans la manière dont l'équipe a été organisée. Potato annote donc la structure de l'équipe plutôt qu'une transcription à plat :
- Un graphe d'interaction cliquable des agents et des passages de relais, où vous marquez le chemin critique et signalez les arêtes problématiques.
- Attribution de l'échec : choisissez l'agent responsable, l'étape décisive et la raison, le triplet (agent, étape, raison) issu des travaux d'attribution Who&When.
- Revue des passages de relais : chaque transfert de contrôle devient une carte pour signaler les désalignements inter-agents et noter la qualité.
- Tableaux de bord par agent et par équipe : fidélité au rôle, contribution et coordination par agent, plus des dimensions partagées d'équipe et des jalons.
- Une chronologie de contention des outils qui fait remonter les interblocages et les courses lorsque plusieurs agents touchent la même ressource en même temps.
- Étiquetage des comportements émergents pour la collusion, la pensée de groupe et les erreurs en cascade qui s'étendent sur plusieurs agents et tours.
 Attribution de l'échec : quel agent, quelle étape et pourquoi
Attribution de l'échec : quel agent, quelle étape et pourquoi
L'ensemble complet, avec le YAML de chacun, se trouve dans Évaluation d'équipes multi-agents, et l'analyse approfondie Déboguer les échecs multi-agents parcourt chaque surface de bout en bout. Le guide Comment évaluer les systèmes multi-agents explique quand utiliser quoi.
Au-delà du texte : l'évaluation d'agents multimodaux
Les agents pilotent désormais des interfaces graphiques, regardent des vidéos et tiennent des conversations parlées, et chacun a besoin d'une surface de revue qu'un simple widget texte ne peut offrir :
- Trajectoires GUI / computer-use : capture d'écran et action par étape, un verdict d'action et un marqueur d'ancrage du clic qui montre si le clic a atterri sur le bon élément.
- Chronologies vocales en duplex intégral : une chronologie utilisateur/agent à deux pistes avec détection des interruptions (barge-in) et notation du tour de parole.
- Ancrage temporel vidéo : marquez les intervalles d'événements de référence avec une IoU en direct par rapport à l'intervalle prédit par le modèle.
- Étiquetage des erreurs de transcription de la parole, raisonnement multimodal entrelacé avec signalement des hallucinations visuelles, et structure en grille de tableaux de documents.
 Revue de computer-use : justesse de l'action et ancrage du clic
Revue de computer-use : justesse de l'action et ancrage du clic
Deux analyses approfondies les détaillent : Évaluer les agents computer-use pour les agents GUI et OS, et Évaluer les agents vocaux et vidéo pour les agents parlés, vidéo et documentaires. La référence est Évaluation d'agents multimodaux, et le guide est Évaluer les agents computer-use et multimodaux.
Des juges auxquels vous pouvez vous fier, et une arène
Utiliser un LLM pour noter des sorties est une routine ; le travail de la série 2.6.x consiste à savoir jusqu'où lui faire confiance. La calibration du juge effectue une passe humaine en aveugle face aux étiquettes du modèle et rapporte la justesse, le kappa et l'erreur de calibration attendue (ECE). L'alignement du juge ajuste un juge unique sur vos étiquettes de référence. Et les évaluateurs programmatiques notent automatiquement les trajectoires et le texte (correspondance de trajectoire, justesse de l'usage des outils, LLM-juge sans référence et heuristiques) sans serveur en marche.
Pour la comparaison directe, l'Arène de modèles envoie une même invite à plusieurs modèles, collecte les préférences et construit un classement par taux de victoire entre OpenAI, Anthropic, Gemini, Ollama et vLLM.
Traiter l'évaluation comme du logiciel
Les briques opérationnelles rendent l'évaluation reproductible :
- Jeux de données et expériences : jeux d'évaluation versionnés, découpages et comparaison côte à côte des expériences avec deltas de régression.
- Évaluation en CI : un plugin pytest qui fait échouer le build quand un changement d'invite ou de modèle dégrade la qualité de l'agent au-delà d'un seuil.
- Règles d'automatisation : routez les traces de production entrantes vers des jeux de données, des évaluateurs ou la file d'annotation par règle.
- Curation sémantique : un index d'embeddings pour « trouver des traces comme cet échec » et des tranches dynamiques enregistrées.
Se le procurer
pip install --upgrade potato-annotationChaque nouvelle surface est livrée avec un exemple exécutable sous examples/agent-traces/, dont interaction-graph/, failure-attribution/, gui-trajectory/ et temporal-grounding/. Pointez Potato vers l'un d'eux pour voir le schéma à l'œuvre :
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000Si vous comparez des outils, la mise en regard dans Potato face à LangSmith et Langfuse et le guide Comparatif des outils d'annotation open source précisent où chacun s'inscrit. Vos questions et les formats de trace que nous devrions prendre en charge sont les bienvenus sur le dépôt GitHub.