Déboguer les échecs multi-agents : un parcours guidé
Comment trouver pourquoi un système LLM multi-agents a échoué avec Potato : le graphe d'interaction, l'attribution de l'échec, la revue des passages de relais, les tableaux de bord par agent, la chronologie de contention des outils et l'étiquetage des comportements émergents.
Quand une équipe d'agents échoue, le plus difficile n'est pas de remarquer l'échec : c'est de trouver quel agent l'a causé, à quelle étape, et de déterminer si le vrai problème était un mauvais passage de relais entre deux agents qui, chacun de leur côté, fonctionnaient très bien. Ce parcours passe en revue les six surfaces de Potato conçues pour cela, dans l'ordre où vous les utiliseriez réellement sur une exécution défaillante. Tout ici se configure en YAML et tourne sur votre propre serveur ; la référence complète des schémas est Évaluation d'équipes multi-agents.
Un système multi-agents est composé de plusieurs agents LLM aux rôles distincts — un planificateur, un développeur, un relecteur — qui s'échangent des messages et se passent le contrôle. La recherche sur les raisons de l'échec de ces systèmes, la taxonomie MAST (Why Do Multi-Agent LLM Systems Fail?), a constaté que la plupart des échecs sont inter-agents : une contrainte perdue lors d'un passage de relais, une équipe qui ne vérifie jamais son propre travail, des agents qui se parlent sans se comprendre. Une transcription de chat à plat masque précisément cela, car ce qui a mal tourné réside dans l'espace entre deux messages, pas à l'intérieur de l'un d'eux.
 L'échec est entre les agents, lors d'un passage de relais, pas à l'intérieur d'une transcription
L'échec est entre les agents, lors d'un passage de relais, pas à l'intérieur d'une transcription
Comment voir la structure d'une exécution multi-agents ?
Commencez par la forme de l'exécution, pas par le texte. Le schéma agent_interaction_graph rend toute l'exécution sous forme de graphe orienté : les nœuds sont les agents, les arêtes les passages de relais entre eux, les arêtes plus épaisses signifiant plus de trafic. Vous cliquez sur un nœud pour le marquer sur le chemin critique et sur une arête pour la faire passer de normale à critique puis à problématique.
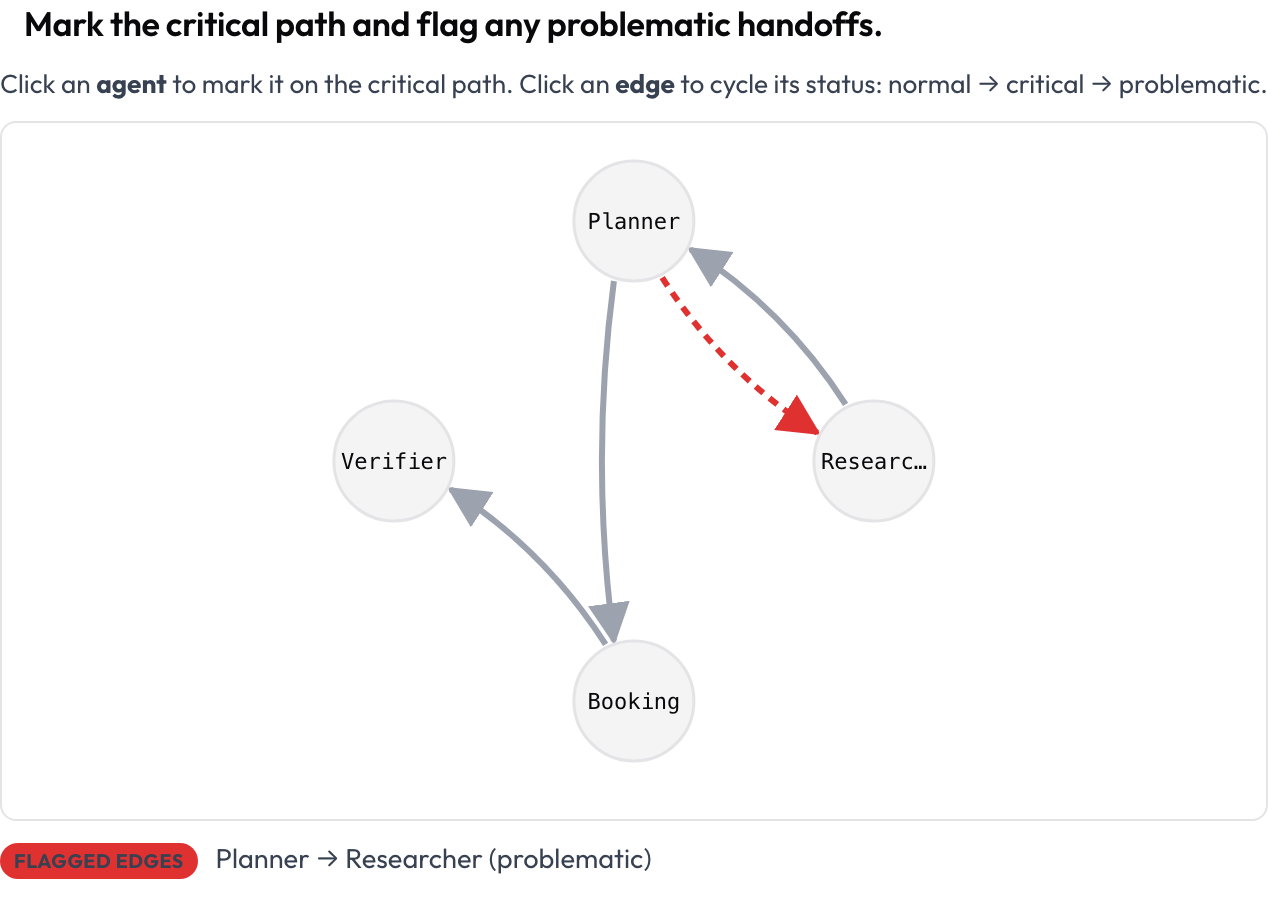 Marquez le chemin critique et signalez les passages de relais problématiques
Marquez le chemin critique et signalez les passages de relais problématiques
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentLe graphe est disposé automatiquement à partir de la trace, vous n'avez donc rien à dessiner. Chaque nœud et chaque arête est navigable au clavier, et un résumé textuel liste les nœuds critiques et les arêtes signalées, de sorte que le sens ne repose jamais sur la seule couleur. Cette vue est le moyen le plus rapide de répondre à « qui a parlé à qui, et où le chemin a-t-il déraillé ».
Comment attribuer un échec multi-agents à un seul agent ?
Une fois l'exécution visible, cernez l'échec. Le schéma failure_attribution demande le triplet issu de la littérature sur l'attribution des échecs (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, le jeu de données Who&When) : l'agent responsable, l'étape décisive et la raison. La liste déroulante d'agents et le sélecteur d'étapes sont peuplés à partir des tours de la trace elle-même, de sorte que vous ne pouvez attribuer l'échec qu'à un agent et à une étape qui ont réellement eu lieu.
 Attribuez l'échec à l'agent responsable, à l'étape décisive et expliquez pourquoi
Attribuez l'échec à l'agent responsable, à l'étape décisive et expliquez pourquoi
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agentCoupler l'attribution à un bouton radio succès/échec signifie que le triplet n'est collecté que sur les exécutions qui ont échoué, ce qui concentre le temps de l'annotateur sur les cas porteurs de signal.
Et les passages de relais eux-mêmes ?
L'attribution désigne une seule étape décisive. La revue des passages de relais examine chaque transfert de contrôle. Partout où l'agent actif change entre deux tours consécutifs, Potato émet une carte de passage de relais A → B, et vous signalez ce qui s'est mal passé lors du transfert — perte d'information, contrainte abandonnée, déformation, dérive d'objectif — et vous notez la qualité. Les modes d'échec proviennent de la catégorie inter-agents de MAST et du phénomène d'« écho » (Zhang et al., 2025).
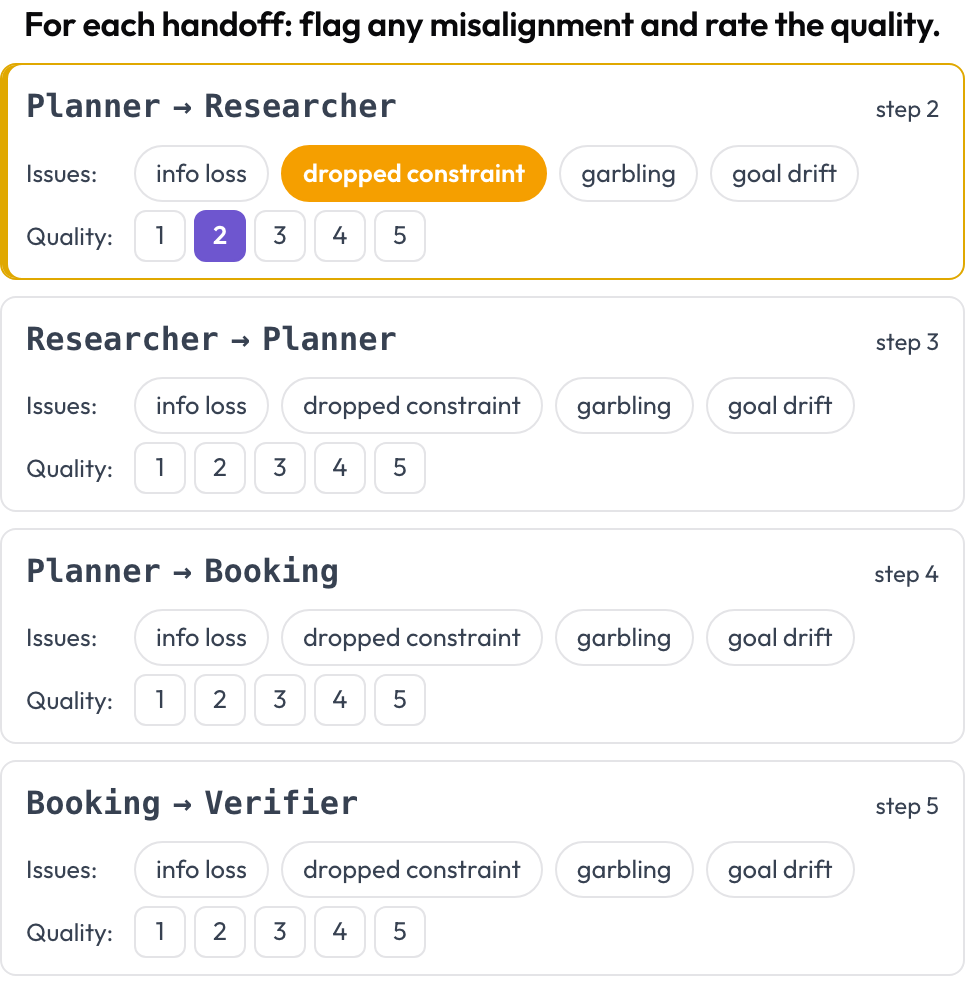 Signalez le désalignement inter-agents sur chaque passage de relais et notez sa qualité
Signalez le désalignement inter-agents sur chaque passage de relais et notez sa qualité
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Les passages de relais sont dérivés au moment du rendu, il n'y a donc aucune configuration manuelle. C'est généralement là que se résolvent les cas « chaque agent avait l'air correct, l'équipe a quand même échoué » : la contrainte était vivante chez l'agent A et avait disparu chez l'agent B.
Comment noter les agents et l'équipe ?
Un échec vous dit ce qui s'est cassé une fois. Un tableau de bord vous dit si une conception est bonne sur de nombreuses exécutions. Le schéma agent_scorecard note deux niveaux à la fois (MultiAgentBench, Zhou et al., ACL 2025) : chaque agent sur la fidélité au rôle, la contribution et la coordination, et l'équipe sur ses propres dimensions partagées, avec des jalons optionnels. Les lignes d'agents proviennent de la trace, de sorte que la matrice correspond à qui a réellement participé.
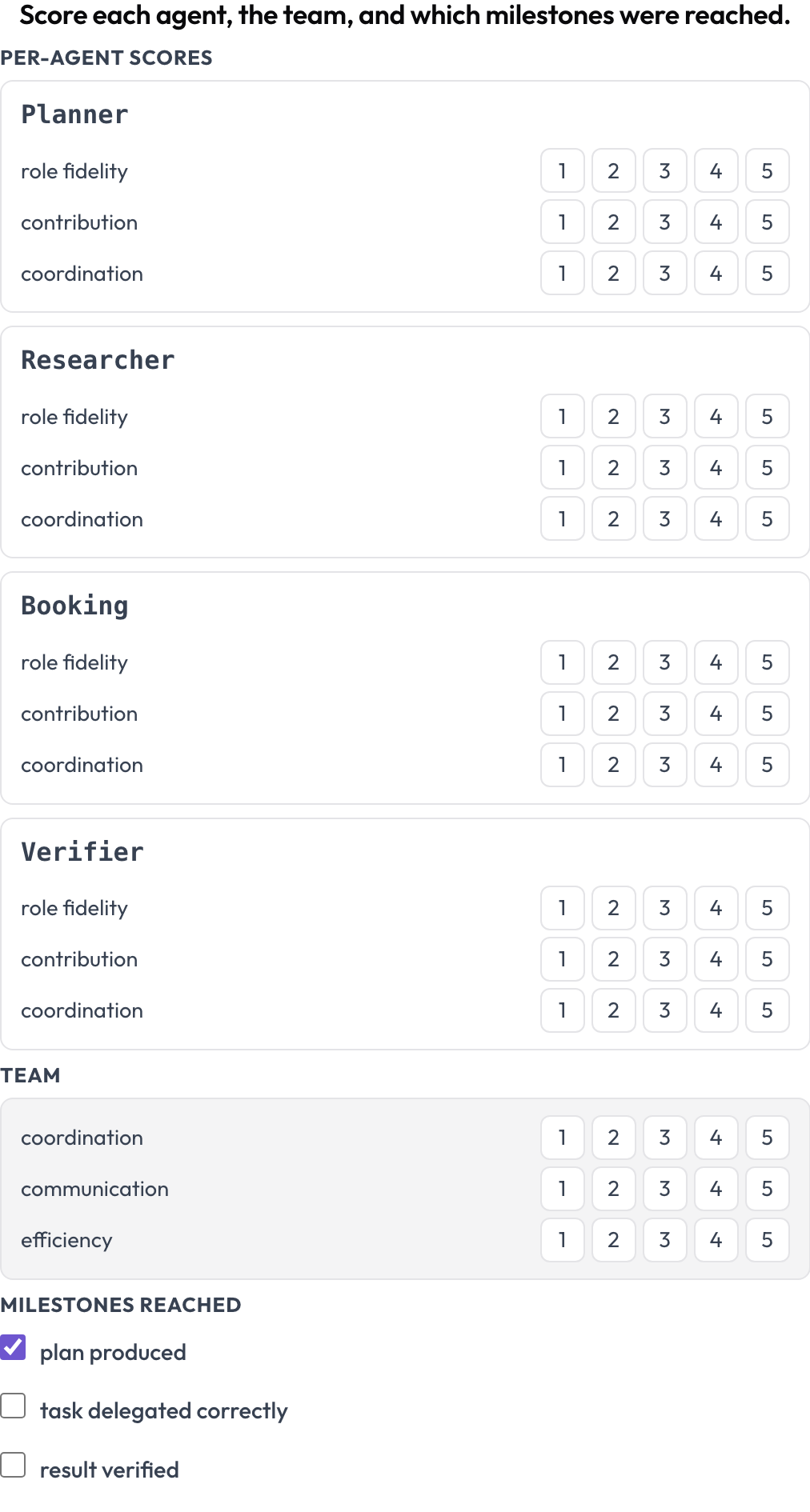 Notez chaque agent sur la fidélité au rôle, la contribution et la coordination, ainsi que l'équipe
Notez chaque agent sur la fidélité au rôle, la contribution et la coordination, ainsi que l'équipe
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]Un agent solide coincé dans une équipe mal coordonnée apparaît ici comme une ligne d'agent élevée à côté de dimensions d'équipe basses, soit exactement le motif que vous voulez quand vous comparez l'orchestration séquentielle à l'orchestration hiérarchique et au chat de groupe sur les mêmes tâches.
Et la concurrence et les échecs collectifs ?
Deux surfaces supplémentaires attrapent des échecs qu'une lecture tour par tour ne peut pas voir. La chronologie tool_contention place chaque agent sur sa propre piste et met en évidence les régions où deux appels touchent la même ressource à des moments qui se chevauchent, que vous classez comme interblocage, attente circulaire, condition de course ou bénin (DPBench, 2026).
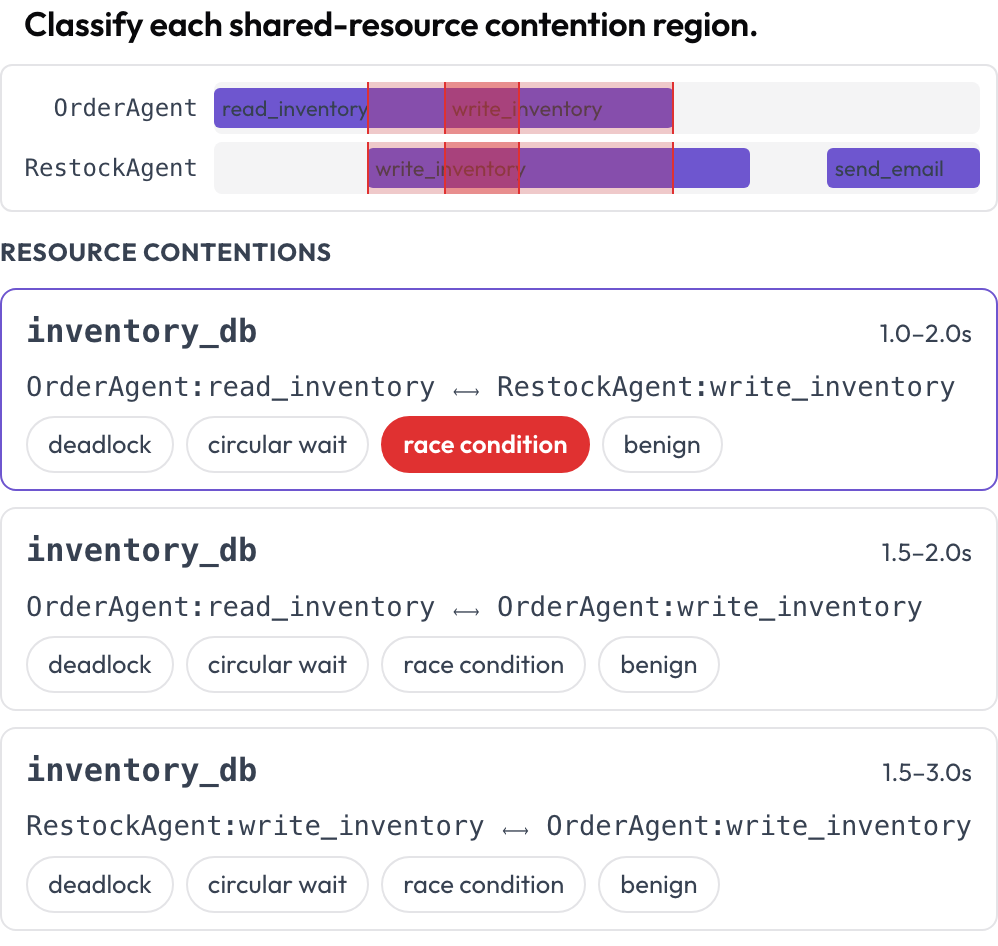 Repérez les interblocages et les conditions de course sur une chronologie d'appels d'outils par agent
Repérez les interblocages et les conditions de course sur une chronologie d'appels d'outils par agent
Et emergent_behavior gère les échecs qui sont collectifs plutôt que localisés à une étape — collusion, pensée de groupe, erreurs en cascade, dérive de rôle. Un comportement émergent n'est pas une plage contiguë ; c'est un ensemble de tours participants, éventuellement issus de différents agents, vous cochez donc les tours qui y prennent part et ajoutez une note.
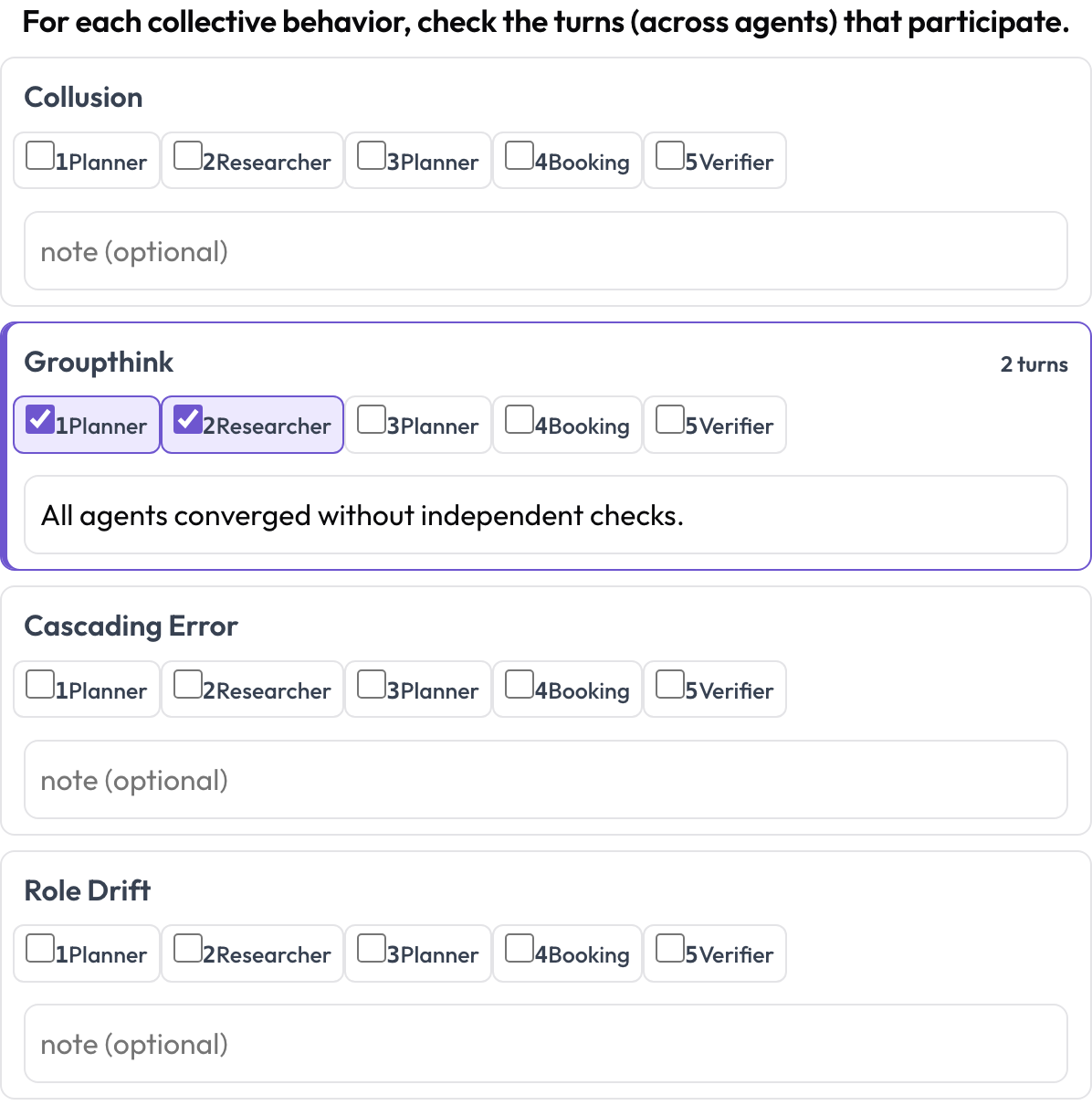 Étiquetez la collusion, la pensée de groupe et les erreurs en cascade à travers les agents et les tours
Étiquetez la collusion, la pensée de groupe et les erreurs en cascade à travers les agents et les tours
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueMettre tout cela dans l'ordre
Sur une vraie exécution défaillante, la séquence est généralement la suivante : lire le graphe d'interaction pour voir la forme, utiliser l'attribution de l'échec pour nommer l'étape décisive, ouvrir la revue des passages de relais si l'étape décisive était un transfert, et recourir à la chronologie de contention ou à l'étiquetage des comportements émergents quand l'échec relève du timing ou du groupe plutôt que d'un seul agent. Notez avec le tableau de bord une fois que vous comparez des conceptions plutôt que de déboguer une seule exécution. Mesurez l'accord sur l'attribution comme vous le feriez pour toute étiquette subjective ; voir Accord inter-annotateurs.
Pour aller plus loin
- Évaluation d'équipes multi-agents — la référence complète des schémas avec le YAML de chaque surface
- Comment évaluer les systèmes multi-agents — le guide de décision pour savoir quelle méthode utiliser quand
- Potato 2.6.2 : une suite complète et open source d'évaluation d'agents — tout ce qui est arrivé au fil de la série 2.6.x
- Annoter les trajectoires d'agents — taxonomies d'erreurs par étape, dont l'étiquetage MAST à la granularité de l'étape