Évaluer les agents vocaux et vidéo
Un parcours guidé de l'évaluation humaine des agents parlés, vidéo et documentaires dans Potato : noter le tour de parole sur une chronologie à deux pistes, ancrer les événements vidéo avec une IoU en direct, étiqueter les erreurs de parole et marquer la structure des tableaux.
Les agents qui parlent, regardent des vidéos et lisent des documents échouent de manières qu'une zone de texte ne peut pas montrer. Les erreurs d'un agent vocal vivent aux jointures entre les tours ; la réponse d'un agent vidéo est un intervalle de temps, pas une phrase ; l'erreur d'un agent documentaire est une cellule de tableau mal lue. Chacun a besoin d'une surface de revue façonnée pour sa modalité. Potato ajoute quatre de ces surfaces — voix, vidéo, parole et document — aux côtés de ses affichages image et audio existants. La référence complète est Évaluation d'agents multimodaux.
 Un simple widget texte ne peut exprimer ni une interruption, ni un intervalle d'événement, ni une cellule de tableau
Un simple widget texte ne peut exprimer ni une interruption, ni un intervalle d'événement, ni une cellule de tableau
Comment évaluer le tour de parole d'un agent vocal ?
Les agents parlés se cassent aux frontières : couper la parole à l'utilisateur, parler par-dessus lui, ou marquer une pause si longue que l'utilisateur abandonne. Le schéma voice_interaction dispose la conversation sous forme de chronologie à deux pistes — une piste utilisateur et une piste agent — et met en évidence les régions de chevauchement où les deux parlent en même temps (Full-Duplex-Bench, 2025). Vous classez chaque chevauchement et notez le tour de parole global ; l'audio se joue en ligne lorsqu'il est fourni.
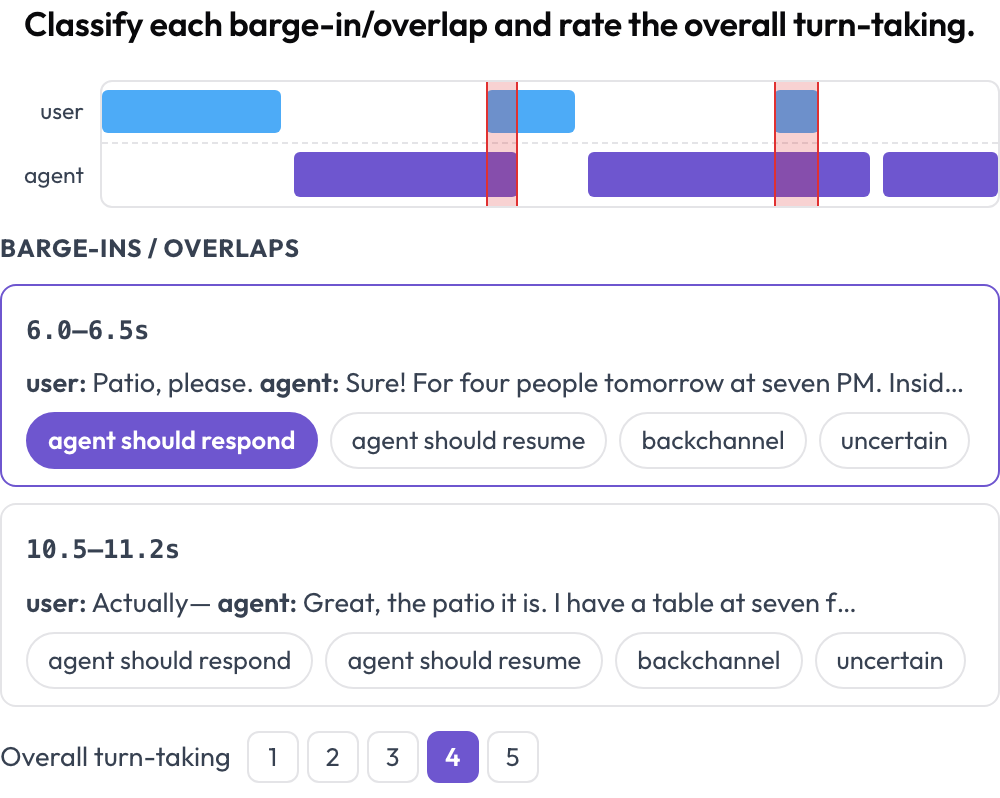 Chronologie vocale à deux pistes avec détection des interruptions et notation du tour de parole
Chronologie vocale à deux pistes avec détection des interruptions et notation du tour de parole
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5Les chevauchements sont calculés à partir des minutages des tours au moment du rendu, de sorte qu'une conversation en duplex intégral qu'une transcription à plat réduirait à « ils ont tous les deux dit des choses » devient un ensemble de moments concrets et étiquetables.
Comment noter l'ancrage temporel d'un agent vidéo ?
La réponse d'un agent vidéo à « quand l'objectif se produit-il ? » est un intervalle, vous le notez donc comme tel. Le schéma temporal_grounding vous donne un curseur de lecture où vous marquez le [start, end] de référence pour chaque invite d'événement, en capturant la tête de lecture ou en tapant des secondes. Quand les données portent l'intervalle prédit par le modèle, une IoU en direct et une mini-chronologie à deux barres se mettent à jour à mesure que vous ajustez (TimeScope, 2025).
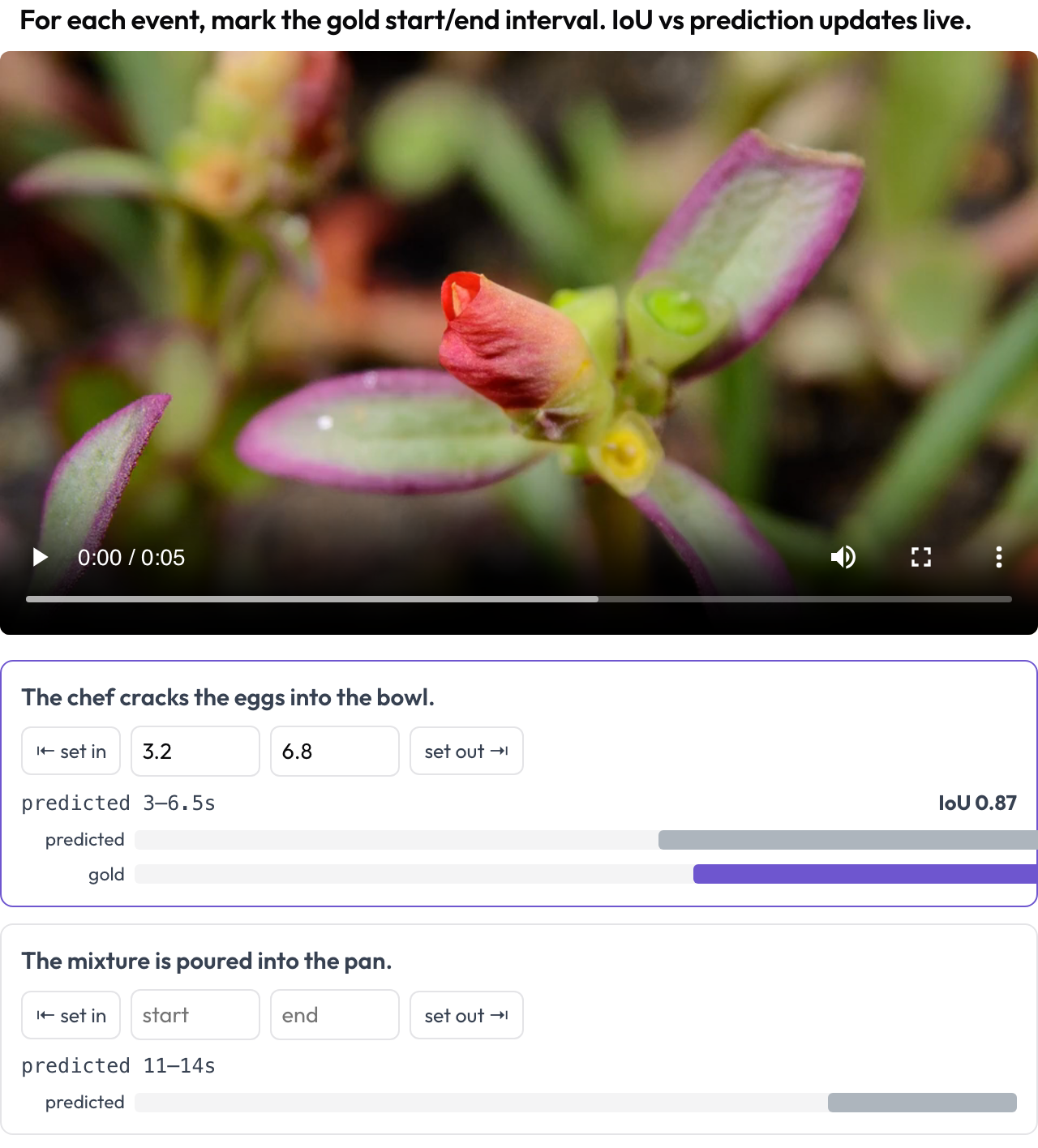 Marquez les intervalles d'événements de référence sur la vidéo avec une IoU en direct par rapport à la prédiction du modèle
Marquez les intervalles d'événements de référence sur la vidéo avec une IoU en direct par rapport à la prédiction du modèle
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsC'est conçu pour la localisation prédiction-contre-référence, ce qui est un travail différent de l'étiquetage de segments général : vous notez à quel point la plage du modèle est proche de la vérité, et voir l'IoU bouger pendant que vous faites glisser la frontière rend cela immédiat.
Et les transcriptions de parole, le raisonnement et les tableaux ?
Trois autres surfaces couvrent le reste de l'éventail multimodal :
- Transcriptions de parole (
speech_transcript) : chaque segment aligné temporellement est une carte ; vous étiquetez les erreurs ASR/TTS, les fautes de prononciation et les disfluences, et vous corrigez le texte en ligne (Speak & Improve, 2025). C'est le complément au niveau du segment de la vue du tour de parole. - Raisonnement entrelacé (
multimodal_reasoning) : une trace texte-image-outil rendue sous forme de blocs typés ; vous notez la cohérence de chaque étape et signalez les hallucinations visuelles là où le raisonnement ne découle pas de l'image (Multimodal RewardBench 2, 2025). - Tableaux de documents (
table_grid) : vous définissez les dimensions de la grille et cliquez sur les cellules pour marquer leur rôle — donnée, en-tête de colonne, en-tête de ligne, vide — capturant la structure que des boîtes englobantes ne peuvent pas saisir.
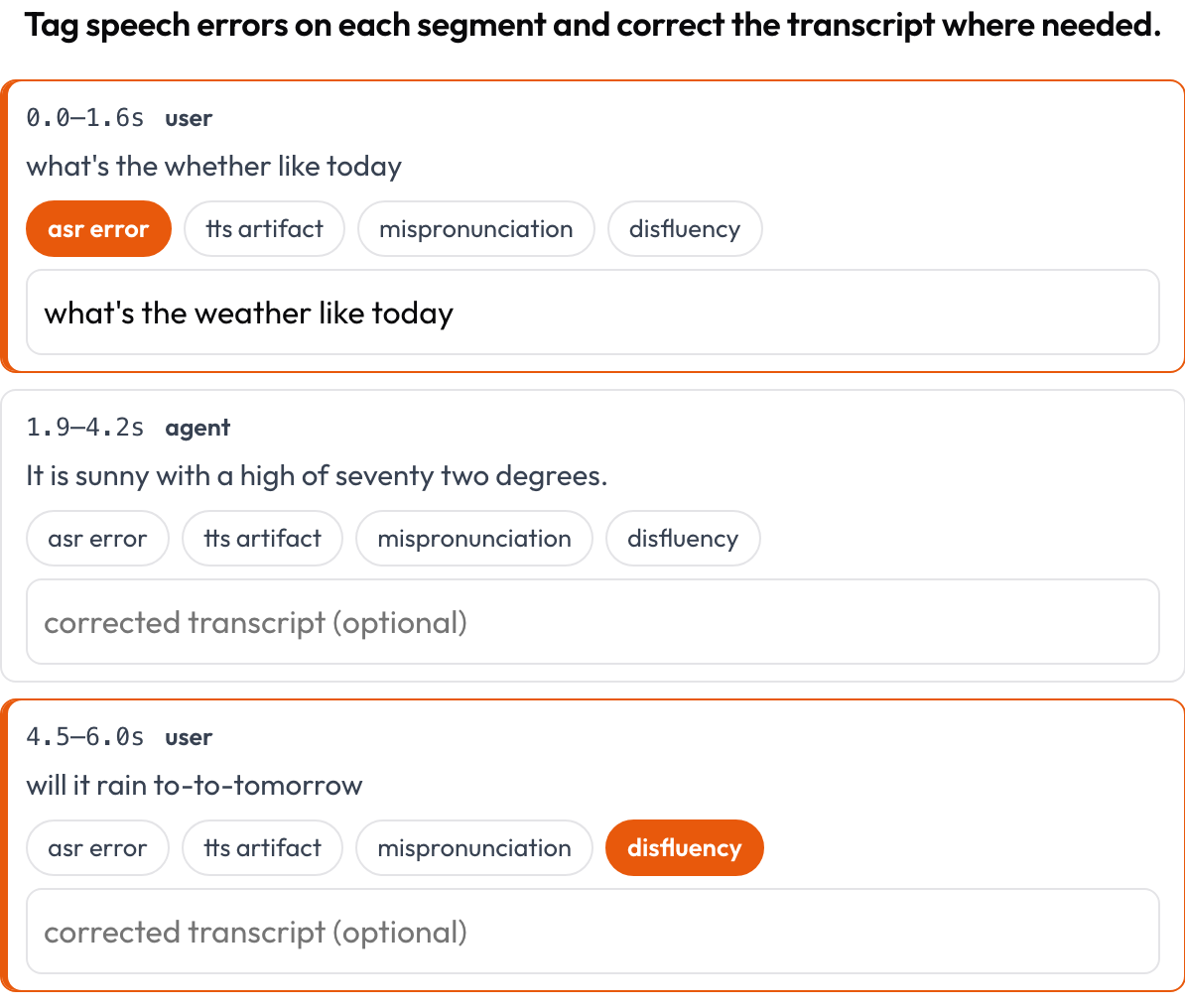 Étiquetez les erreurs ASR/TTS/prononciation par segment et corrigez la transcription en ligne
Étiquetez les erreurs ASR/TTS/prononciation par segment et corrigez la transcription en ligne
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true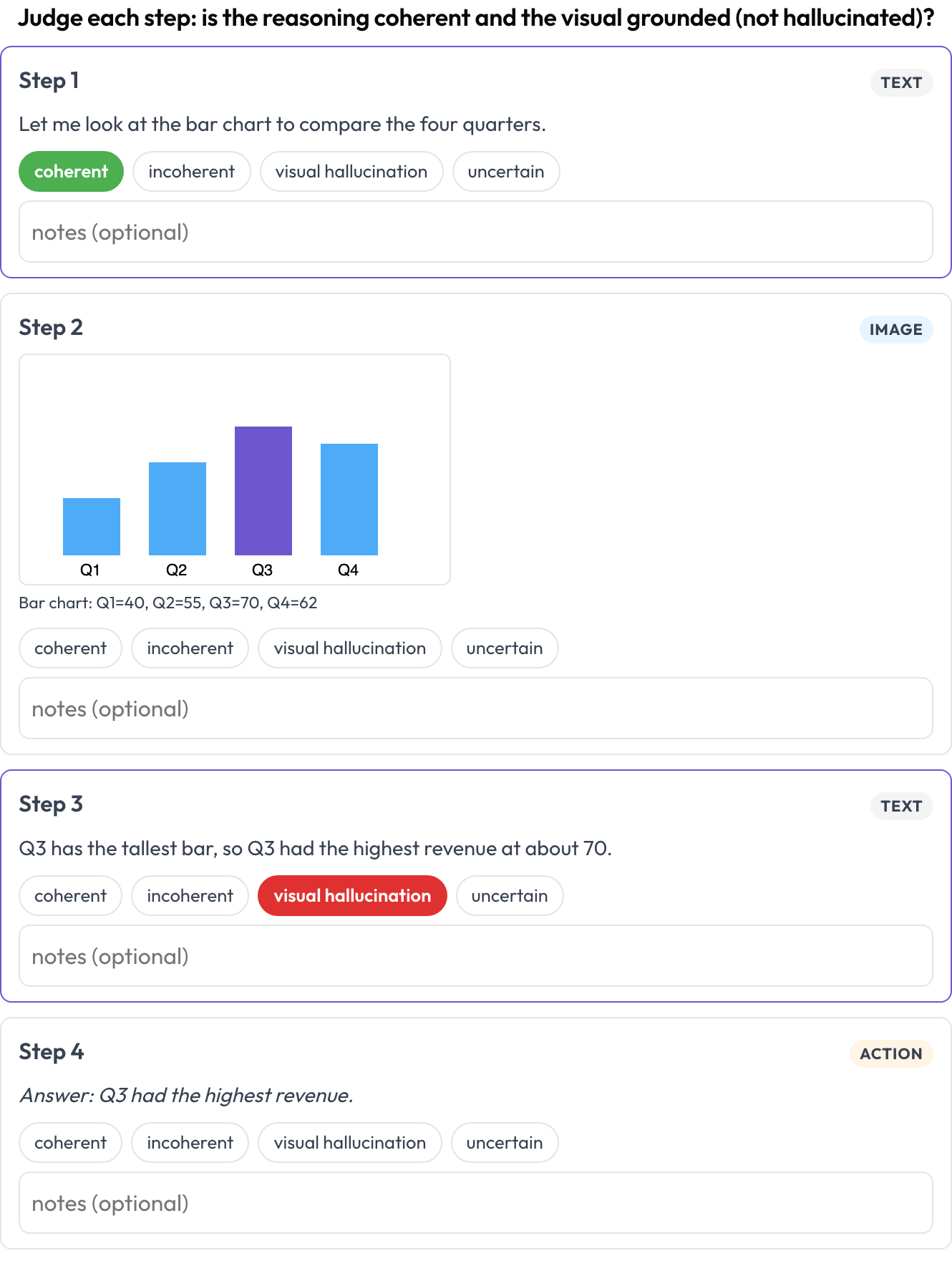 Notez chaque étape d'une trace de raisonnement texte-image-outil pour la cohérence et l'hallucination visuelle
Notez chaque étape d'une trace de raisonnement texte-image-outil pour la cohérence et l'hallucination visuelle
Plusieurs de ces schémas peuvent tourner sur la même tâche, de sorte qu'une unique exécution d'agent documentaire peut être notée à la fois pour la structure des tableaux et la cohérence du raisonnement.
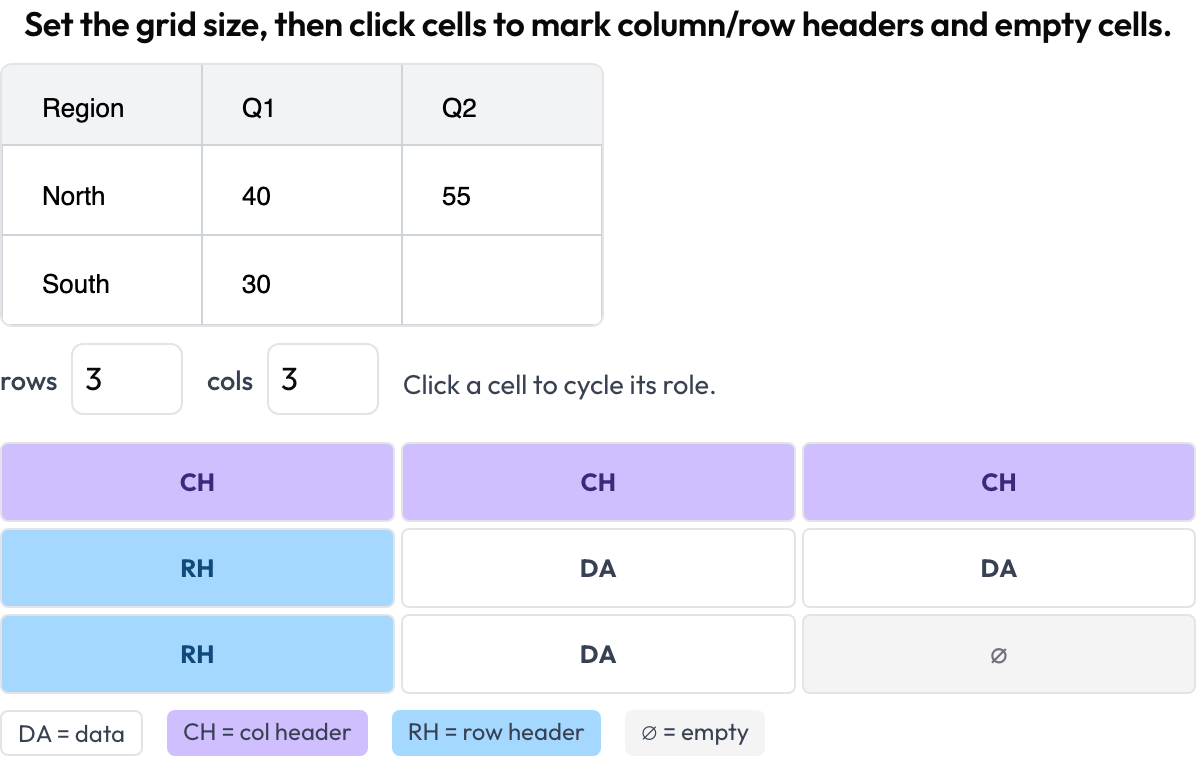 Annotez la structure des cellules d'un tableau de document : en-têtes de colonne et de ligne, données et cellules vides
Annotez la structure des cellules d'un tableau de document : en-têtes de colonne et de ligne, données et cellules vides
Comment mettre cela en place ?
Chaque surface est livrée avec un exemple exécutable sous examples/agent-traces/ :
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000Vos données s'insèrent sous forme de tours, de segments ou d'événements horodatés ; la surface dérive sa chronologie de ces données au moment du rendu. Pour les agents GUI et OS, la pièce complémentaire est Évaluer les agents computer-use.
Pour aller plus loin
- Évaluation d'agents multimodaux — la référence complète des schémas
- Évaluer les agents computer-use et multimodaux — le guide, avec un tableau de sélection des schémas
- Évaluer les agents computer-use, étape par étape — la moitié GUI et OS des surfaces multimodales
- Potato 2.6.2 : une suite complète et open source d'évaluation d'agents — tout ce qui est dans la série 2.6.x