Potato vs LangSmith and Langfuse for Agent Evaluation: A Practical Comparison
Compare Potato with LangSmith, Langfuse, Labelbox, and Scale AI for agent evaluation: trace rendering, per-step and multi-agent annotation, multimodal-agent review, coding agents, live observation, pricing, and self-hosting.
Three Tools, Three Philosophies
Potato, LangSmith, and Langfuse all touch agent evaluation, but they come at it from different starting points:
- Potato is annotation-first. It was built for collecting structured human judgments on AI outputs, then extended to support agent traces, coding diffs, and live observation. Its strength is the depth and configurability of its annotation schemas.
- LangSmith is observability-first. It was built to instrument, trace, and debug LangChain applications in production. Its annotation features came later, to support evaluation workflows inside the LangChain ecosystem.
- Langfuse is open-source observability. It covers tracing, prompt management, and evaluation for any LLM application. Its annotation features work but are secondary to its monitoring.
None of these is universally better. The right choice depends on whether you mainly need annotation, observability, or both, and whether you are committed to a particular framework ecosystem.
Feature Comparison
The table below compares capabilities relevant to AI agent evaluation. We include Label Studio, Argilla, and Scale AI as well, since teams often weigh those too.
| Feature | Potato | LangSmith | Langfuse | Label Studio | Argilla | Scale AI |
|---|---|---|---|---|---|---|
| Primary purpose | Annotation | Observability | Observability | Annotation | Annotation | Annotation |
| Trace format support | 13 formats | LangChain native | Langfuse SDK | None | None | Custom |
| Per-step annotation | Full (trajectory_eval) | Per-span score + comment | Span-level structured scores | Yes (trace import) | Chat turns only | Custom |
| Real-time agent observation | Yes | No | No | No | No | No |
| Agent pause/resume/takeover | Yes | No | No | No | No | No |
| Code diff rendering | Yes (unified diff, syntax highlighting) | No | No | No | No | No |
| Terminal output rendering | Yes (ANSI color support) | No | Partial | No | No | No |
| PRM data collection | Yes (step-level correctness labels) | No | No | No | No | No |
| Code review with inline comments | Yes (line-level, categorized) | No | No | No | No | No |
| Pairwise comparison | 3 modes (side-by-side, sequential, blind) | Limited (1 mode) | No | No | Yes (1 mode) | Yes (1 mode) |
| Multi-criteria rubric | Yes (configurable dimensions, scales) | No | No | No | Partial | Yes |
| Error taxonomy | Hierarchical, configurable | No | Categorical score config | No | No | Custom |
| Severity scoring | Yes (weighted, running score) | No | Numeric scores only | No | No | Custom |
| Multi-agent interaction graph (annotator-editable) | Yes | No | Visualization only ¹ | No | No | No |
| Cross-agent failure attribution | Yes | No | Workaround only | No | No | Managed only |
| Handoff review (first-class object) | Yes | No | No | No | No | No |
| Per-agent + per-team scorecard | Yes | No | No | No | No | No |
| Computer-use trajectory (click grounding) | Yes | No | No | Generic image tools | No | Managed dataset ² |
| Full-duplex voice (barge-in scoring) | Yes | No | Playback only | No | No | Turn-based only ³ |
| Video temporal grounding (live IoU) | Yes | No | No | IoU is inter-annotator only | No | No |
| Self-hosted | Yes (fully) | Enterprise tier only | Yes (open source) | Yes (open source) | Yes (open source) | VPC (enterprise) |
| Free | Yes (fully open source) | No (free tier limited) | Partial (open source core) | Partial (open source core) | Yes (open source) | No |
| Framework lock-in | None | LangChain ecosystem | None | None | None | None |
¹ Langfuse "Agent Graphs" (beta) renders a multi-agent run as a graph, but as a read-only debugging view — there is no documented way for an annotator to mark the critical path or flag edges on it. ² Scale AI annotates GUI/computer-use trajectories as a managed data engagement (e.g. its CUA-Suite work in CVAT), not as a self-serve feature you configure. ³ Scale's "Voice Showdown" is turn-based; full-duplex barge-in/overlap scoring is listed as planned, not yet available (as of 2026-03-20).
Comparison observed 2026-06-24 against LangSmith (docs.langchain.com), Langfuse (MIT core, continuous release), Label Studio 1.23.0, Argilla 2.8.0, and Scale AI product pages. These tools ship fast — if something here is out of date, corrections are welcome on the GitHub repository.
Among these tools, Potato is the only one that renders coding agent traces with proper diff formatting:
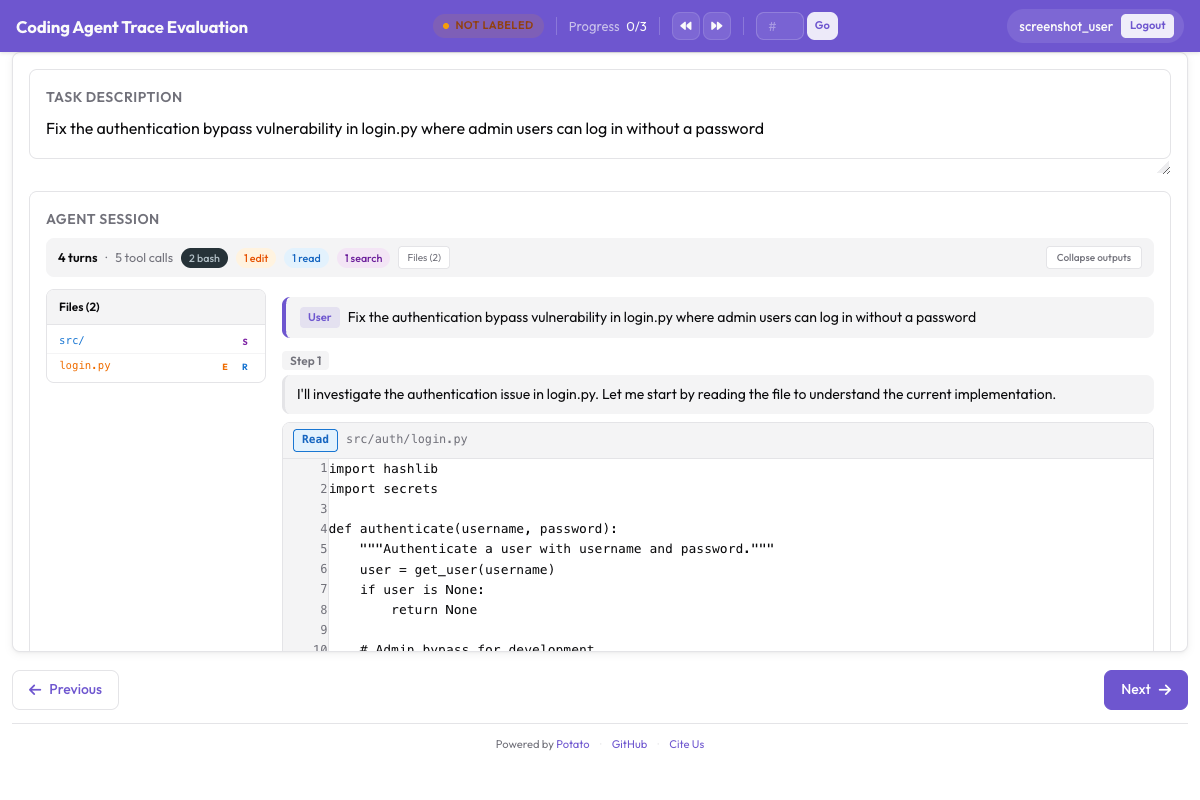 Potato's CodingTraceDisplay with unified diff rendering, syntax highlighting, and file tree
Potato's CodingTraceDisplay with unified diff rendering, syntax highlighting, and file tree
Trace Format Support in Detail
One of the biggest practical differences is how many agent trace formats each tool supports natively.
Potato includes converters for 13 formats:
# See all available converters
python -m potato.convert_traces --list-formats
# Available formats:
# react - ReAct-style (Thought/Action/Observation)
# openai - OpenAI function calling / tool use
# anthropic - Anthropic Messages API with tool_use
# langchain - LangChain run traces
# langfuse - Langfuse trace exports
# langsmith - LangSmith dataset exports
# autogen - Microsoft AutoGen conversations
# crewai - CrewAI task outputs
# swe_agent - SWE-Agent trajectories
# claude_code - Claude Code session logs
# aider - Aider chat histories
# webarena - WebArena episode traces
# custom - User-defined format with mapping configLangSmith works natively with LangChain traces. If your agent is built with LangChain or LangGraph, traces flow in automatically. If not, you need to manually instrument your code with the LangSmith SDK or convert your traces to LangSmith's format.
Langfuse works natively with traces instrumented via the Langfuse SDK. It supports Python, JavaScript, and has integrations with LangChain, LlamaIndex, and OpenAI. Like LangSmith, it requires instrumentation at the code level rather than post-hoc trace conversion.
Importing LangSmith or Langfuse Traces into Potato
If you already have traces in LangSmith or Langfuse and want to use Potato's annotation features, the converters handle this:
# Export from LangSmith and convert
python -m potato.convert_traces \
--input langsmith_export.jsonl \
--output data/traces.jsonl \
--format langsmith
# Export from Langfuse and convert
python -m potato.convert_traces \
--input langfuse_traces.json \
--output data/traces.jsonl \
--format langfuseSo you can keep LangSmith or Langfuse for production monitoring and bring traces into Potato when you want detailed human evaluation.
Per-Step Annotation: Where the Gap Is Widest
The most significant capability difference is in per-step annotation depth.
Potato provides the trajectory_eval schema with:
- Step-level correctness labels (correct/incorrect)
- Hierarchical error taxonomy selection
- Severity levels with configurable weights
- Running score that updates per step
- Free-text rationale per step
- All of this is configurable via YAML
# Potato: rich per-step annotation
annotation_schemes:
- annotation_type: "trajectory_eval"
name: "step_eval"
step_correctness:
labels: ["correct", "incorrect"]
error_taxonomy:
- category: "reasoning"
types:
- name: "logical_error"
- name: "incorrect_assumption"
- category: "action"
types:
- name: "wrong_tool"
- name: "wrong_arguments"
severity_levels:
- name: "minor"
weight: -1
- name: "major"
weight: -5
- name: "critical"
weight: -10
running_score:
initial: 100LangSmith allows you to attach a numeric score or a categorical label to individual runs within a trace. This is useful for basic quality tracking but does not support error taxonomies, severity weighting, or running scores. There is no built-in per-step review interface; you score runs from the trace detail view.
Langfuse supports scoring at the trace level and at the observation (span) level, and its categorical score configs let you define a fixed label set — a usable error taxonomy — and attach several named scores to the same span. What it does not provide as a first-class schema is a hierarchical taxonomy or a severity-weighted running score that accumulates across steps; you assemble those yourself from flat score configs.
So the honest version of the gap is narrower than it used to be: Langfuse and Label Studio (which now imports LangGraph/CrewAI/AutoGen traces for per-step review) both do structured per-step scoring. Where Potato is still purpose-built is the combination — a hierarchical error taxonomy plus severity weights plus a running score in one trajectory_eval schema — which is what you want for building PRM training data or pinpointing where an agent first goes wrong.
Coding Agent Support
Evaluating coding agents (Claude Code, Aider, SWE-Agent, Devin, OpenHands) means rendering code diffs and terminal output so review goes quickly. This is where Potato pulls ahead of the others.
Potato renders:
- Unified diffs with red/green highlighting and syntax highlighting
- Terminal output with ANSI color code support
- Inline diff comments anchored to specific lines
- File-level quality ratings
- PR-style approve/request-changes verdicts
LangSmith displays tool call inputs and outputs as formatted JSON. Code diffs appear as raw text strings within tool outputs. There is no diff rendering, syntax highlighting, or inline commenting.
Langfuse similarly displays trace data as structured JSON. Code content appears as plain text. No specialized rendering for diffs or terminal output.
For coding agents, this changes the reviewer's day. Reviewing a 50-line diff in a syntax-highlighted unified diff view with inline commenting takes a fraction of the time it takes to read the same diff as a JSON string.
Web agent traces include screenshots with SVG overlays and filmstrip navigation:
 Web agent trace viewer showing screenshots with SVG action overlays and filmstrip navigation
Web agent trace viewer showing screenshots with SVG action overlays and filmstrip navigation
Live Agent Observation
Potato can observe a running agent in real time, which neither LangSmith nor Langfuse do in their annotation workflows.
In Potato's live observation mode, an annotator can watch the agent work step by step, pause it to review its current state, resume it afterward, and take over the session to correct course or finish the task by hand.
This helps in a few situations: stopping an agent before it does something destructive (safety), recording human corrections as demonstration data (training), and seeing how an agent responds when you intervene mid-stream (interactive evaluation).
# Enable live observation in Potato config
live_observation:
enabled: true
agent_endpoint: "http://localhost:5000/agent"
allow_pause: true
allow_takeover: true
auto_pause_on:
- action_type: "delete"
- action_type: "execute"
- confidence_below: 0.3LangSmith and Langfuse are designed for post-hoc analysis of completed traces, not real-time interaction with running agents.
Pairwise Comparison
Comparing two agent outputs side by side is a common evaluation pattern, especially for A/B testing model versions or comparing agent architectures.
Potato offers three comparison modes:
- Side-by-side: Both traces visible simultaneously, synced scrolling
- Sequential: View trace A first, then trace B, then judge
- Blind: Traces are randomly labeled "A" and "B" with no model attribution
annotation_schemes:
- annotation_type: "pairwise"
name: "comparison"
mode: "side_by_side" # or "sequential" or "blind"
labels:
- name: "A is better"
- name: "B is better"
- name: "Tie"
criteria:
- "Which agent completed the task more efficiently?"
- "Which agent's output is higher quality?"LangSmith supports basic pairwise comparison through its "comparison view" in evaluation experiments. You can compare runs across different model versions, but the interface is designed for side-by-side run inspection rather than structured preference annotation.
Langfuse does not have a built-in pairwise comparison feature for annotation.
When to Use Each Tool
Use Potato when:
- Annotation is your primary goal: You need structured human judgments, not just monitoring
- You need coding agent support: Diff rendering, inline comments, terminal output display
- You are collecting PRM training data: Step-level correctness labels with running scores
- You need self-hosting: Data stays on your infrastructure, no cloud dependency
- You work with multiple agent frameworks: 13 trace format converters vs. single-framework lock-in
- You need rich evaluation schemas: Trajectory eval, rubric eval, code review, pairwise comparison
- Budget is a constraint: Fully free and open source
Use LangSmith when:
- You are already using LangChain/LangGraph: Traces flow in automatically with zero configuration
- Production monitoring is your primary need: Real-time tracing, latency tracking, cost monitoring
- Annotation is secondary: You need basic scoring and feedback, not deep evaluation schemas
- You want a managed service: No infrastructure to maintain
- Your team is small: The free tier may be sufficient for light evaluation
Use Langfuse when:
- You need open-source observability: Self-hosted monitoring and tracing
- You use multiple LLM providers: Good integrations across OpenAI, Anthropic, LangChain, LlamaIndex
- Annotation is not your primary use case: Scoring is available but not the focus
- You want prompt management alongside tracing: Langfuse bundles prompt versioning with observability
- You need a free alternative to LangSmith for monitoring: Langfuse's open-source core covers most monitoring needs
The Complementary Approach: Observability + Annotation
For many teams, the practical setup is to run an observability tool (LangSmith or Langfuse) for production monitoring and Potato for detailed human evaluation. The workflow looks like this:
- Instrument your agent with LangSmith or Langfuse for production tracing
- Sample traces that need human review (failures, edge cases, random samples)
- Export those traces from your observability tool
- Convert and import into Potato using the built-in converters
- Run human evaluation with Potato's rich annotation schemas
- Feed results back into your development cycle
# Example: sample 100 failed traces from Langfuse and import to Potato
python -m potato.convert_traces \
--input langfuse_failed_traces.json \
--output data/traces_to_review.jsonl \
--format langfuse \
--sample 100That gives you the real-time visibility of an observability platform alongside the annotation depth of a tool built for annotation.
Key Differentiators Summary
Two of these surfaces are where the claim is strongest. Of every tool we surveyed (commercial and open source), Potato is the only one offering annotator-configurable surfaces for multi-agent team structure and multimodal-agent review:
- A clickable, annotator-editable multi-agent interaction graph — mark the critical path, flag the bad handoff. The nearest thing elsewhere, Langfuse's "Agent Graphs," is a read-only debugging view.
- Cross-agent failure attribution, handoff review as a first-class object, per-agent and per-team scorecards, a tool-contention timeline, and emergent-behavior tagging — none of which the other tools offer as built-in annotation constructs.
- Computer-use trajectories with click grounding, full-duplex voice timelines with barge-in scoring, and video temporal grounding with live IoU. Scale AI does GUI grounding and voice eval, but as managed dataset engagements, and its voice arena is still turn-based.
On top of those, Potato remains the only free, self-hosted tool that combines coding-agent diff rendering with inline comments, PRM data collection, live observation with pause/resume/takeover, any-framework trace ingestion, a hierarchical error taxonomy with a severity-weighted running score, three pairwise comparison modes, and PR-style code review.
We're not aware of another tool, open source or commercial, that bundles all of this — verified against LangSmith, Langfuse, Labelbox, Scale AI, Label Studio, Argilla, and Braintrust as of 2026-06-24 (see the dated footnote under the comparison table). LangSmith and Langfuse are strong observability tools whose annotation features are span-scoped scores, not agent-structure surfaces. Label Studio and Argilla are general annotation tools; Label Studio has bolted on trace import, but neither offers the multi-agent or multimodal-agent surfaces above. Labelbox and Scale offer agent-evaluation data products, but as paid, cloud or managed services rather than a self-hosted tool a research team can run and customize.
If your goal is to understand how and why your agents succeed or fail, and to collect the training data to improve them, Potato covers a gap the others leave open.
Migration Paths
From LangSmith to Potato (for annotation)
# 1. Export your dataset from LangSmith
langsmith export dataset my_eval_dataset -o langsmith_data.jsonl
# 2. Convert to Potato format
python -m potato.convert_traces \
--input langsmith_data.jsonl \
--output data/traces.jsonl \
--format langsmith
# 3. Create your Potato config and start annotating
potato start config.yaml -p 8000From Langfuse to Potato (for annotation)
# 1. Export traces from Langfuse via API
import requests
response = requests.get(
"https://cloud.langfuse.com/api/public/traces",
headers={"Authorization": "Bearer your_api_key"},
params={"limit": 500}
)
with open("langfuse_traces.json", "w") as f:
json.dump(response.json()["data"], f)# 2. Convert to Potato format
python -m potato.convert_traces \
--input langfuse_traces.json \
--output data/traces.jsonl \
--format langfuse
# 3. Start annotating
potato start config.yaml -p 8000From Label Studio or Argilla (for agent evaluation)
If you are currently using Label Studio or Argilla for general annotation and want to add agent evaluation capabilities, Potato can run alongside your existing tool. Use Label Studio or Argilla for your non-agent annotation tasks (NER, classification, etc.) and Potato for agent-specific evaluation that requires trace rendering, per-step annotation, and code review.
Conclusion
Choosing between Potato, LangSmith, and Langfuse is not about which is best in the abstract. It depends on what you mainly need:
- To monitor agents in production, use LangSmith or Langfuse.
- To evaluate agent behavior with structured human annotation, use Potato.
- If you need both, run them together. They complement each other.
The question to ask is whether your main goal is to observe what agents do or to evaluate how well they do it. If it's evaluation, Potato is built for that.
For a fuller side-by-side, see the comparison documentation and the agent evaluation guide.