Evaluating AI Agents: A Complete Guide to Human Annotation of Agent Traces
Learn how to set up human evaluation of AI agent outputs using Potato's agentic annotation features, from trace import to annotation schema design.
Automated metrics tell you how often an agent succeeds. They don't tell you why it failed, which is usually the thing you actually need to know. Human evaluation does: it shows you the step where the reasoning went sideways, not just the bottom-line score. This guide sets up a full human evaluation pipeline for AI agents using Potato's agentic annotation features.
 From raw traces to structured judgments
From raw traces to structured judgments
We will evaluate a ReAct-style agent that answers questions by searching the web. By the end you will have:
- Imported agent traces into Potato
- Configured the agent trace display
- Set up both overall and per-step annotation schemas
- Run the annotation task
- Exported structured evaluation results
Potato's agent trace display renders each step with color-coded cards for thoughts, actions, and observations:
Prerequisites
Install Potato 2.3.0 or later:
pip install --upgrade potato-annotationYou will also need agent traces to evaluate. This guide uses ReAct traces, but the same approach works for any of the 12 supported formats.
Step 1: Prepare Your Agent Traces
A ReAct trace is a sequence of Thought, Action, and Observation steps. Here is a minimal example. Create a file at data/traces.jsonl:
{
"trace_id": "trace_001",
"task": "What is the capital of Australia and what is its population?",
"trace": [
{"type": "thought", "content": "I need to find the capital of Australia and its population. Let me search for this."},
{"type": "action", "content": "search", "action_input": "capital of Australia"},
{"type": "observation", "content": "Canberra is the capital city of Australia. It was chosen as the capital in 1908 as a compromise between Sydney and Melbourne."},
{"type": "thought", "content": "The capital is Canberra. Now I need to find its population."},
{"type": "action", "content": "search", "action_input": "Canberra population 2025"},
{"type": "observation", "content": "Canberra has a population of approximately 467,000 as of 2025, making it the eighth-largest city in Australia."},
{"type": "thought", "content": "I now have both pieces of information. The capital of Australia is Canberra with a population of approximately 467,000."},
{"type": "action", "content": "finish", "action_input": "The capital of Australia is Canberra, with a population of approximately 467,000 as of 2025."}
],
"ground_truth": "Canberra, approximately 467,000"
}Each line in the JSONL file is one complete agent trace. The trace field contains the step-by-step log. The task field is what the agent was asked to do.
Trace Format Notes
For OpenAI function-calling traces, the format looks different:
{
"trace_id": "oai_001",
"task": "Find cheap flights from NYC to London",
"messages": [
{"role": "user", "content": "Find cheap flights from NYC to London"},
{"role": "assistant", "content": null, "tool_calls": [{"function": {"name": "search_flights", "arguments": "{\"from\": \"NYC\", \"to\": \"LHR\"}"}}]},
{"role": "tool", "name": "search_flights", "content": "{\"flights\": [{\"airline\": \"BA\", \"price\": 450}, {\"airline\": \"AA\", \"price\": 520}]}"},
{"role": "assistant", "content": "I found flights from NYC to London. The cheapest is British Airways at $450."}
]
}Potato's converter handles these differences. You just specify the right converter name.
Step 2: Create the Project Configuration
Create config.yaml:
annotation_task_name: "ReAct Agent Evaluation"
task_dir: "."
data_files:
- "data/traces.jsonl"
item_properties:
id_key: trace_id
text_key: task
# --- Agentic annotation settings ---
agentic:
enabled: true
trace_converter: react
display_type: agent_trace
agent_trace_display:
colors:
thought: "#6E56CF"
action: "#3b82f6"
observation: "#22c55e"
error: "#ef4444"
collapse_observations: true
collapse_threshold: 400
show_step_numbers: true
show_timestamps: false
render_json: true
syntax_highlight: trueThis tells Potato to:
- Load traces from
data/traces.jsonl - Use the ReAct converter to parse the
tracefield - Display traces using the agent trace display with color-coded step cards
Step 3: Design Your Annotation Schemas
Agent evaluation typically needs both trace-level judgments (did the agent succeed?) and step-level judgments (was each step correct?). Let us add both.
Add the following to config.yaml:
annotation_schemes:
# --- Trace-level schemas ---
# 1. Task success (the most important metric)
- annotation_type: radio
name: task_success
description: "Did the agent successfully complete the task?"
labels:
- "Success"
- "Partial Success"
- "Failure"
label_requirement:
required: true
sequential_key_binding: true
# 2. Answer correctness (if the task has a ground truth)
- annotation_type: radio
name: answer_correctness
description: "Is the agent's final answer factually correct?"
labels:
- "Correct"
- "Partially Correct"
- "Incorrect"
- "Cannot Determine"
label_requirement:
required: true
# 3. Efficiency rating
- annotation_type: likert
name: efficiency
description: "Did the agent use an efficient path to the answer?"
min: 1
max: 5
labels:
1: "Very Inefficient (many unnecessary steps)"
3: "Average"
5: "Optimal (no wasted steps)"
# 4. Free-text notes
- annotation_type: text
name: evaluator_notes
description: "Any additional observations"
label_requirement:
required: false
# --- Step-level schemas ---
# 5. Per-step correctness
- annotation_type: per_turn_rating
name: step_correctness
target: agentic_steps
description: "Was this step correct and useful?"
rating_type: radio
labels:
- "Correct"
- "Partially Correct"
- "Incorrect"
- "Unnecessary"
# 6. Per-step error type (only shown when step is not correct)
- annotation_type: per_turn_rating
name: error_type
target: agentic_steps
description: "What type of error occurred?"
rating_type: multiselect
labels:
- "Wrong tool/action"
- "Wrong arguments"
- "Hallucinated information"
- "Reasoning error"
- "Redundant step"
- "Premature termination"
- "Other"
conditional:
show_when:
step_correctness: ["Partially Correct", "Incorrect", "Unnecessary"]That covers both ends of the analysis. The success/failure label and answer-correctness rating give you the high-level numbers. The efficiency score lets you compare strategies. And the per-step ratings, with an error taxonomy that only appears when a step is marked wrong, tell you exactly where things broke.
Step 4: Configure Output and Start the Server
Add output settings to config.yaml:
output_annotation_dir: "output/"
export_annotation_format: "jsonl"
# Optional: also export to Parquet for analysis
parquet_export:
enabled: true
output_dir: "output/parquet/"
compression: zstdComplete config.yaml for reference:
annotation_task_name: "ReAct Agent Evaluation"
task_dir: "."
data_files:
- "data/traces.jsonl"
item_properties:
id_key: trace_id
text_key: task
agentic:
enabled: true
trace_converter: react
display_type: agent_trace
agent_trace_display:
colors:
thought: "#6E56CF"
action: "#3b82f6"
observation: "#22c55e"
error: "#ef4444"
collapse_observations: true
collapse_threshold: 400
show_step_numbers: true
render_json: true
syntax_highlight: true
annotation_schemes:
- annotation_type: radio
name: task_success
description: "Did the agent successfully complete the task?"
labels: ["Success", "Partial Success", "Failure"]
label_requirement:
required: true
sequential_key_binding: true
- annotation_type: radio
name: answer_correctness
description: "Is the agent's final answer factually correct?"
labels: ["Correct", "Partially Correct", "Incorrect", "Cannot Determine"]
label_requirement:
required: true
- annotation_type: likert
name: efficiency
description: "Did the agent use an efficient path?"
min: 1
max: 5
labels:
1: "Very Inefficient"
3: "Average"
5: "Optimal"
- annotation_type: text
name: evaluator_notes
description: "Any additional observations"
label_requirement:
required: false
- annotation_type: per_turn_rating
name: step_correctness
target: agentic_steps
description: "Was this step correct?"
rating_type: radio
labels: ["Correct", "Partially Correct", "Incorrect", "Unnecessary"]
- annotation_type: per_turn_rating
name: error_type
target: agentic_steps
description: "Error type"
rating_type: multiselect
labels:
- "Wrong tool/action"
- "Wrong arguments"
- "Hallucinated information"
- "Reasoning error"
- "Redundant step"
- "Premature termination"
- "Other"
conditional:
show_when:
step_correctness: ["Partially Correct", "Incorrect", "Unnecessary"]
output_annotation_dir: "output/"
export_annotation_format: "jsonl"
parquet_export:
enabled: true
output_dir: "output/parquet/"
compression: zstdStart the server:
potato start config.yaml -p 8000Open http://localhost:8000 in your browser.
Step 5: The Annotation Workflow
When an annotator opens a trace, they see:
- Task description at the top (the original user query)
- Step cards showing the full agent trace, color-coded by type:
- Purple cards for thoughts/reasoning
- Blue cards for actions/tool calls
- Green cards for observations/results
- Red cards for errors
- Per-step rating controls next to each step card
- Trace-level schemas below the trace display
The typical workflow:
- Read the task description to understand what the agent was supposed to do
- Walk through the trace steps, rating each one
- For any step rated as "Partially Correct" or "Incorrect", select the error type(s)
- Rate the overall trace (success, correctness, efficiency)
- Add notes if needed
- Submit and move to the next trace
Tips for annotators
Expand the collapsed observations rather than trusting them at a glance; that is where you catch the agent misreading what it found. Check the final answer against the ground truth, if you have one, before you rate task success. Keep "Unnecessary" and "Incorrect" apart, since a wasted step costs effort but doesn't actually introduce an error. And on long traces, the step timeline sidebar lets you jump straight to the step you care about.
Step 6: Analyzing Results
After annotation, analyze the results programmatically.
Basic Analysis with pandas
import pandas as pd
import json
# Load annotations
annotations = []
with open("output/annotations.jsonl") as f:
for line in f:
annotations.append(json.loads(line))
df = pd.DataFrame(annotations)
# Task success rate
success_counts = df.groupby("annotations").apply(
lambda x: x.iloc[0]["annotations"]["task_success"]
).value_counts()
print("Task Success Distribution:")
print(success_counts)
# Average efficiency rating
efficiency_scores = [
a["annotations"]["efficiency"]
for a in annotations
if "efficiency" in a["annotations"]
]
print(f"\nAverage Efficiency: {sum(efficiency_scores) / len(efficiency_scores):.2f}")Step-Level Error Analysis
# Collect all step-level errors
error_counts = {}
for ann in annotations:
step_errors = ann["annotations"].get("error_type", {})
for step_idx, errors in step_errors.items():
for error in errors:
error_counts[error] = error_counts.get(error, 0) + 1
print("Error Type Distribution:")
for error, count in sorted(error_counts.items(), key=lambda x: -x[1]):
print(f" {error}: {count}")Analysis with DuckDB (via Parquet)
import duckdb
# Overall success rate
result = duckdb.sql("""
SELECT value, COUNT(*) as count
FROM 'output/parquet/annotations.parquet'
WHERE schema_name = 'task_success'
GROUP BY value
ORDER BY count DESC
""")
print(result)Step 7: Scaling Up
For larger evaluation projects (hundreds or thousands of traces), consider these configurations:
Multiple Annotators
Assign multiple annotators per trace for inter-annotator agreement:
annotation_task_config:
total_annotations_per_instance: 3
assignment_strategy: randomUsing Pre-Built Schemas
For a quick setup, use Potato's pre-built agent evaluation schemas:
annotation_schemes:
- preset: agent_task_success
- preset: agent_step_correctness
- preset: agent_error_taxonomy
- preset: agent_efficiencyQuality Control
Enable gold-standard instances for quality monitoring:
phases:
training:
enabled: true
data_file: "data/training_traces.jsonl"
passing_criteria:
min_correct: 4
total_questions: 5Adapting for Other Agent Types
OpenAI Function Calling
agentic:
enabled: true
trace_converter: openai
display_type: agent_traceAnthropic Tool Use
agentic:
enabled: true
trace_converter: anthropic
display_type: agent_traceMulti-Agent Systems (CrewAI/AutoGen)
agentic:
enabled: true
trace_converter: multi_agent
display_type: agent_trace
multi_agent:
agent_converters:
researcher: react
writer: anthropic
reviewer: openaiFor coding agents, Potato renders code diffs and terminal output with proper formatting:
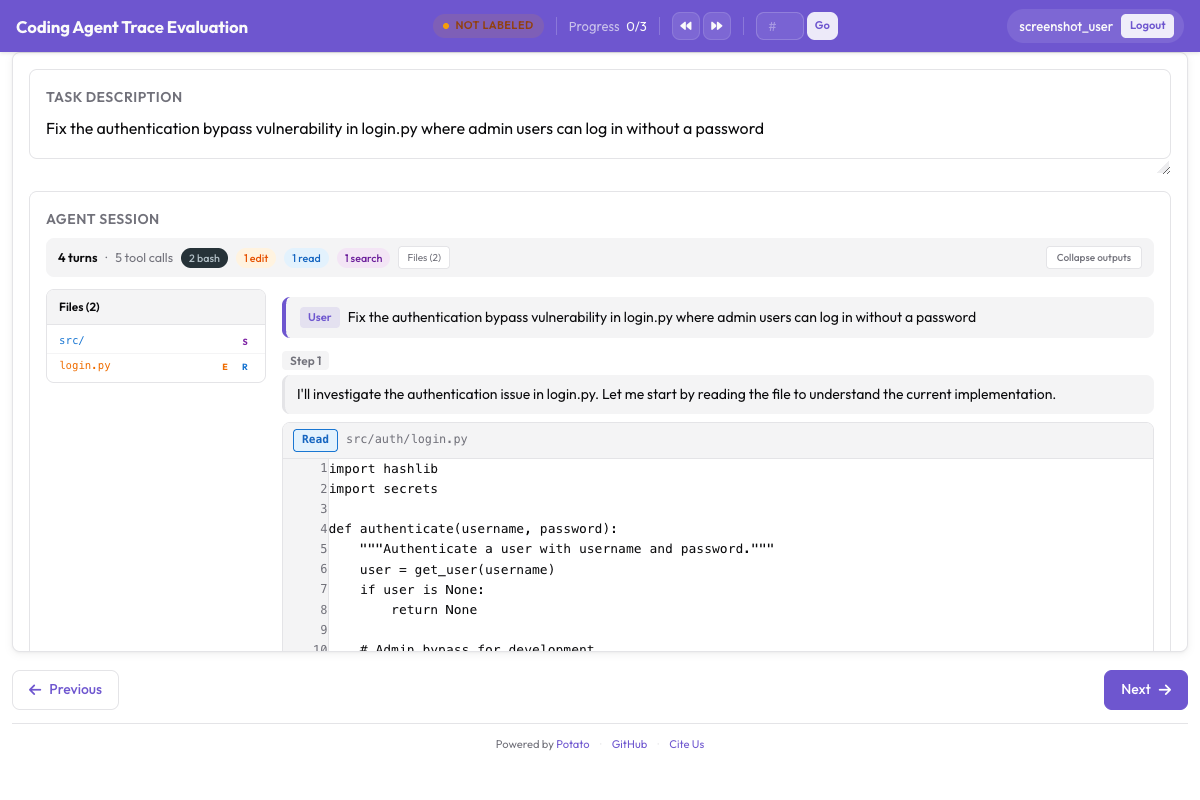
Web Browsing Agents
For web agents, switch to the web agent display:
agentic:
enabled: true
trace_converter: webarena
display_type: web_agent
web_agent_display:
screenshot_max_width: 900
overlay:
enabled: true
filmstrip:
enabled: trueSee Annotating Web Browsing Agents for a dedicated guide.
Summary
Evaluating agents by hand takes the right tooling, and Potato's agentic annotation system is built for it. It ships with 12 trace converters so you can pull in traces from most frameworks without reshaping them, three display types tuned for tool-use, web browsing, and conversational agents, per-turn ratings for step-level judgments, 9 pre-built schemas for the common evaluation dimensions, and Parquet export for when you sit down to analyze it all.
The thing to remember: "did the agent get the right answer?" is the easy question. The harder one is whether it reasoned correctly at every step, and that is the one per-step annotation answers. Aggregate metrics quietly average those mistakes away.
For implementation details, see the agent evaluation guide and the agent traces documentation.
Further Reading
- Agentic Annotation Documentation
- Annotating Web Browsing Agents
- Solo Mode -- combine agentic annotation with human-LLM collaborative evaluation
- Best-Worst Scaling -- rank agent outputs comparatively
- Parquet Export -- efficient export for analysis