Potato 2.6.2: एक संपूर्ण ओपन-सोर्स एजेंट-मूल्यांकन सूट
2.6.x शृंखला Potato को एक पूर्ण, मुफ़्त एजेंट-मूल्यांकन प्लेटफ़ॉर्म में बदल देती है: OpenTelemetry, LangGraph, CrewAI, और AutoGen से ट्रेस इंजेशन, एक क्लिक करने योग्य इंटरैक्शन ग्राफ़ के साथ मल्टी-एजेंट टीम एनोटेशन, GUI, वॉइस, और वीडियो के लिए मल्टीमोडल-एजेंट स्कीमा, साथ ही एक मॉडल एरिना, CI गेटिंग, और क्यूरेशन।
Potato 2.6 ने एजेंट मूल्यांकन की पहली लहर लाई: LLM-as-judge कैलिब्रेशन, प्रशिक्षण डेटा के लिए ट्रैजेक्टरी एडिटिंग, और तीन-पैन वाला eval_trace डिस्प्ले। तब से जारी 2.6.x पॉइंट रिलीज़ बाकी हिस्से को भर देती हैं। 2.6.2 के साथ, Potato एक संपूर्ण एजेंट-मूल्यांकन प्लेटफ़ॉर्म है: आप अपने स्वयं के एजेंट से ट्रेस कैप्चर कर सकते हैं, एकल एजेंट, मल्टी-एजेंट टीम, और मल्टीमोडल एजेंट को एनोटेट कर सकते हैं, उन्हें ऐसे LLM से आँक सकते हैं जिन पर आप भरोसा कर सकें, एक एरिना में मॉडल को रैंक कर सकते हैं, और CI में रिलीज़ को गेट कर सकते हैं। यह सब कुछ YAML में कॉन्फ़िगर किया जाता है और आपके अपने सर्वर पर रहता है।
 Potato मल्टी-एजेंट मूल्यांकन
Potato मल्टी-एजेंट मूल्यांकन
इनमें से अधिकांश ऐसी क्षमताएँ हैं जिनके लिए लोग वर्तमान में किसी होस्टेड प्लेटफ़ॉर्म को भुगतान करते हैं। Potato इन्हें मुफ़्त और सेल्फ़-होस्टेड तरीके से करता है। यहाँ बताया गया है कि 2.6.x शृंखला में क्या-क्या आया।
 2.6.x एजेंट-मूल्यांकन सूट, शुरू से अंत तक
2.6.x एजेंट-मूल्यांकन सूट, शुरू से अंत तक
ट्रेस अंदर लाएँ: एक कैप्चर SDK और खुले मानक
मूल्यांकन वास्तविक रन से शुरू होता है। नया potato_trace SDK किसी भी एजेंट को इंस्ट्रूमेंट करता है: किसी फ़ंक्शन को @traceable से डेकोरेट करें (सिंक या async) और नेस्टेड कॉल कैप्चर होकर Potato के इंजेशन एंडपॉइंट पर भेज दिए जाते हैं, साथ ही एक वैकल्पिक OpenTelemetry एक्सपोर्ट के साथ। Potato OpenTelemetry / OpenInference स्पैन और LangGraph, CrewAI, और AutoGen रन फ़ॉर्मेट भी इंजेस्ट करता है, इसलिए आप पहले से जिस फ़्रेमवर्क का उपयोग करते हैं, उससे आने वाले ट्रेस बिना किसी ग्लू कोड के एनोटेशन कतार में पहुँच जाते हैं। नए ट्रेस एक वेबहुक, एक पोलर, या एक देखी जा रही डायरेक्टरी के माध्यम से आ सकते हैं और आते ही एनोटेटर को असाइन किए जा सकते हैं।
संदर्भ: ट्रेसिंग SDK, ऑटोमेशन नियम।
पूरी टीम देखें: मल्टी-एजेंट मूल्यांकन
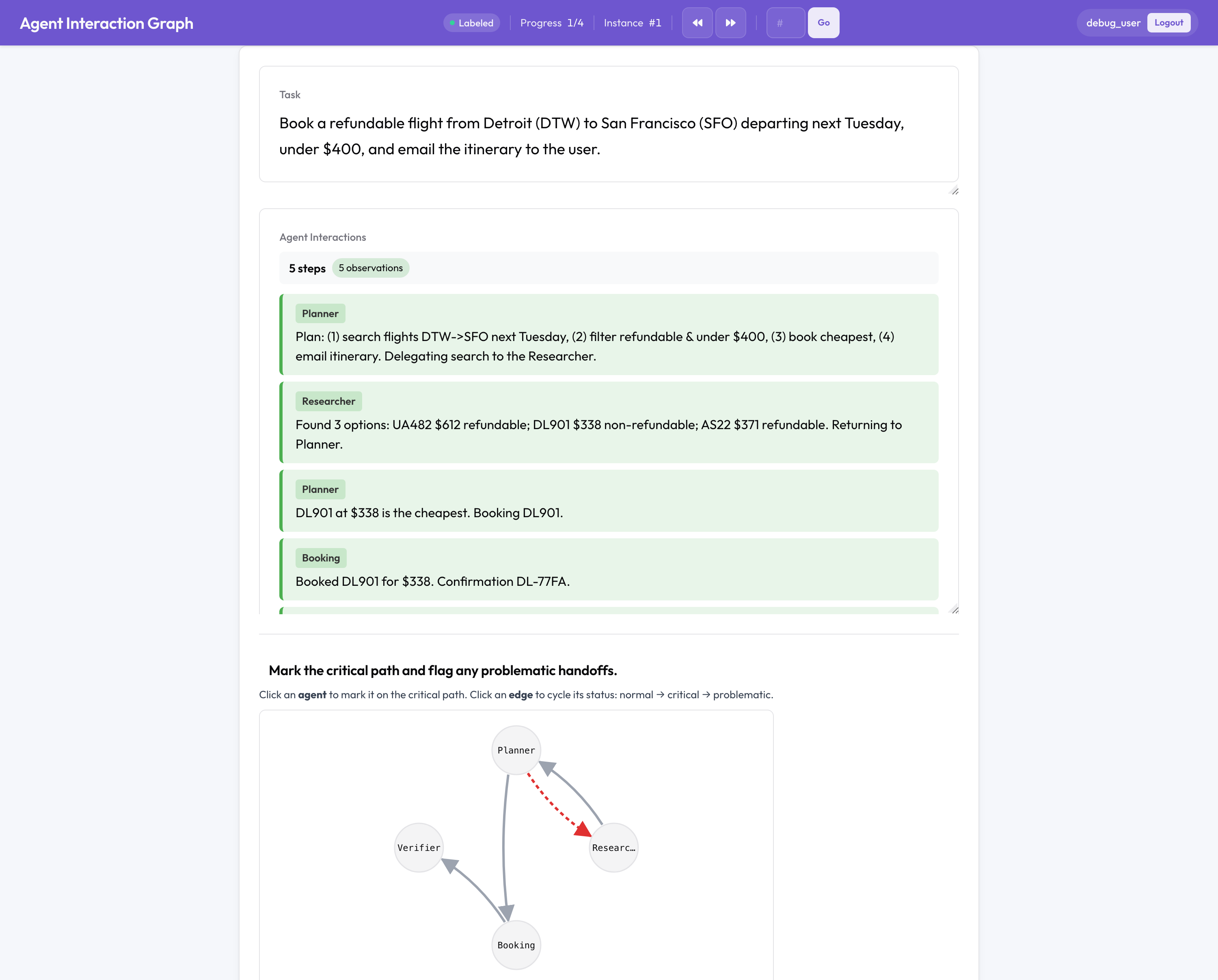
यह वह हिस्सा है जिसका कोई ओपन-सोर्स समकक्ष नहीं है। एक मल्टी-एजेंट रन एकल एजेंट से अलग तरीके से विफल होता है, एजेंटों के बीच, किसी हैंडऑफ़ पर, या इस बात में कि टीम कैसे संगठित की गई थी, इसलिए Potato एक सपाट ट्रांसक्रिप्ट के बजाय टीम की संरचना को एनोटेट करता है:
- एजेंटों और हैंडऑफ़ का एक क्लिक करने योग्य इंटरैक्शन ग्राफ़, जहाँ आप क्रिटिकल पाथ को चिह्नित करते हैं और समस्याग्रस्त एज को फ़्लैग करते हैं।
- विफलता एट्रिब्यूशन: ज़िम्मेदार एजेंट, निर्णायक चरण, और कारण चुनें, यानी Who&When एट्रिब्यूशन कार्य से लिया गया (एजेंट, चरण, कारण) त्रिक।
- हैंडऑफ़ समीक्षा: हर नियंत्रण हस्तांतरण एक कार्ड बन जाता है ताकि एजेंटों के बीच असंरेखण को फ़्लैग किया जा सके और गुणवत्ता का मूल्यांकन किया जा सके।
- प्रति-एजेंट और प्रति-टीम स्कोरकार्ड: प्रति एजेंट भूमिका निष्ठा, योगदान, और समन्वय, साथ ही साझा टीम आयाम और मील के पत्थर।
- एक टूल-कंटेंशन टाइमलाइन जो उन डेडलॉक और रेस को सामने लाती है जहाँ एजेंट एक ही संसाधन को एक साथ छूते हैं।
- कई एजेंटों और टर्न में फैलने वाली मिलीभगत, ग्रुपथिंक, और कैस्केडिंग त्रुटियों के लिए उभरते-व्यवहार टैगिंग।
 विफलता एट्रिब्यूशन: कौन-सा एजेंट, कौन-सा चरण, और क्यों
विफलता एट्रिब्यूशन: कौन-सा एजेंट, कौन-सा चरण, और क्यों
प्रत्येक के लिए YAML के साथ पूरा सेट मल्टी-एजेंट टीम मूल्यांकन में है, और गहन विश्लेषण मल्टी-एजेंट विफलताओं की डिबगिंग हर सतह को शुरू से अंत तक समझाता है। मार्गदर्शिका मल्टी-एजेंट सिस्टम का मूल्यांकन कैसे करें बताती है कि कब किसका उपयोग करें।
टेक्स्ट से आगे: मल्टीमोडल-एजेंट मूल्यांकन
एजेंट अब GUI चलाते हैं, वीडियो देखते हैं, और बोली जाने वाली बातचीत करते हैं, और प्रत्येक को एक ऐसी समीक्षा सतह की आवश्यकता है जो एक टेक्स्ट विजेट प्रदान नहीं कर सकता:
- GUI / कंप्यूटर-उपयोग ट्रैजेक्टरी: प्रति-चरण स्क्रीनशॉट और क्रिया, एक क्रिया फ़ैसला, और एक क्लिक-ग्राउंडिंग मार्कर जो दिखाता है कि क्लिक सही एलिमेंट पर पहुँचा या नहीं।
- फ़ुल-डुप्लेक्स वॉइस टाइमलाइन: बार्ज-इन डिटेक्शन और टर्न-टेकिंग स्कोरिंग के साथ एक डुअल-ट्रैक यूज़र/एजेंट टाइमलाइन।
- वीडियो टेम्पोरल ग्राउंडिंग: मॉडल के पूर्वानुमानित अंतराल के विरुद्ध एक लाइव IoU के साथ गोल्ड इवेंट अंतराल चिह्नित करें।
- स्पीच-ट्रांसक्रिप्ट त्रुटि टैगिंग, विज़ुअल-हैल्युसिनेशन फ़्लैग के साथ इंटरलीव्ड मल्टीमोडल रीज़निंग, और डॉक्यूमेंट टेबल-ग्रिड संरचना।
 कंप्यूटर-उपयोग समीक्षा: क्रिया की शुद्धता और क्लिक ग्राउंडिंग
कंप्यूटर-उपयोग समीक्षा: क्रिया की शुद्धता और क्लिक ग्राउंडिंग
दो गहन विश्लेषण इन्हें समझाते हैं: GUI और OS एजेंटों के लिए कंप्यूटर-उपयोग एजेंटों का मूल्यांकन, और बोली जाने वाली, वीडियो, और डॉक्यूमेंट एजेंटों के लिए वॉइस और वीडियो एजेंटों का मूल्यांकन। संदर्भ मल्टीमोडल-एजेंट मूल्यांकन है, और मार्गदर्शिका कंप्यूटर-उपयोग और मल्टीमोडल एजेंटों का मूल्यांकन है।
ऐसे जज जिन पर आप भरोसा कर सकें, और एक एरिना
आउटपुट को ग्रेड करने के लिए किसी LLM का उपयोग करना सामान्य बात है; 2.6.x का काम यह जानने के बारे में है कि उस पर कितना भरोसा किया जाए। जज कैलिब्रेशन मॉडल लेबल के विरुद्ध एक ब्लाइंड ह्यूमन पास चलाता है और सटीकता, कप्पा, और Expected Calibration Error की रिपोर्ट करता है। जज अलाइनमेंट आपके गोल्ड लेबल के विरुद्ध एक एकल जज को ट्यून करता है। और प्रोग्रामेटिक इवैल्युएटर बिना किसी सर्वर के चलते हुए ट्रैजेक्टरी और टेक्स्ट को स्वचालित रूप से स्कोर करते हैं (ट्रैजेक्टरी मैच, टूल-उपयोग शुद्धता, संदर्भ-मुक्त LLM-as-judge, और ह्यूरिस्टिक्स)।
आमने-सामने की तुलना के लिए, मॉडल एरिना एक प्रॉम्प्ट को कई मॉडलों को भेजता है, प्राथमिकताएँ इकट्ठा करता है, और OpenAI, Anthropic, Gemini, Ollama, और vLLM में एक विन-रेट लीडरबोर्ड बनाता है।
मूल्यांकन को सॉफ़्टवेयर की तरह मानें
ऑपरेशनल हिस्से मूल्यांकन को दोहराने योग्य बनाते हैं:
- डेटासेट और प्रयोग: वर्शन किए गए eval सेट, स्प्लिट, और रिग्रेशन डेल्टा के साथ साथ-साथ प्रयोग तुलना।
- CI मूल्यांकन: एक pytest प्लगइन जो तब बिल्ड को विफल कर देता है जब कोई प्रॉम्प्ट या मॉडल परिवर्तन एजेंट गुणवत्ता को किसी सीमा से अधिक गिरा देता है।
- ऑटोमेशन नियम: आने वाले प्रोडक्शन ट्रेस को नियम के अनुसार डेटासेट, इवैल्युएटर, या एनोटेशन कतार में रूट करें।
- सिमेंटिक क्यूरेशन: "इस विफलता जैसे ट्रेस खोजें" के लिए एक एम्बेडिंग इंडेक्स और सहेजे गए डायनामिक स्लाइस।
इसे प्राप्त करना
pip install --upgrade potato-annotationप्रत्येक नई सतह examples/agent-traces/ के अंतर्गत एक चलाने योग्य उदाहरण के साथ आती है, जिसमें interaction-graph/, failure-attribution/, gui-trajectory/, और temporal-grounding/ शामिल हैं। स्कीमा को चलते हुए देखने के लिए Potato को किसी एक की ओर इंगित करें:
python potato/flask_server.py start examples/agent-traces/interaction-graph/config.yaml -p 8000यदि आप टूल का मूल्यांकन कर रहे हैं, तो Potato बनाम LangSmith और Langfuse में दी गई तुलना और मार्गदर्शिका ओपन-सोर्स एनोटेशन टूल की तुलना बताती है कि प्रत्येक कहाँ फ़िट बैठता है। हमें किन ट्रेस फ़ॉर्मेट का समर्थन करना चाहिए और प्रश्नों का GitHub रिपॉज़िटरी पर स्वागत है।