वॉइस और वीडियो एजेंटों का मूल्यांकन
Potato में बोलने वाले, वीडियो, और डॉक्यूमेंट एजेंटों के लिए ह्यूमन मूल्यांकन का एक वॉकथ्रू: एक डुअल-ट्रैक टाइमलाइन पर टर्न-टेकिंग को स्कोर करना, लाइव IoU के साथ वीडियो इवेंट को ग्राउंड करना, स्पीच त्रुटियों को टैग करना, और टेबल संरचना को चिह्नित करना।
ऐसे एजेंट जो बोलते हैं, वीडियो देखते हैं, और डॉक्यूमेंट पढ़ते हैं, उन तरीकों से विफल होते हैं जो एक टेक्स्ट बॉक्स नहीं दिखा सकता। एक वॉइस एजेंट की गलतियाँ टर्न के बीच की सीवनों पर रहती हैं; एक वीडियो एजेंट का उत्तर एक समय अंतराल है, न कि एक वाक्य; एक डॉक्यूमेंट एजेंट की त्रुटि एक गलत-पढ़ी गई टेबल सेल है। इनमें से प्रत्येक को मोडैलिटी के अनुरूप आकार की एक समीक्षा सतह की आवश्यकता है। Potato अपने मौजूदा इमेज और ऑडियो डिस्प्ले के साथ-साथ ऐसी चार सतहें जोड़ता है — वॉइस, वीडियो, स्पीच, और डॉक्यूमेंट। पूरा संदर्भ मल्टीमोडल-एजेंट मूल्यांकन है।
 एक सादा टेक्स्ट विजेट एक बार्ज-इन, एक इवेंट अंतराल, या एक टेबल सेल को व्यक्त नहीं कर सकता
एक सादा टेक्स्ट विजेट एक बार्ज-इन, एक इवेंट अंतराल, या एक टेबल सेल को व्यक्त नहीं कर सकता
मैं एक वॉइस एजेंट की टर्न-टेकिंग का मूल्यांकन कैसे करूँ?
बोलने वाले एजेंट सीमाओं पर टूटते हैं: उपयोगकर्ता को बीच में काटना, उन पर बोलना, या इतनी देर तक रुकना कि उपयोगकर्ता हार मान ले। voice_interaction स्कीमा बातचीत को एक डुअल-ट्रैक टाइमलाइन के रूप में रखता है — एक उपयोगकर्ता लेन और एक एजेंट लेन — और उन ओवरलैप क्षेत्रों को हाइलाइट करता है जहाँ दोनों एक साथ बोलते हैं (Full-Duplex-Bench, 2025)। आप प्रत्येक ओवरलैप को वर्गीकृत करते हैं और समग्र टर्न-टेकिंग का मूल्यांकन करते हैं; प्रदान किए जाने पर ऑडियो इनलाइन चलता है।
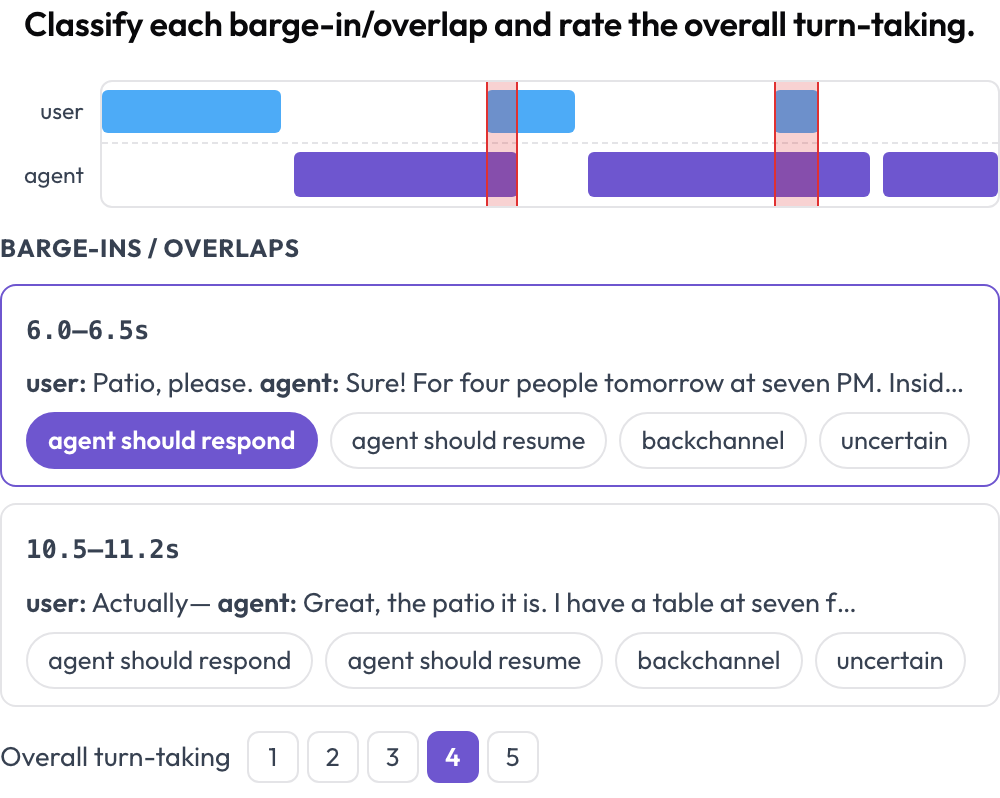 बार्ज-इन डिटेक्शन और टर्न-टेकिंग स्कोरिंग के साथ डुअल-ट्रैक वॉइस टाइमलाइन
बार्ज-इन डिटेक्शन और टर्न-टेकिंग स्कोरिंग के साथ डुअल-ट्रैक वॉइस टाइमलाइन
annotation_schemes:
- annotation_type: voice_interaction
name: turn_taking
description: "Classify each barge-in/overlap and rate the overall turn-taking."
turns_key: turns
speaker_key: speaker
user_speakers: [user, human, caller]
overlap_labels: [agent_should_respond, agent_should_resume, backchannel, uncertain]
rating_scale: 5ओवरलैप रेंडर समय पर टर्न के समय से गणना किए जाते हैं, इसलिए एक फ़ुल-डुप्लेक्स बातचीत जिसे एक सपाट ट्रांसक्रिप्ट "उन दोनों ने कुछ कहा" में समतल कर देगा, ठोस, लेबल करने योग्य क्षणों का एक समूह बन जाती है।
मैं एक वीडियो एजेंट की टेम्पोरल ग्राउंडिंग को कैसे स्कोर करूँ?
"लक्ष्य कब घटित होता है?" का एक वीडियो एजेंट का उत्तर एक अंतराल है, इसलिए आप उसे एक के रूप में स्कोर करते हैं। temporal_grounding स्कीमा आपको एक स्क्रबर देता है जहाँ आप प्रत्येक इवेंट प्रॉम्प्ट के लिए गोल्ड [start, end] को चिह्नित करते हैं, प्लेहेड को कैप्चर करके या सेकंड टाइप करके। जब डेटा मॉडल के पूर्वानुमानित अंतराल को रखता है, तो जैसे-जैसे आप समायोजित करते हैं, एक लाइव IoU और एक दो-बार मिनी-टाइमलाइन अपडेट होती है (TimeScope, 2025)।
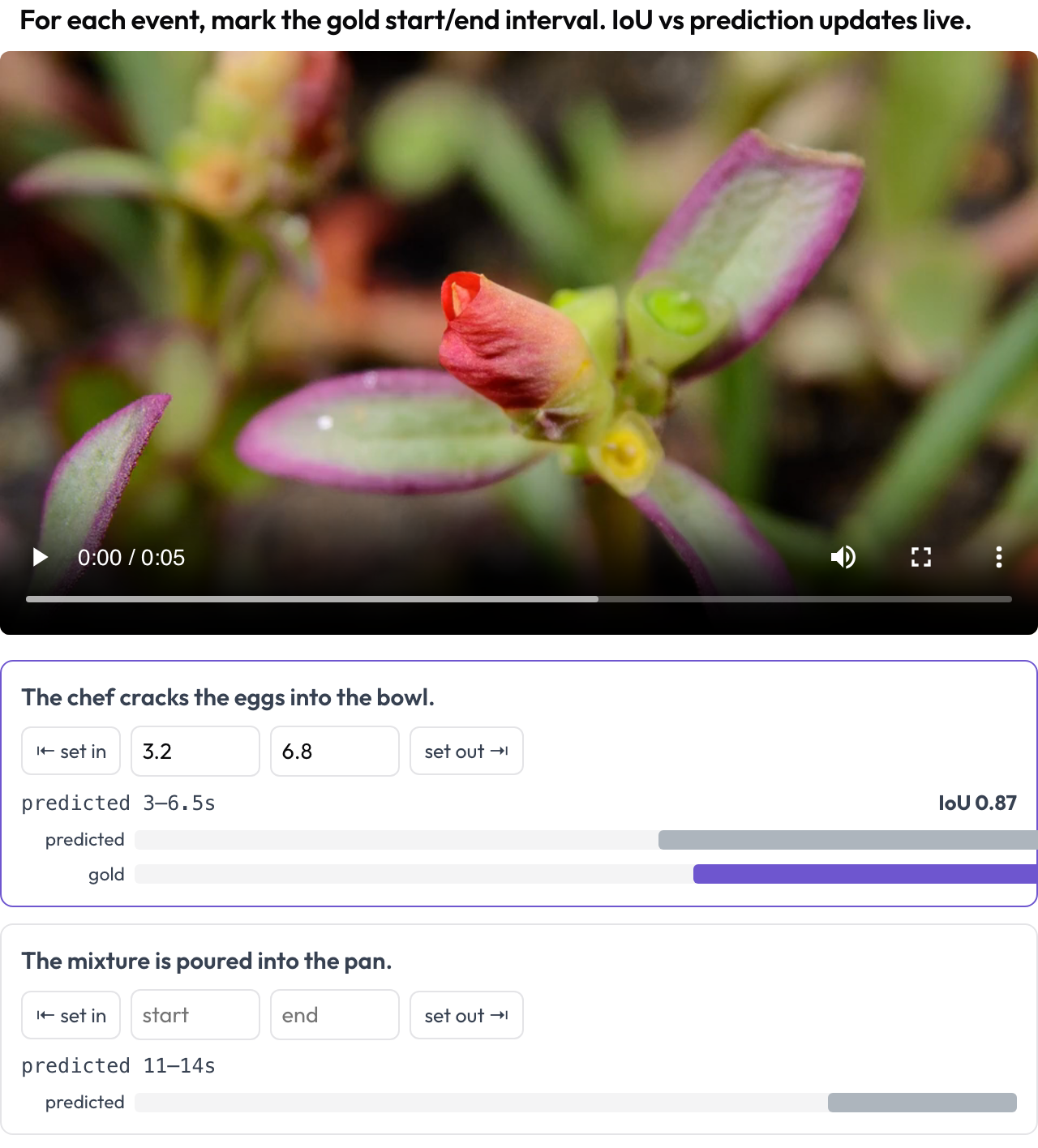 वीडियो पर गोल्ड इवेंट अंतराल को मॉडल के पूर्वानुमान के विरुद्ध एक लाइव IoU के साथ चिह्नित करें
वीडियो पर गोल्ड इवेंट अंतराल को मॉडल के पूर्वानुमान के विरुद्ध एक लाइव IoU के साथ चिह्नित करें
annotation_schemes:
- annotation_type: temporal_grounding
name: grounding
description: "Mark the gold start/end interval for each event. IoU vs prediction updates live."
video_key: video
events_key: eventsयह पूर्वानुमानित-बनाम-गोल्ड स्थानीयकरण के लिए बनाया गया है, जो सामान्य सेगमेंट लेबलिंग से एक अलग काम है: आप स्कोर कर रहे हैं कि मॉडल का स्पैन सत्य के कितना करीब है, और जैसे-जैसे आप सीमा को खींचते हैं, IoU को बदलते देखना इसे तत्काल बना देता है।
स्पीच ट्रांसक्रिप्ट, रीज़निंग, और टेबल का क्या?
तीन और सतहें बाकी मल्टीमोडल विस्तार को कवर करती हैं:
- स्पीच ट्रांसक्रिप्ट (
speech_transcript): प्रत्येक समय-संरेखित सेगमेंट एक कार्ड है; आप ASR/TTS त्रुटियों, गलत उच्चारणों, और अस्पष्टताओं को टैग करते हैं और टेक्स्ट को इनलाइन सही करते हैं (Speak & Improve, 2025)। यह टर्न-टेकिंग व्यू का सेगमेंट-स्तरीय पूरक है। - इंटरलीव्ड रीज़निंग (
multimodal_reasoning): एक टेक्स्ट-इमेज-टूल ट्रेस जिसे टाइप किए गए ब्लॉक के रूप में रेंडर किया गया है; आप प्रत्येक चरण की सुसंगतता का मूल्यांकन करते हैं और उन विज़ुअल हैल्युसिनेशन को फ़्लैग करते हैं जहाँ रीज़निंग इमेज से नहीं निकलती (Multimodal RewardBench 2, 2025)। - डॉक्यूमेंट टेबल (
table_grid): आप ग्रिड आयाम सेट करते हैं और सेल पर क्लिक करके उनकी भूमिका चिह्नित करते हैं — डेटा, कॉलम हेडर, रो हेडर, खाली — उस संरचना को कैप्चर करते हुए जिसे बाउंडिंग बॉक्स नहीं कर सकते।
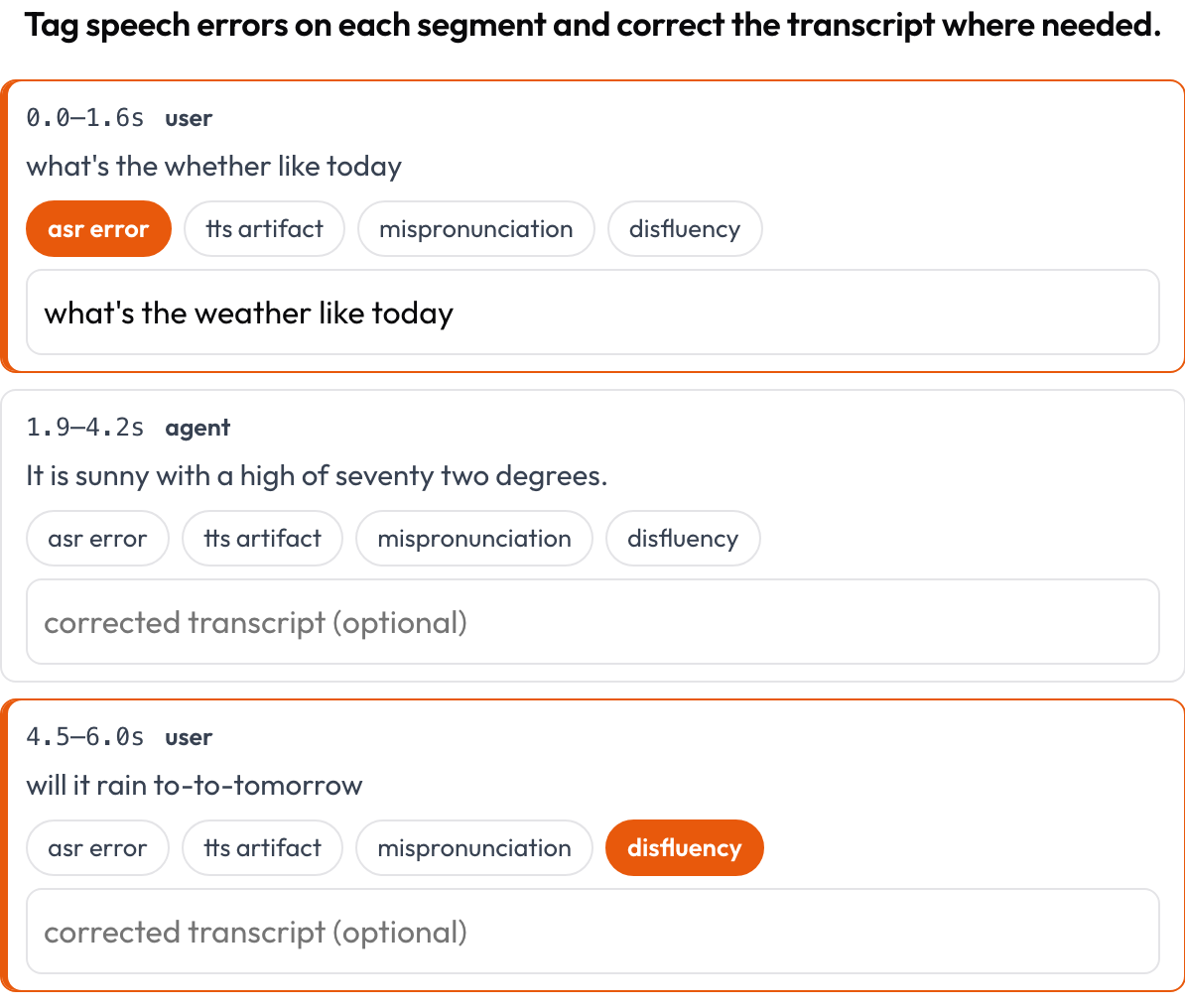 प्रति सेगमेंट ASR/TTS/उच्चारण त्रुटियों को टैग करें और ट्रांसक्रिप्ट को इनलाइन सही करें
प्रति सेगमेंट ASR/TTS/उच्चारण त्रुटियों को टैग करें और ट्रांसक्रिप्ट को इनलाइन सही करें
annotation_schemes:
- annotation_type: speech_transcript
name: speech_errors
description: "Tag speech errors on each segment and correct the transcript where needed."
segments_key: segments
error_types: [asr_error, tts_artifact, mispronunciation, disfluency]
allow_correction: true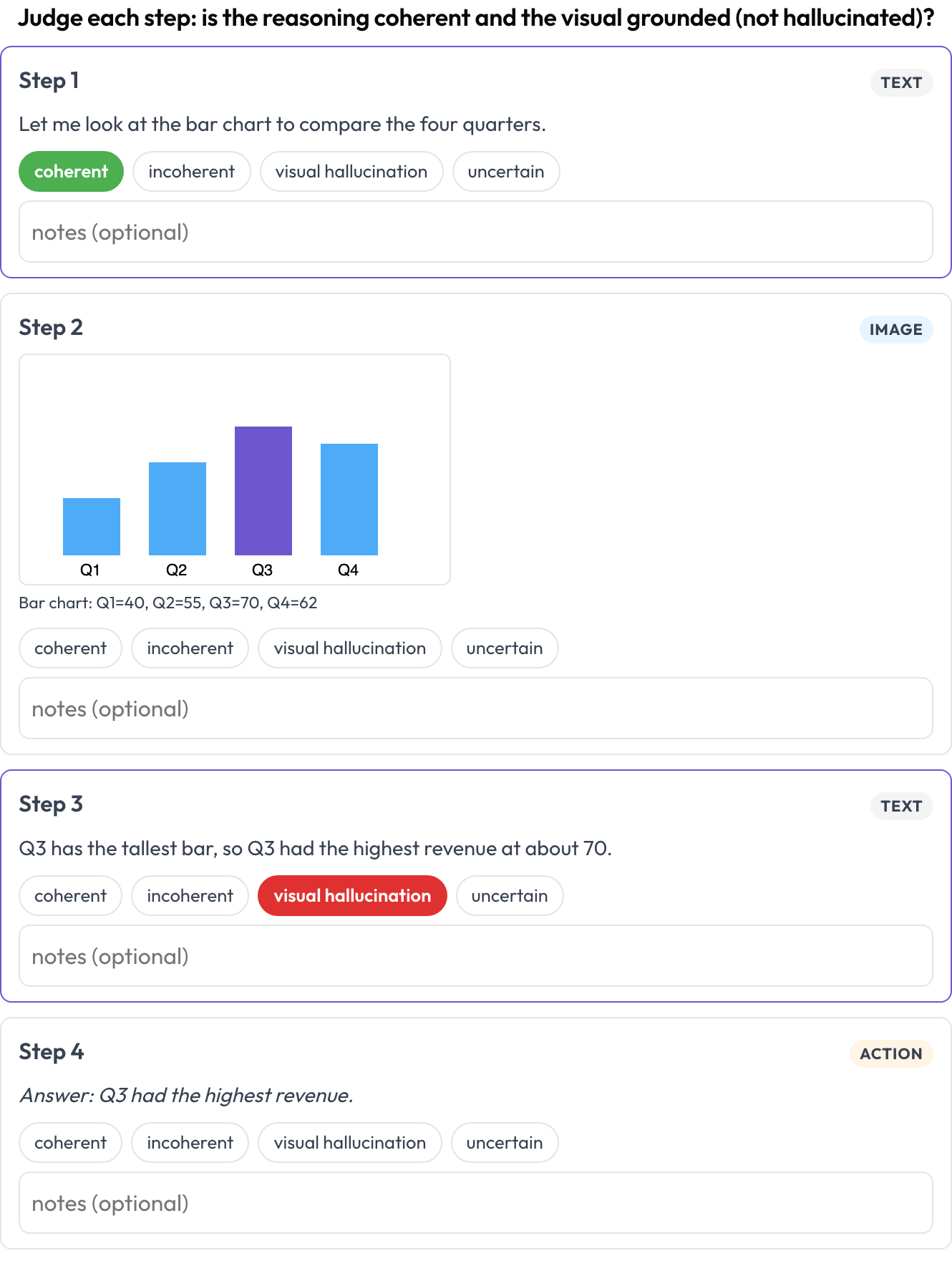 एक टेक्स्ट-इमेज-टूल रीज़निंग ट्रेस के प्रत्येक चरण को सुसंगतता और विज़ुअल हैल्युसिनेशन के लिए आँकें
एक टेक्स्ट-इमेज-टूल रीज़निंग ट्रेस के प्रत्येक चरण को सुसंगतता और विज़ुअल हैल्युसिनेशन के लिए आँकें
इनमें से कई स्कीमा एक ही कार्य पर चल सकती हैं, इसलिए एक एकल डॉक्यूमेंट-एजेंट रन को एक साथ टेबल संरचना और रीज़निंग सुसंगतता के लिए स्कोर किया जा सकता है।
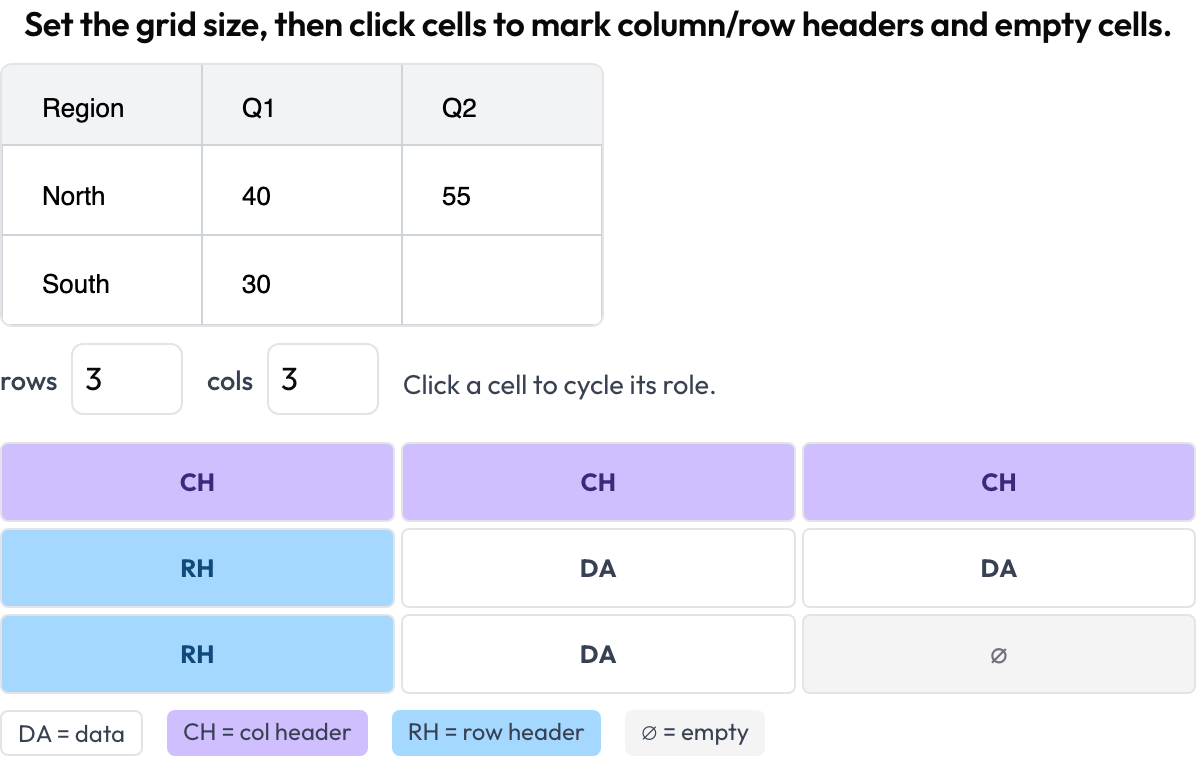 डॉक्यूमेंट-टेबल सेल संरचना को एनोटेट करें: कॉलम और रो हेडर, डेटा, और खाली सेल
डॉक्यूमेंट-टेबल सेल संरचना को एनोटेट करें: कॉलम और रो हेडर, डेटा, और खाली सेल
मैं इसे कैसे सेट करूँ?
प्रत्येक सतह examples/agent-traces/ के अंतर्गत एक चलाने योग्य उदाहरण के साथ आती है:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/temporal-grounding/config.yaml -p 8000आपका डेटा टाइमस्टैम्प के साथ टर्न, सेगमेंट, या इवेंट के रूप में आता है; सतह रेंडर समय पर उनसे अपनी टाइमलाइन प्राप्त करती है। GUI और OS एजेंटों के लिए, साथी लेख कंप्यूटर-उपयोग एजेंटों का मूल्यांकन है।
आगे पढ़ने के लिए
- मल्टीमोडल-एजेंट मूल्यांकन — पूरा स्कीमा संदर्भ
- कंप्यूटर-उपयोग और मल्टीमोडल एजेंटों का मूल्यांकन — मार्गदर्शिका, एक स्कीमा-चयन तालिका के साथ
- कंप्यूटर-उपयोग एजेंटों का मूल्यांकन, चरण दर चरण — मल्टीमोडल सतहों का GUI और OS भाग
- Potato 2.6.2: एक संपूर्ण ओपन-सोर्स एजेंट-मूल्यांकन सूट — 2.6.x शृंखला में सब कुछ