मल्टी-एजेंट विफलताओं की डिबगिंग: एक वॉकथ्रू
Potato का उपयोग करके यह पता लगाना कि एक मल्टी-एजेंट LLM सिस्टम क्यों विफल हुआ: इंटरैक्शन ग्राफ़, विफलता एट्रिब्यूशन, हैंडऑफ़ समीक्षा, प्रति-एजेंट स्कोरकार्ड, टूल-कंटेंशन टाइमलाइन, और उभरते-व्यवहार टैगिंग।
जब एजेंटों की एक टीम विफल होती है, तो कठिन हिस्सा विफलता को नोटिस करना नहीं है — यह पता लगाना है कि किस एजेंट ने इसे किस चरण पर पैदा किया, और क्या असली समस्या दो ऐसे एजेंटों के बीच एक खराब हैंडऑफ़ थी जो अलग-अलग अपने आप में ठीक थे। यह वॉकथ्रू उन छह Potato सतहों से गुज़रता है जो इसी के लिए बनी हैं, उसी क्रम में जिस क्रम में आप वास्तव में एक टूटे हुए रन पर उनका उपयोग करेंगे। यहाँ सब कुछ YAML में कॉन्फ़िगर किया जाता है और आपके अपने सर्वर पर चलता है; पूरा स्कीमा संदर्भ मल्टी-एजेंट टीम मूल्यांकन है।
एक मल्टी-एजेंट सिस्टम कई LLM एजेंट होते हैं जिनकी अलग-अलग भूमिकाएँ होती हैं — एक प्लानर, एक कोडर, एक रिव्यूअर — जो संदेश पास करते हैं और नियंत्रण सौंपते हैं। ये सिस्टम क्यों टूटते हैं, इस पर शोध, MAST टैक्सोनॉमी (Why Do Multi-Agent LLM Systems Fail?), ने पाया कि अधिकांश विफलताएँ अंतर-एजेंट होती हैं: किसी हैंडऑफ़ पर छूट गई एक बाधा, एक ऐसी टीम जो कभी अपने ही काम की पुष्टि नहीं करती, एजेंट एक-दूसरे की बात अनसुनी करते हुए। एक सपाट चैट ट्रांसक्रिप्ट ठीक इन्हीं को छुपा देता है, क्योंकि जो गलत हुआ वह दो संदेशों के बीच की जगह में रहता है, किसी एक के भीतर नहीं।
 विफलता एजेंटों के बीच है, किसी हैंडऑफ़ पर, एक ट्रांसक्रिप्ट के भीतर नहीं
विफलता एजेंटों के बीच है, किसी हैंडऑफ़ पर, एक ट्रांसक्रिप्ट के भीतर नहीं
मैं एक मल्टी-एजेंट रन की संरचना कैसे देखूँ?
टेक्स्ट से नहीं, रन के आकार से शुरुआत करें। agent_interaction_graph स्कीमा पूरे रन को एक डायरेक्टेड ग्राफ़ के रूप में रेंडर करता है: नोड एजेंट हैं, एज उनके बीच के हैंडऑफ़ हैं, मोटे एज का अर्थ अधिक ट्रैफ़िक। आप किसी नोड को क्रिटिकल पाथ पर चिह्नित करने के लिए उस पर क्लिक करते हैं और किसी एज को सामान्य से क्रिटिकल और फिर समस्याग्रस्त तक बदलने के लिए उस पर क्लिक करते हैं।
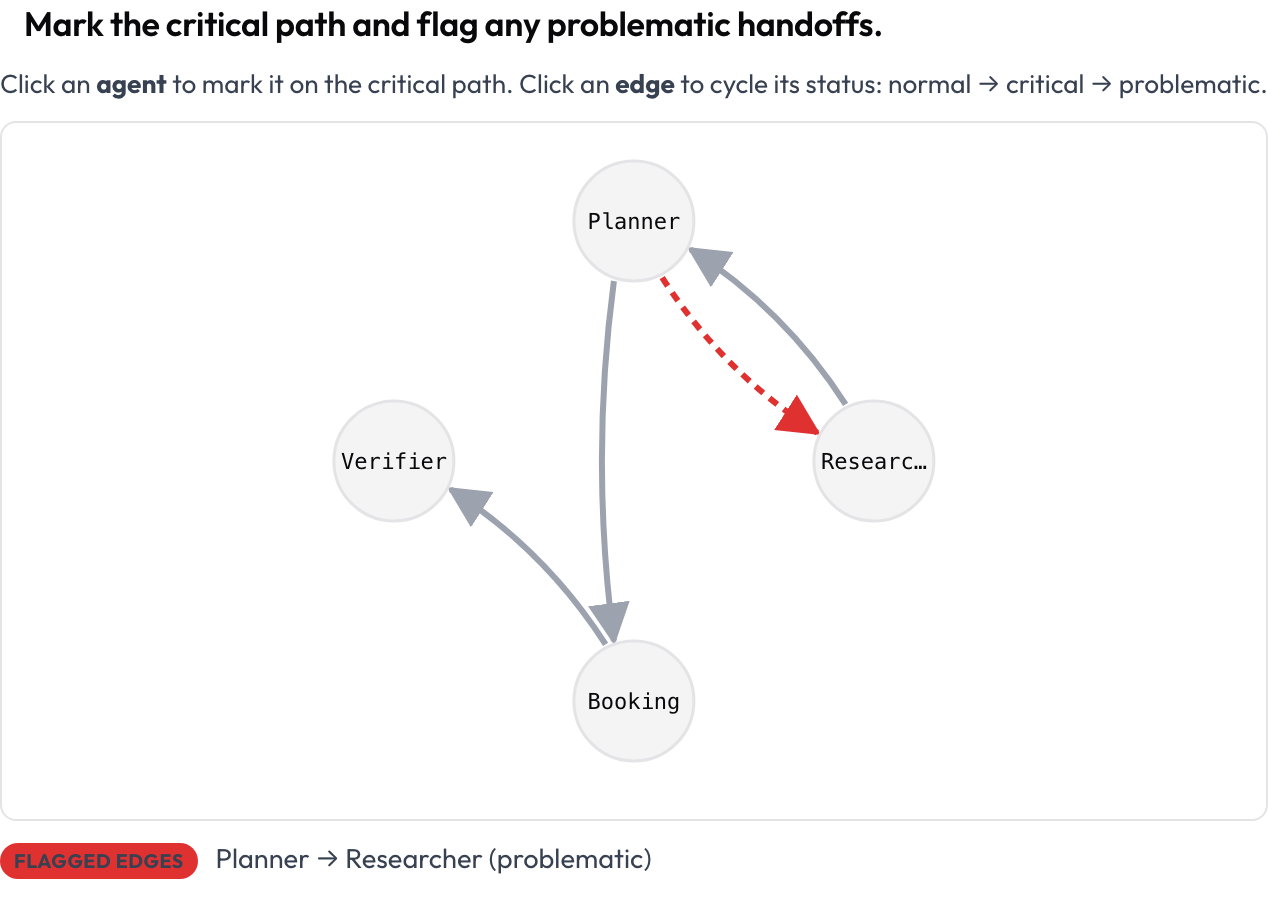 क्रिटिकल पाथ को चिह्नित करें और समस्याग्रस्त हैंडऑफ़ को फ़्लैग करें
क्रिटिकल पाथ को चिह्नित करें और समस्याग्रस्त हैंडऑफ़ को फ़्लैग करें
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentग्राफ़ ट्रेस से स्वचालित रूप से लेआउट किया जाता है, इसलिए आप कुछ भी नहीं बनाते। हर नोड और एज कीबोर्ड-फ़ोकस करने योग्य है और एक टेक्स्ट सारांश क्रिटिकल नोड और फ़्लैग किए गए एज को सूचीबद्ध करता है, इसलिए अर्थ कभी केवल रंग पर नहीं टिकता। यह व्यू "क्या किससे बात कर रहा था, और पाथ कहाँ टेढ़ा हुआ" का उत्तर देने का सबसे तेज़ तरीका है।
मैं एक मल्टी-एजेंट विफलता को एक एजेंट के लिए कैसे एट्रिब्यूट करूँ?
एक बार जब आप रन देख सकें, तो विफलता को पिन करें। failure_attribution स्कीमा विफलता-एट्रिब्यूशन साहित्य से वह त्रिक माँगता है (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, Who&When डेटासेट): ज़िम्मेदार एजेंट, निर्णायक चरण, और कारण। एजेंट ड्रॉपडाउन और स्टेप पिकर ट्रेस के अपने टर्न से भरे जाते हैं, इसलिए आप विफलता को केवल उसी एजेंट और चरण के लिए एट्रिब्यूट कर सकते हैं जो वास्तव में घटित हुआ।
 विफलता को ज़िम्मेदार एजेंट, निर्णायक चरण, और क्यों के लिए एट्रिब्यूट करें
विफलता को ज़िम्मेदार एजेंट, निर्णायक चरण, और क्यों के लिए एट्रिब्यूट करें
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agentएट्रिब्यूशन को एक सफलता/विफलता रेडियो के साथ जोड़ने का अर्थ है कि त्रिक केवल उन्हीं रन पर इकट्ठा किया जाता है जो विफल हुए, जो एनोटेटर के समय को उन्हीं मामलों पर रखता है जो संकेत रखते हैं।
और खुद हैंडऑफ़ का क्या?
एट्रिब्यूशन एक निर्णायक चरण का नाम लेता है। हैंडऑफ़ समीक्षा हर नियंत्रण हस्तांतरण को देखती है। जहाँ भी कार्यरत एजेंट लगातार टर्न के बीच बदलता है, Potato एक हैंडऑफ़ कार्ड A → B जारी करता है, और आप फ़्लैग करते हैं कि पास में क्या गलत हुआ — सूचना हानि, एक छूटी हुई बाधा, गड़बड़ी, लक्ष्य बहाव — और गुणवत्ता का मूल्यांकन करते हैं। विफलता के तरीके MAST की अंतर-एजेंट श्रेणी और "इकोइंग" परिघटना से आते हैं (Zhang et al., 2025)।
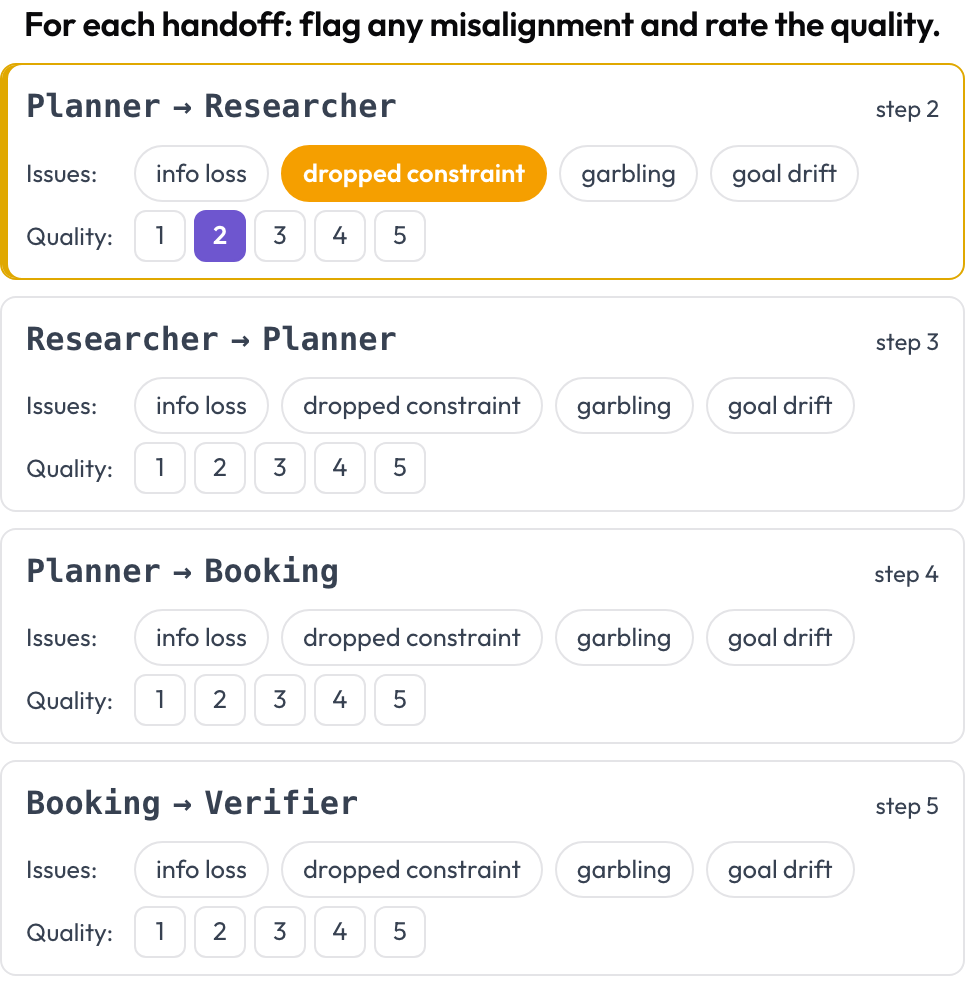 हर हैंडऑफ़ पर अंतर-एजेंट असंरेखण को फ़्लैग करें और उसकी गुणवत्ता का मूल्यांकन करें
हर हैंडऑफ़ पर अंतर-एजेंट असंरेखण को फ़्लैग करें और उसकी गुणवत्ता का मूल्यांकन करें
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5हैंडऑफ़ रेंडर समय पर निकाले जाते हैं, इसलिए कोई मैनुअल सेटअप नहीं है। यह आमतौर पर वही जगह है जहाँ "हर एजेंट ठीक लग रहा था, फिर भी टीम विफल हुई" वाले मामले सुलझते हैं: बाधा एजेंट A में जीवित थी और एजेंट B तक आते-आते चली गई।
मैं एजेंटों और टीम को कैसे स्कोर करूँ?
एक विफलता आपको बताती है कि एक बार क्या टूटा। एक स्कोरकार्ड आपको बताता है कि क्या कोई डिज़ाइन कई रन में अच्छा है। agent_scorecard स्कीमा एक साथ दो स्तरों को स्कोर करता है (MultiAgentBench, Zhou et al., ACL 2025): प्रत्येक एजेंट को भूमिका निष्ठा, योगदान, और समन्वय पर, और टीम को उसके अपने साझा आयामों पर, वैकल्पिक मील के पत्थरों के साथ। एजेंट पंक्तियाँ ट्रेस से आती हैं, इसलिए मैट्रिक्स उससे मेल खाता है जिसने वास्तव में भाग लिया।
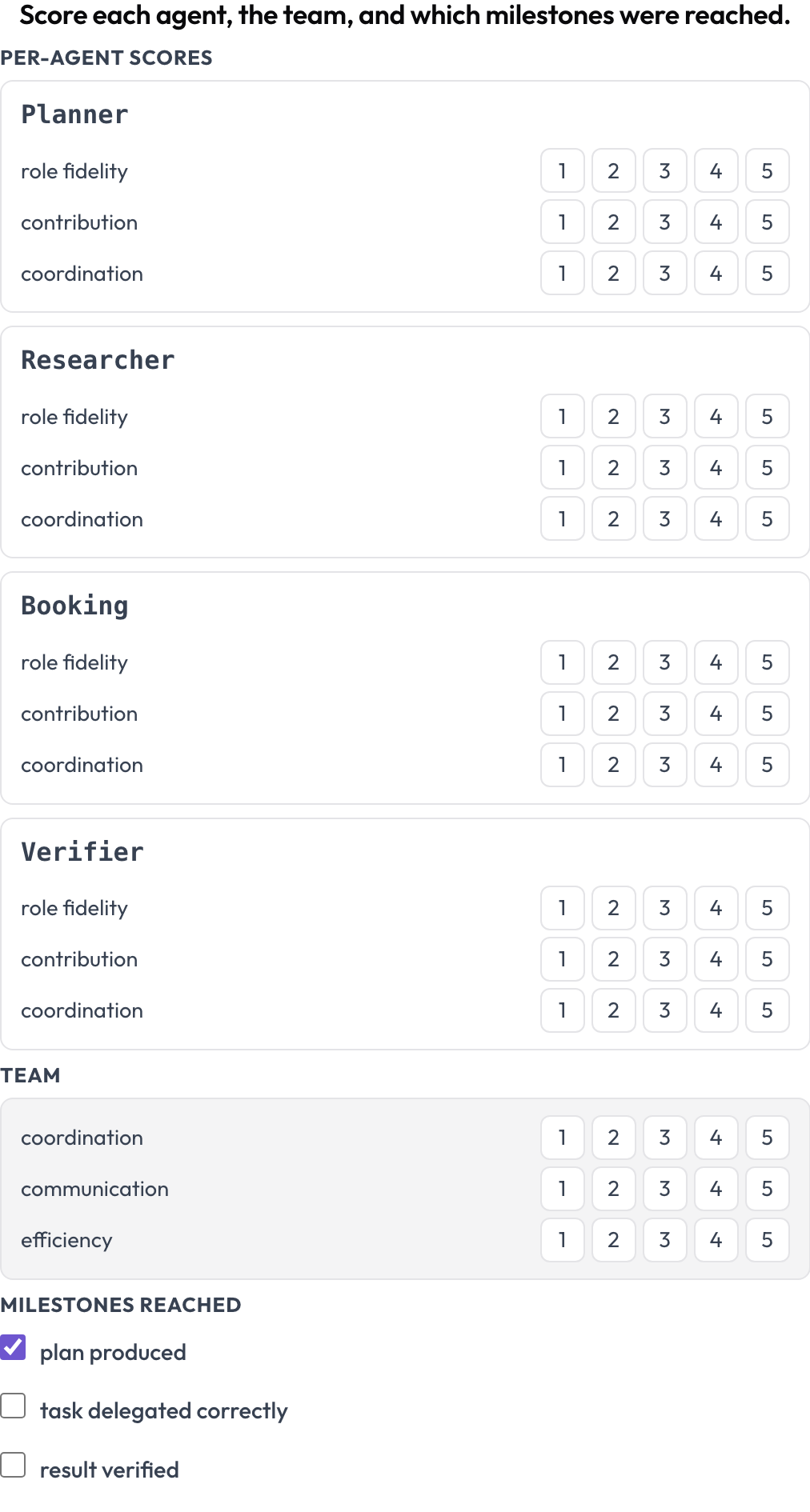 प्रत्येक एजेंट को भूमिका निष्ठा, योगदान, और समन्वय पर स्कोर करें, साथ ही टीम को
प्रत्येक एजेंट को भूमिका निष्ठा, योगदान, और समन्वय पर स्कोर करें, साथ ही टीम को
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]एक खराब समन्वित टीम के भीतर फँसा एक मज़बूत एजेंट यहाँ कम टीम आयामों के बगल में एक उच्च एजेंट पंक्ति के रूप में दिखाई देता है, जो वही पैटर्न है जो आप तब चाहते हैं जब आप एक ही कार्यों पर सीक्वेंशियल बनाम हायरार्किकल बनाम ग्रुप-चैट ऑर्केस्ट्रेशन की तुलना कर रहे हों।
और समवर्तीता और सामूहिक विफलताओं का क्या?
दो और सतहें ऐसी विफलताएँ पकड़ती हैं जिन्हें एक टर्न-दर-टर्न पठन नहीं पकड़ सकता। tool_contention टाइमलाइन प्रत्येक एजेंट को उसकी अपनी लेन पर रखती है और उन क्षेत्रों को हाइलाइट करती है जहाँ दो कॉल एक ही संसाधन को ओवरलैपिंग समय पर छूते हैं, जिसे आप डेडलॉक, सर्कुलर वेट, रेस कंडीशन, या सौम्य के रूप में वर्गीकृत करते हैं (DPBench, 2026)।
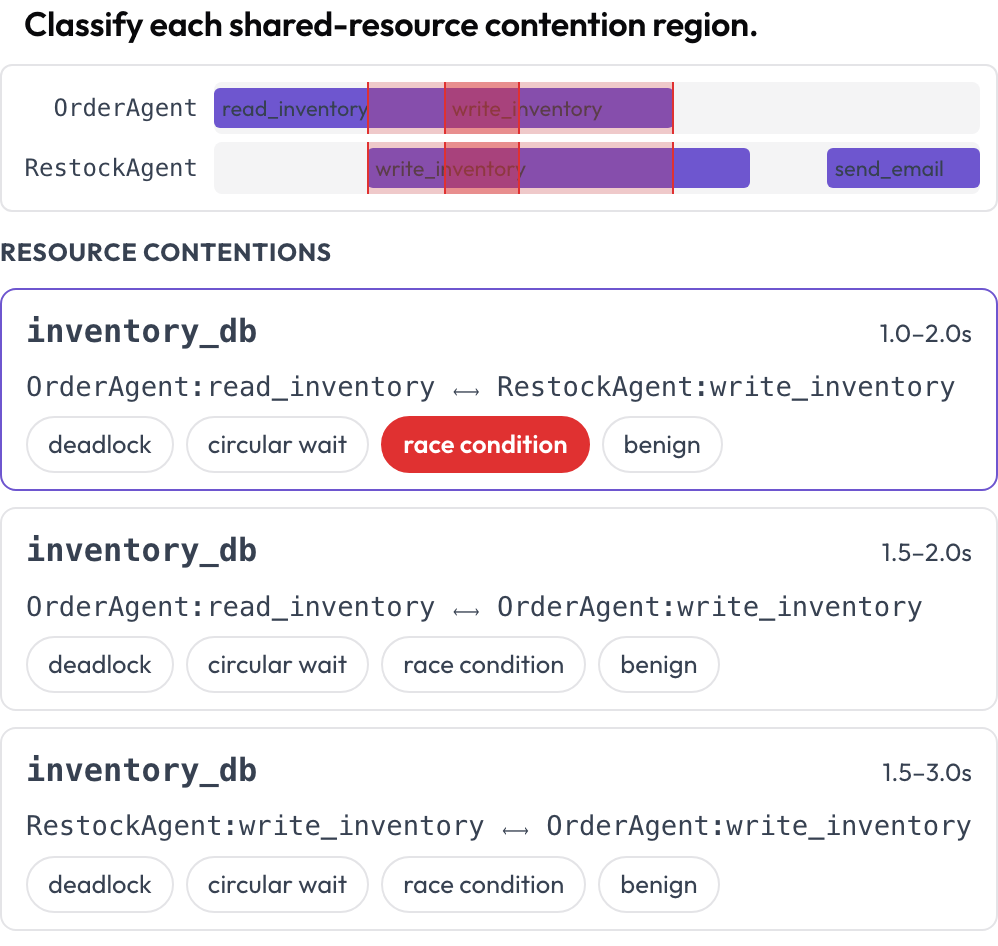 एक प्रति-एजेंट टूल-कॉल टाइमलाइन पर डेडलॉक और रेस कंडीशन पहचानें
एक प्रति-एजेंट टूल-कॉल टाइमलाइन पर डेडलॉक और रेस कंडीशन पहचानें
और emergent_behavior उन विफलताओं को संभालता है जो किसी एक चरण पर स्थित होने के बजाय सामूहिक होती हैं — मिलीभगत, ग्रुपथिंक, कैस्केडिंग त्रुटियाँ, भूमिका बहाव। एक उभरता व्यवहार एक सतत अवधि नहीं है; यह भाग लेने वाले टर्न का एक समूह है, संभवतः अलग-अलग एजेंटों से, इसलिए आप उन टर्न को चेक करते हैं जो भाग लेते हैं और एक नोट जोड़ते हैं।
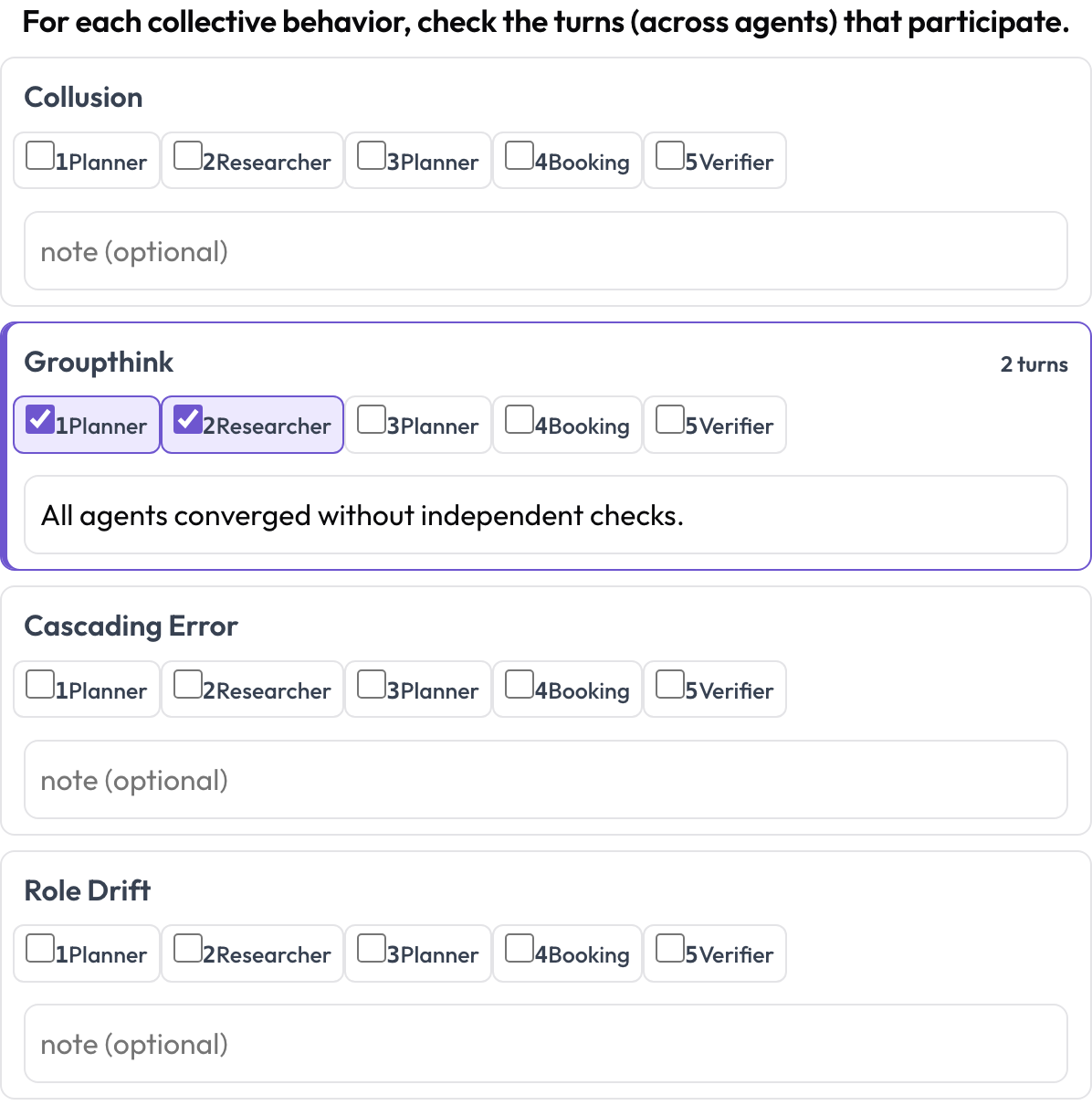 एजेंटों और टर्न में मिलीभगत, ग्रुपथिंक, और कैस्केडिंग त्रुटियों को टैग करें
एजेंटों और टर्न में मिलीभगत, ग्रुपथिंक, और कैस्केडिंग त्रुटियों को टैग करें
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: trueइसे क्रम में रखना
एक वास्तविक टूटे हुए रन पर क्रम आमतौर पर यह होता है: आकार देखने के लिए इंटरैक्शन ग्राफ़ पढ़ें, निर्णायक चरण का नाम लेने के लिए विफलता एट्रिब्यूशन का उपयोग करें, यदि निर्णायक चरण एक हस्तांतरण था तो हैंडऑफ़ समीक्षा खोलें, और जब विफलता एक एजेंट के बजाय समय या समूह के बारे में हो तो कंटेंशन टाइमलाइन या उभरते-व्यवहार टैगिंग की ओर बढ़ें। जब आप एक रन को डिबग करने के बजाय डिज़ाइनों की तुलना कर रहे हों तो स्कोरकार्ड से स्कोर करें। एट्रिब्यूशन पर सहमति को उसी तरह मापें जैसे आप किसी भी व्यक्तिपरक लेबल को मापते हैं; देखें इंटर-एनोटेटर एग्रीमेंट।
आगे पढ़ने के लिए
- मल्टी-एजेंट टीम मूल्यांकन — हर सतह के लिए YAML के साथ पूरा स्कीमा संदर्भ
- मल्टी-एजेंट सिस्टम का मूल्यांकन कैसे करें — कब किस विधि का उपयोग करें, इसके लिए निर्णय मार्गदर्शिका
- Potato 2.6.2: एक संपूर्ण ओपन-सोर्स एजेंट-मूल्यांकन सूट — 2.6.x शृंखला में जो कुछ भी आया
- एजेंट ट्रैजेक्टरी का एनोटेशन — प्रति-चरण त्रुटि टैक्सोनॉमी, जिसमें चरण-स्तर पर MAST टैगिंग शामिल है