कंप्यूटर-उपयोग एजेंटों का मूल्यांकन, चरण दर चरण
Potato में कंप्यूटर-उपयोग और GUI एजेंटों के लिए ह्यूमन मूल्यांकन का एक वॉकथ्रू: प्रत्येक क्रिया को आँकना, स्क्रीनशॉट पर क्लिक ग्राउंडिंग की जाँच करना, और टूल कॉल की एक-एक करके समीक्षा करना।
एक कंप्यूटर-उपयोग एजेंट एक स्क्रीनशॉट पढ़ता है, एक क्रिया तय करता है, और क्लिक करता है। इसका मूल्यांकन करने का अर्थ है हर चरण की जाँच करना: क्या क्रिया सही थी, और क्या क्लिक वास्तव में उसी एलिमेंट पर पहुँचा जिसका उसने नाम लिया — न कि केवल यह कि कार्य अंततः सफल हुआ या नहीं। कार्य सफलता उस क्लिक को छुपा देती है जो गलत बटन पर लगा फिर भी आगे बढ़ गया, और उस क्रिया को जो संयोगवश सही थी। Potato इन रन की समीक्षा एक प्रयोजन-निर्मित GUI-ट्रैजेक्टरी सतह और एक टूल-कॉल समीक्षा से करता है, दोनों YAML में कॉन्फ़िगर किए गए।
एक कंप्यूटर-उपयोग एजेंट — जिसे GUI या OS एजेंट भी कहा जाता है — स्क्रीन को पिक्सेल या एक DOM के रूप में देखता है और उन्हीं नियंत्रणों के माध्यम से कार्य करता है जो एक व्यक्ति के पास होते हैं। OSWorld, ScreenSpot, और AndroidWorld जैसे बेंचमार्क कार्य पूर्णता को स्वचालित रूप से स्कोर करते हैं। स्वचालित स्कोरिंग सस्ती है और चलाने लायक है, लेकिन यह आपको नहीं बता सकती कि एक रन क्यों विफल हुआ, या संयोगवश हुई सफलता को पकड़ नहीं सकती। यही वह अंतर है जिसे ह्यूमन चरण समीक्षा भरती है।
 क्रिया को आँकें और क्या क्लिक उसी एलिमेंट पर पहुँचा जिसका उसने नाम लिया
क्रिया को आँकें और क्या क्लिक उसी एलिमेंट पर पहुँचा जिसका उसने नाम लिया
आप एक GUI ट्रैजेक्टरी में वास्तव में किसका मूल्यांकन करते हैं?
प्रत्येक चरण एक स्क्रीनशॉट (जो एजेंट ने देखा) को एक क्रिया (जो उसने किया) के साथ जोड़ता है। आप क्रिया को आँकते हैं, और जब चरण क्लिक निर्देशांक रखता है, तो आप उस ग्राउंडिंग मार्कर की जाँच करते हैं जो Potato स्क्रीनशॉट पर बनाता है:
- क्रिया की शुद्धता — सही, गलत एलिमेंट, गलत क्रिया, या हैल्युसिनेटेड।
- क्लिक ग्राउंडिंग — क्या निर्देशांक उसी एलिमेंट पर पहुँचे जिसका क्रिया ने नाम लिया?
- परिणाम — क्या रन ने कार्य पूरा किया, और किस चरण पर वह पहली बार गलत हुआ?
 प्रत्येक चरण की समीक्षा करें: क्रिया की शुद्धता और स्क्रीनशॉट पर क्लिक ग्राउंडिंग
प्रत्येक चरण की समीक्षा करें: क्रिया की शुद्धता और स्क्रीनशॉट पर क्लिक ग्राउंडिंग
annotation_schemes:
- annotation_type: gui_trajectory
name: gui_review
description: "For each step: was the action correct and did the click land right?"
steps_key: steps
screenshot_key: screenshot
action_key: action
coord_space: normalized
verdict_options: [correct, wrong_element, wrong_action, hallucinated]प्रत्येक चरण screenshot, action, और वैकल्पिक x/y (या एक नेस्टेड click: {x, y}) प्रदान करता है। ग्राउंडिंग मार्कर वह हिस्सा है जिसे स्वचालित मेट्रिक्स सबसे अधिक बार चूकते हैं: एक मॉडल लक्ष्य से दस पिक्सेल दूर क्लिक करते हुए भी सही क्रिया लेबल आउटपुट कर सकता है, और अंतिम स्क्रीन पर एक पास/फ़ेल इसे कभी सामने नहीं लाएगा।
अंतिम परिणाम की तुलना में पहला गलत चरण अधिक मायने क्यों रखता है?
क्योंकि वही चरण है जिसे आप ठीक करेंगे या जिसके विरुद्ध प्रशिक्षण देंगे। एक रन जो चरण 9 पर इसलिए विफल होता है क्योंकि चरण 3 ने एक डायलॉग को गलत पढ़ा, वास्तव में एक चरण-3 समस्या है, और इसे चरण 9 पर लेबल करना गलत सबक सिखाता है। पहले विचलन को पकड़ना वही विचार है जो प्रोसेस रिवॉर्ड मॉडल के पीछे है: हर चरण पर एक संकेत त्रुटि को स्थानीयकृत करता है, बजाय इसके कि पूरी ट्रैजेक्टरी को एक संख्या में समेट दे।
मैं किसी एजेंट के टूल कॉल की समीक्षा कैसे करूँ?
GUI एजेंट टूल और फ़ंक्शन भी कॉल करते हैं, और वे अपने ही तरीकों से विफल होते हैं: सही इरादा, गलत टूल; सही टूल, खराब आर्ग्युमेंट; सही कॉल, गलत क्रम। tool_call_review स्कीमा प्रत्येक कॉल को ट्रेस से बाहर निकालता है और उसे टूल नाम और सुंदर-छपे आर्ग्युमेंट के साथ एक कार्ड देता है, ताकि आप उन्हें एक-एक करके आँकें (BFCL v4 / MCPMark को प्रतिबिंबित करते हुए)।
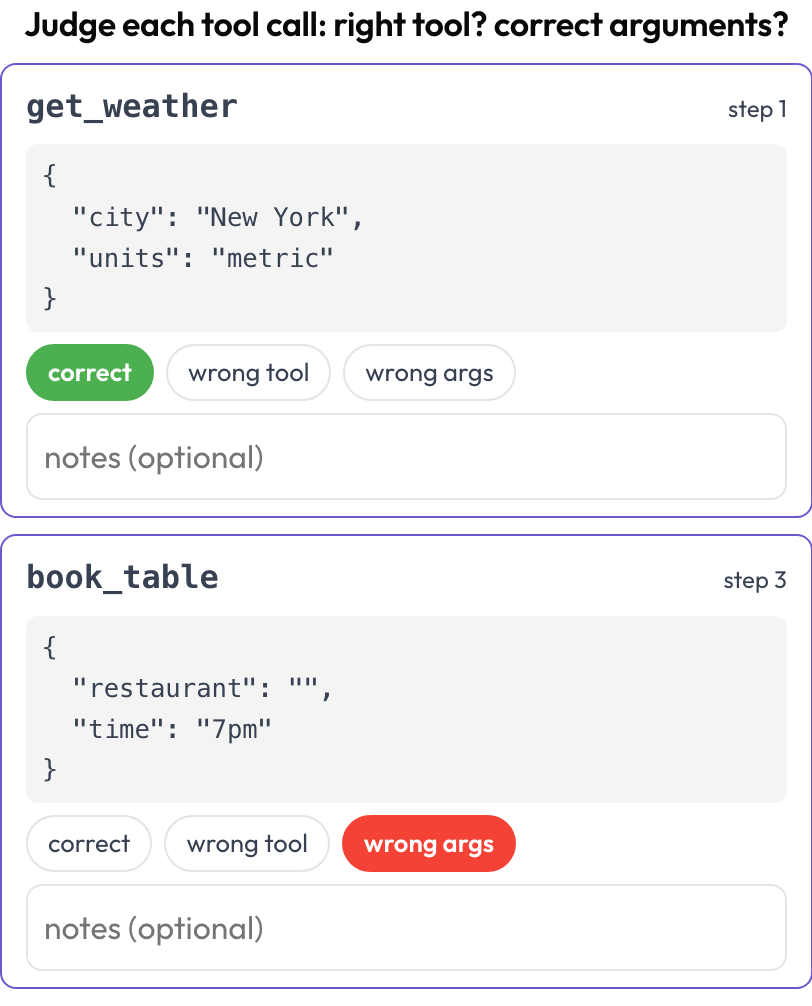 हर टूल कॉल को आँकें: सही टूल, सही आर्ग्युमेंट, सही क्रम
हर टूल कॉल को आँकें: सही टूल, सही आर्ग्युमेंट, सही क्रम
annotation_schemes:
- annotation_type: tool_call_review
name: tool_review
description: "Judge each tool call: right tool? correct arguments?"
steps_key: steps
# verdict_options: [correct, wrong_tool, wrong_args, wrong_order]टूल कॉल प्रत्येक चरण के tool_calls, tool_call, या action फ़ील्ड से रेंडर समय पर निकाले जाते हैं, इसलिए एक ट्रैजेक्टरी जो UI क्लिक और API कॉल को मिलाती है, उसकी एक ही कार्य में दोनों अक्षों पर समीक्षा की जा सकती है।
मैं इसे कैसे सेट करूँ?
प्रत्येक सतह examples/agent-traces/ के अंतर्गत एक चलाने योग्य उदाहरण के साथ आती है। स्कीमा को नमूना डेटा के साथ देखने के लिए Potato को किसी एक की ओर इंगित करें:
pip install --upgrade potato-annotation
python potato/flask_server.py start examples/agent-traces/gui-trajectory/config.yaml -p 8000आपका अपना डेटा चरणों की एक सूची के रूप में आता है, प्रत्येक में एक स्क्रीनशॉट URL या डेटा-URI और एक क्रिया स्ट्रिंग के साथ। उन व्यापक वेब एजेंटों के लिए जो कच्चे स्क्रीनशॉट के बजाय रेंडर किए गए पेज से काम करते हैं, देखें वेब-एजेंट मूल्यांकन।
आगे पढ़ने के लिए
- मल्टीमोडल-एजेंट मूल्यांकन — GUI, वॉइस, वीडियो, और डॉक्यूमेंट एजेंटों के लिए पूरा स्कीमा संदर्भ
- कंप्यूटर-उपयोग और मल्टीमोडल एजेंटों का मूल्यांकन — मार्गदर्शिका, एक स्कीमा-चयन तालिका के साथ
- वॉइस और वीडियो एजेंटों का मूल्यांकन — मल्टीमोडल सतहों का दूसरा भाग
- Potato 2.6.2: एक संपूर्ण ओपन-सोर्स एजेंट-मूल्यांकन सूट — पूरी 2.6.x शृंखला