intermediateaudio
Audio Transcription Review
Review and correct automatic speech recognition transcripts with waveform display.
Configuration Fileconfig.yaml
yaml
annotation_task_name: "Audio Transcription Review"
task_dir: "."
port: 8000
# Data configuration
data_files:
- data/transcripts.json
item_properties:
id_key: id
text_key: transcript
# Annotation schemes
annotation_schemes:
# Overall quality assessment
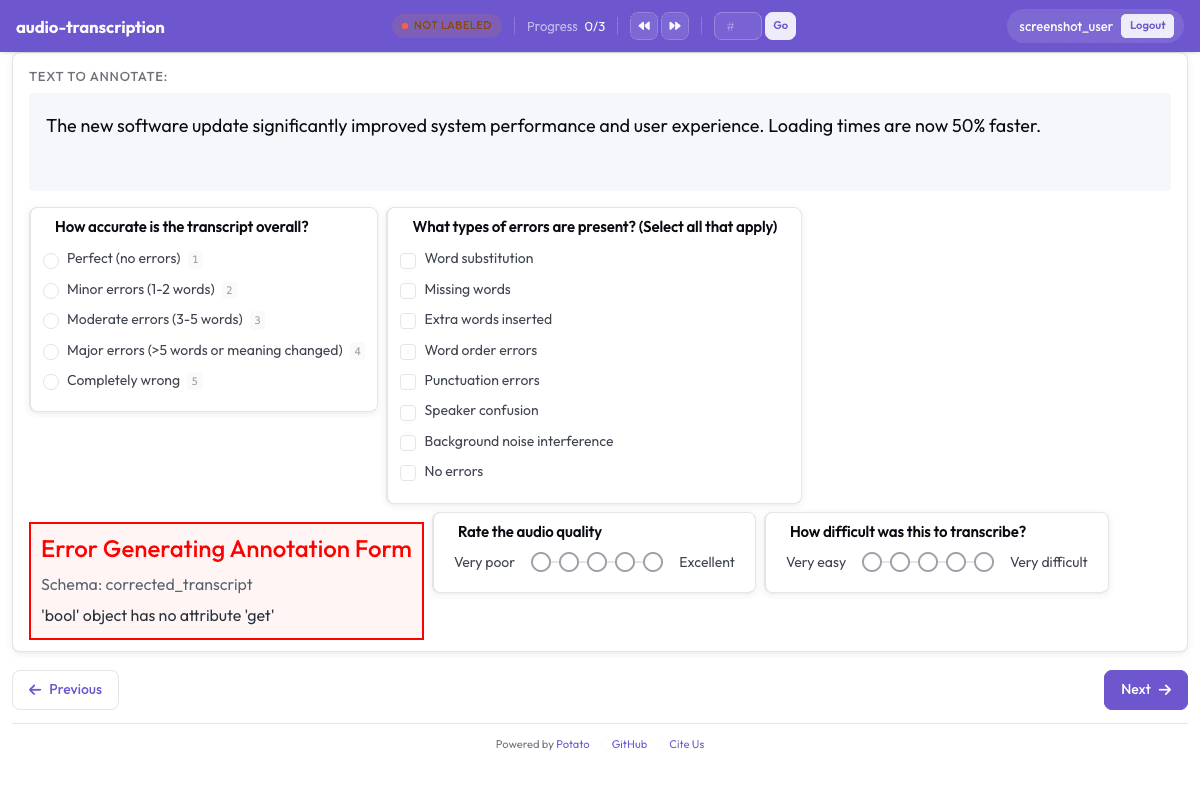
- annotation_type: radio
name: overall_accuracy
description: "How accurate is the transcript overall?"
labels:
- name: "Perfect (no errors)"
key_value: "1"
- name: "Minor errors (1-2 words)"
key_value: "2"
- name: "Moderate errors (3-5 words)"
key_value: "3"
- name: "Major errors (>5 words or meaning changed)"
key_value: "4"
- name: "Completely wrong"
key_value: "5"
sequential_key_binding: true
# Error types observed
- annotation_type: multiselect
name: error_types
description: "What types of errors are present? (Select all that apply)"
labels:
- Word substitution
- Missing words
- Extra words inserted
- Word order errors
- Punctuation errors
- Speaker confusion
- Background noise interference
- No errors
# Corrected transcript
- annotation_type: text
name: corrected_transcript
description: "Provide the corrected transcript (if needed)"
textarea: true
required: false
placeholder: "Type the corrected version here..."
# Audio quality rating
- annotation_type: likert
name: audio_quality
description: "Rate the audio quality"
size: 5
min_label: "Very poor"
max_label: "Excellent"
# Difficulty rating
- annotation_type: likert
name: difficulty
description: "How difficult was this to transcribe?"
size: 5
min_label: "Very easy"
max_label: "Very difficult"
# Additional notes
- annotation_type: text
name: notes
description: "Any additional notes? (Optional)"
textarea: true
required: false
# User settings
# Output
output_annotation_dir: "annotation_output/"
output_annotation_format: "json"
Get This Design
This design is available in our showcase. Copy the configuration below to get started.
Quick start:
# Create your project folder mkdir audio-transcription cd audio-transcription # Copy config.yaml from above potato start config.yaml
Details
Annotation Types
radiotextlikert
Domain
AudioSpeech
Use Cases
transcriptionASR evaluationspeech recognition
Tags
audiotranscriptionspeechasr
Related Designs
Speech Intelligibility Rating
Rate speech intelligibility for pathological speech following TORGO database annotation protocols.
likertradio
AgentBoard Progress Scoring
Assess multi-turn LLM agent progress by identifying achieved milestones, scoring overall progress, categorizing the agent environment, and noting partial progress observations.
multiselectlikert
Clotho Audio Captioning
Audio captioning and quality assessment based on the Clotho dataset (Drossos et al., ICASSP 2020). Annotators write natural language captions for audio clips, rate caption accuracy on a Likert scale, and classify the audio environment.
textlikert