AI 코딩 에이전트를 위한 GitHub PR 스타일 코드 리뷰
Potato에서 인라인 diff 코멘트, 파일 수준 품질 평가, 코딩 에이전트 출력에 대한 승인 또는 거부 판정을 갖춘 GitHub PR 스타일 코드 리뷰 어노테이션을 설정하세요.
코드 리뷰 어노테이션이 중요한 이유
대부분의 코딩 에이전트 벤치마크는 평가를 이진값으로 축소합니다. 테스트가 통과했는가 아닌가? SWE-bench는 해결된 이슈의 비율을 보고합니다. HumanEval은 pass@k를 보고합니다. 이러한 지표는 리더보드에는 유용하지만 코드 품질을 이해하는 데는 쓸모가 없습니다.
에이전트는 모든 테스트를 통과하고도 아무도 유지보수하고 싶지 않을 코드, 보안 구멍이 있는 코드, 느린 경로가 있는 코드, 또는 코드베이스의 나머지와 충돌하는 스타일의 코드를 작성할 수 있습니다. 사람 리뷰어라면 테스트가 초록색이더라도 그 PR에 변경을 요청할 것입니다. 사람들이 실제로 머지하는 코드를 작성하는 에이전트를 원한다면, 테스트만 실행할 것이 아니라 코드를 리뷰해야 합니다.
Potato의 code_review 어노테이션 스키마는 GitHub PR 리뷰 경험을 어노테이션 도구로 가져옵니다. 어노테이터는 구문 강조가 적용된 통합 diff를 보고, diff 줄을 클릭해 인라인 코멘트를 추가하고, 몇 가지 품질 차원에서 파일을 평가하고, 실제 풀 리퀘스트를 리뷰하듯이 승인, 변경 요청, 또는 코멘트 판정을 내립니다. 전체 스키마 레퍼런스는 코딩 에이전트 어노테이션 문서와 에이전트 평가 가이드를 참고하세요.
다음은 인라인 diff 코멘트와 파일 수준 평가를 보여주는 Potato의 코드 리뷰 인터페이스입니다:
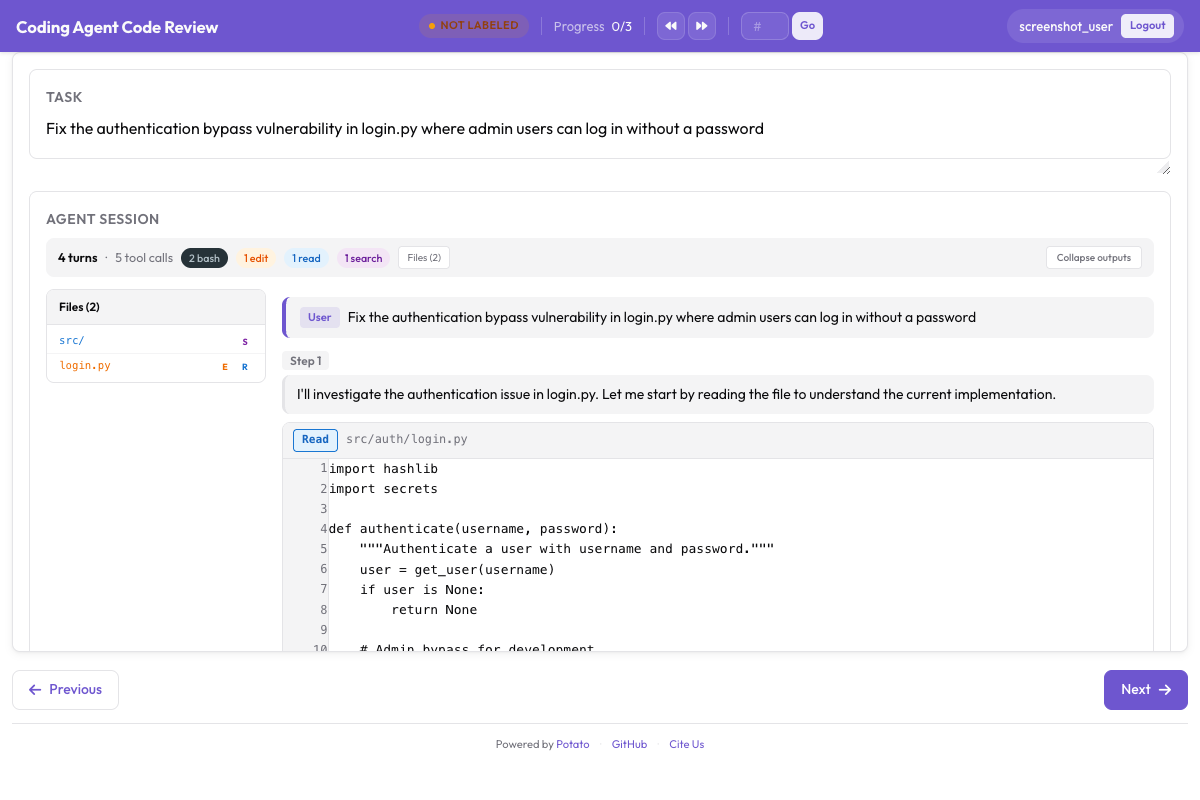 인라인 diff 코멘트와 파일 수준 품질 평가가 있는 Potato의 코드 리뷰 인터페이스
인라인 diff 코멘트와 파일 수준 품질 평가가 있는 Potato의 코드 리뷰 인터페이스
코드 리뷰 스키마 개요
code_review 스키마에는 세 개의 계층이 있습니다:
- 인라인 diff 코멘트: 어노테이터는 diff의 어떤 줄이든 클릭하여 범주화된 코멘트(bug, style, performance, security, logic, suggestion, question)를 첨부합니다
- 파일 수준 평가: 수정된 각 파일은 정확성(1-5)과 코드 품질(1-5)에 대한 독립적인 평가를 받습니다
- 전체 판정: 어노테이터는 최종 판정을 내립니다. 승인, 변경 요청, 또는 코멘트만
이는 실제 코드 리뷰를 그대로 반영하므로 개발자에게 자연스럽게 느껴지며, 거기서 생성되는 구조화된 출력은 코드 리뷰 모델 훈련에 곧장 매핑됩니다.
CodingTraceDisplay: Diff가 렌더링되는 방식
CodingTraceDisplay 컴포넌트는 코딩 에이전트 트레이스를 도구 호출과 그 출력의 시퀀스로 렌더링하며, 파일 편집을 특별히 처리합니다. 에이전트가 파일을 편집하면, 표시 화면은 다음을 포함한 통합 diff를 보여줍니다:
- 빨간 줄: 삭제된 줄(
-로 시작) - 초록 줄: 추가된 줄(
+로 시작) - 회색 줄: 컨텍스트 줄(변경되지 않음)
- 줄 번호: 거터에 옛 줄 번호와 새 줄 번호 모두 표시
- 구문 강조: 파일 확장자에 기반한 언어 인식 강조
- 클릭하여 코멘트: 어떤 줄이든 클릭하면 그 줄에 고정된 코멘트 폼이 열립니다
diff는 에이전트의 편집 작업에서 자동으로 계산됩니다. 에이전트가 검색-치환 도구를 사용했다면, Potato는 변경 전/후 상태를 재구성하여 통합 diff를 생성합니다.
단일 트레이스에서 여러 파일 편집을 생성하는 에이전트(실제 버그 수정에서 흔함)의 경우, 각 파일은 GitHub PR의 "Files changed" 탭과 유사하게 자체적인 접을 수 있는 diff 섹션을 갖습니다.
CodingTraceDisplay는 코드 변경을 적절한 구문 강조와 함께 렌더링합니다:
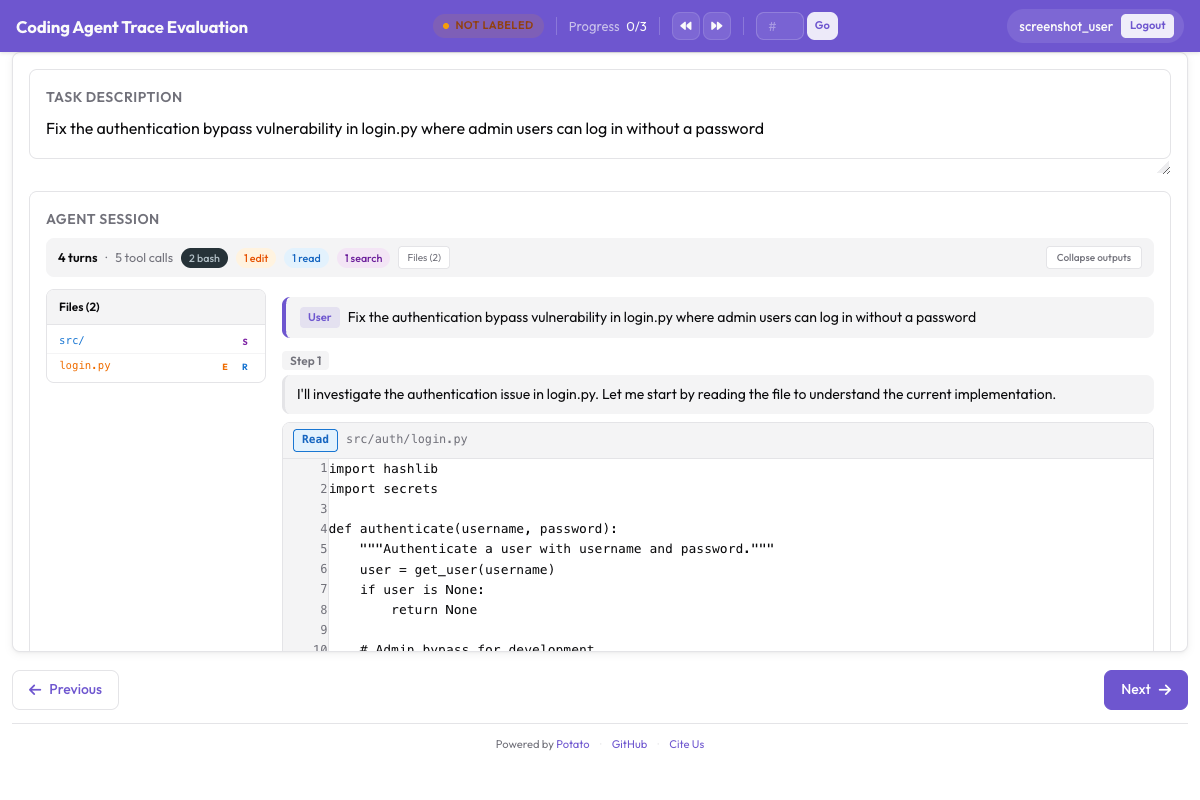 구문 강조와 파일 트리 사이드바와 함께 통합 diff를 렌더링하는 CodingTraceDisplay
구문 강조와 파일 트리 사이드바와 함께 통합 diff를 렌더링하는 CodingTraceDisplay
코멘트 범주
어노테이터가 diff 줄을 클릭하여 코멘트를 추가할 때, 범주를 선택합니다:
| 범주 | 색상 | 설명 | 예시 |
|---|---|---|---|
bug | 빨강 | 코드에 기능적 오류가 있음 | "user가 None이면 NullPointerException을 던집니다" |
style | 파랑 | 코드 스타일이나 컨벤션 문제 | "프로젝트는 함수에 camelCase가 아니라 snake_case를 사용합니다" |
performance | 주황 | 비효율적인 코드 | "이것은 루프 안에서 데이터베이스를 쿼리합니다. 배치 쿼리를 사용하세요" |
security | 보라 | 보안 취약점 | "사용자 입력이 정제 없이 SQL 쿼리에 직접 전달됩니다" |
logic | 노랑 | 즉각적인 실패를 일으키지 않을 수 있는 로직 문제 | "이 조건은 >가 아니라 >=여야 합니다. 경계에서 off-by-one입니다" |
suggestion | 초록 | 오류가 아닌 개선 제안 | "더 깔끔한 리소스 처리를 위해 여기서 컨텍스트 매니저를 사용하는 것을 고려해 보세요" |
question | 회색 | 설명이 필요함 | "이 import는 왜 추가되었나요? 사용되지 않는 것 같습니다" |
각 코멘트에는 어노테이터가 문제를 자세히 설명하는 자유 텍스트 본문도 있어, 실제 PR 코멘트를 작성하는 것과 똑같습니다.
파일 수준 평가
각 파일의 diff를 리뷰한 뒤, 어노테이터는 두 가지 차원에서 평가합니다:
정확성(1-5):
- 1: 작동하지 않음, 새로운 버그를 도입함
- 2: 부분적으로 작동함, 심각한 문제가 있음
- 3: 정상 경로에서는 작동하지만 엣지 케이스를 놓침
- 4: 사소한 문제와 함께 올바르게 작동함
- 5: 완전히 올바름, 엣지 케이스를 적절히 처리함
코드 품질(1-5):
- 1: 유지보수 불가, 구조 없음
- 2: 낮은 품질, 심각한 스타일/설계 문제
- 3: 수용 가능, 기본 컨벤션을 따름
- 4: 좋은 품질, 깔끔하고 읽기 쉬움
- 5: 훌륭함, 관용적이며 문서화가 잘 됨
판정 옵션
모든 파일을 리뷰한 뒤, 어노테이터는 세 가지 판정 중 하나를 선택합니다:
- 승인: 코드가 그대로, 또는 사소한 변경만으로 머지할 준비가 됨
- 변경 요청: 머지 전에 상당한 수정이 필요함
- 코멘트만: 머지 결정을 내리지 않고 피드백을 제공함
이는 GitHub의 세 가지 PR 리뷰 상태에 직접 매핑됩니다.
단계별 설정
1단계: 코딩 에이전트 트레이스 변환
코딩 에이전트 트레이스는 다양한 형식으로 제공됩니다. 다음은 인기 있는 세 에이전트의 예시입니다.
Claude Code에서 (JSON 내보내기):
python -m potato.convert_traces \
--input claude_code_sessions/ \
--output data/code_traces.jsonl \
--format claude_codeAider에서 (채팅 기록):
python -m potato.convert_traces \
--input aider_logs/ \
--output data/code_traces.jsonl \
--format aiderSWE-Agent에서 (트래젝터리 디렉터리):
python -m potato.convert_traces \
--input swe_agent_trajectories/ \
--output data/code_traces.jsonl \
--format swe_agent변환기는 표준화된 JSONL 형식을 생성합니다. 각 줄에는 작업, 에이전트의 단계, 파일 diff가 담긴 트레이스가 들어 있습니다:
{
"trace_id": "swe_bench_123",
"task": "Fix the TypeError in django/db/models/query.py when calling .values() on an empty QuerySet",
"repo": "django/django",
"base_commit": "a1b2c3d",
"steps": [
{
"type": "thought",
"content": "Let me look at the QuerySet.values() method to understand the TypeError."
},
{
"type": "action",
"tool": "search",
"input": "def values",
"file": "django/db/models/query.py"
},
{
"type": "observation",
"content": "Found at line 234: def values(self, *fields):\n ..."
},
{
"type": "action",
"tool": "edit",
"file": "django/db/models/query.py",
"old_content": " def values(self, *fields):\n clone = self._clone()\n clone.query.set_values(fields)",
"new_content": " def values(self, *fields):\n clone = self._clone()\n if not fields and not self.query.values_select:\n return clone\n clone.query.set_values(fields)"
},
{
"type": "action",
"tool": "edit",
"file": "tests/queries/test_values.py",
"old_content": "class ValuesTests(TestCase):",
"new_content": "class ValuesTests(TestCase):\n def test_empty_queryset_values(self):\n \"\"\"Calling .values() on empty QuerySet should not raise TypeError.\"\"\"\n qs = Author.objects.none()\n result = list(qs.values())\n self.assertEqual(result, [])"
}
],
"files_changed": [
{
"path": "django/db/models/query.py",
"diff": "--- a/django/db/models/query.py\n+++ b/django/db/models/query.py\n@@ -234,6 +234,8 @@\n def values(self, *fields):\n clone = self._clone()\n+ if not fields and not self.query.values_select:\n+ return clone\n clone.query.set_values(fields)"
},
{
"path": "tests/queries/test_values.py",
"diff": "--- a/tests/queries/test_values.py\n+++ b/tests/queries/test_values.py\n@@ -1,4 +1,10 @@\n class ValuesTests(TestCase):\n+ def test_empty_queryset_values(self):\n+ \"\"\"Calling .values() on empty QuerySet should not raise TypeError.\"\"\"\n+ qs = Author.objects.none()\n+ result = list(qs.values())\n+ self.assertEqual(result, [])"
}
]
}2단계: 코드 리뷰 스키마 구성
config.yaml을 만드세요:
annotation_task_name: "Coding Agent Code Review"
data_files:
- "data/code_traces.jsonl"
item_properties:
id_key: "trace_id"
text_key: "task"
# Display coding agent traces with diff rendering
display:
type: "coding_trace"
trace_key: "steps"
diff_key: "files_changed"
syntax_highlighting: true
show_line_numbers: true
collapse_large_diffs: true
max_uncollapsed_lines: 200
annotation_schemes:
- annotation_type: "code_review"
name: "review"
description: "Review the agent's code changes as you would a GitHub PR"
# Inline comment categories
comment_categories:
- name: "bug"
label: "Bug"
color: "#DC2626"
description: "Functional error in the code"
- name: "style"
label: "Style"
color: "#2563EB"
description: "Code style or convention issue"
- name: "performance"
label: "Performance"
color: "#EA580C"
description: "Inefficient code or unnecessary computation"
- name: "security"
label: "Security"
color: "#9333EA"
description: "Security vulnerability or unsafe practice"
- name: "logic"
label: "Logic"
color: "#CA8A04"
description: "Logic issue that may not cause immediate failure"
- name: "suggestion"
label: "Suggestion"
color: "#16A34A"
description: "Improvement idea, not an error"
- name: "question"
label: "Question"
color: "#6B7280"
description: "Clarification needed"
# File-level ratings
file_ratings:
- name: "correctness"
label: "Correctness"
scale: 5
descriptions:
1: "Does not work, introduces new bugs"
2: "Partially works, has significant issues"
3: "Works for happy path, misses edge cases"
4: "Works correctly with minor issues"
5: "Fully correct, handles edge cases"
- name: "code_quality"
label: "Code Quality"
scale: 5
descriptions:
1: "Unmaintainable, no structure"
2: "Poor quality, significant style issues"
3: "Acceptable, follows basic conventions"
4: "Good quality, clean and readable"
5: "Excellent, idiomatic, well-documented"
# Overall verdict
verdict:
options:
- name: "approve"
label: "Approve"
color: "#16A34A"
description: "Ready to merge as-is or with trivial changes"
- name: "request_changes"
label: "Request Changes"
color: "#DC2626"
description: "Needs significant revisions before merging"
- name: "comment"
label: "Comment Only"
color: "#6B7280"
description: "Providing feedback without a merge decision"
# Annotator settings
annotator_config:
allow_back_navigation: true
# Output settings
output:
path: "output/"
format: "jsonl"3단계: 어노테이션 서버 실행
potato start config.yaml -p 8000http://localhost:8000으로 이동하세요. 작업 설명, 에이전트의 추론 단계, 그리고 구문 강조와 함께 렌더링된 파일 diff가 담긴 첫 번째 코딩 에이전트 트레이스가 보입니다.
4단계: 어노테이터 워크플로
다음은 일반적인 리뷰 흐름입니다:
- 작업 읽기: 에이전트가 무엇을 하도록 요청받았는지 이해합니다(예: "Fix the TypeError in django/db/models/query.py")
- 트레이스 리뷰: 에이전트의 추론 단계를 스크롤하며 그 접근 방식을 이해합니다
- 각 파일 diff 리뷰:
- 구문 강조와 함께 diff를 읽습니다
- 어떤 줄이든 클릭하여 인라인 코멘트를 추가합니다
- 코멘트 범주(bug, style, performance 등)를 선택합니다
- 문제를 설명하는 코멘트 본문을 작성합니다
- 파일을 정확성(1-5)과 코드 품질(1-5)로 평가합니다
- 판정 내리기: 승인, 변경 요청, 또는 코멘트만 중에서 선택합니다
- 제출: "Submit"을 클릭하거나 Ctrl+Enter를 누릅니다
키보드 단축키가 워크플로 속도를 높여 줍니다:
| 단축키 | 동작 |
|---|---|
j / k | 파일 간 이동 |
c | 선택한 줄에 코멘트 열기 |
1-5 | 현재 차원에 대한 평가 설정 |
a | 판정을 승인으로 설정 |
r | 판정을 변경 요청으로 설정 |
Ctrl+Enter | 리뷰 제출 |
내보내기 형식
제출된 각 리뷰는 구조화된 JSON 객체를 생성합니다:
{
"trace_id": "swe_bench_123",
"annotator": "reviewer_01",
"timestamp": "2026-03-22T14:32:11Z",
"review": {
"inline_comments": [
{
"file": "django/db/models/query.py",
"line": 236,
"side": "right",
"category": "logic",
"body": "This early return skips set_values entirely, but if fields are provided later via .values('name'), the previous empty .values() call will have returned a clone that never went through set_values. Consider checking if this clone is still valid downstream."
},
{
"file": "tests/queries/test_values.py",
"line": 5,
"side": "right",
"category": "suggestion",
"body": "Consider adding a test case for .values() followed by .values('name') to verify the chaining behavior after your fix."
}
],
"file_ratings": [
{
"file": "django/db/models/query.py",
"correctness": 3,
"code_quality": 4
},
{
"file": "tests/queries/test_values.py",
"correctness": 4,
"code_quality": 4
}
],
"verdict": "request_changes"
}
}이 구조화된 형식은 코드 리뷰 모델 훈련과 집계 분석에 곧장 사용할 수 있습니다.
분석: 리뷰 데이터 다루기
리뷰 불러오기
import json
import pandas as pd
from pathlib import Path
reviews = []
for f in Path("output/").glob("*.jsonl"):
with open(f) as fh:
for line in fh:
reviews.append(json.loads(line))
print(f"Loaded {len(reviews)} code reviews")코멘트 범주 분포
from collections import Counter
all_comments = []
for rev in reviews:
for comment in rev["review"]["inline_comments"]:
all_comments.append(comment)
category_counts = Counter(c["category"] for c in all_comments)
print("Comment categories:")
for cat, count in category_counts.most_common():
print(f" {cat}: {count}")평균 파일 평가
ratings = []
for rev in reviews:
for fr in rev["review"]["file_ratings"]:
ratings.append(fr)
ratings_df = pd.DataFrame(ratings)
print("Average ratings by file:")
print(
ratings_df.groupby("file")[["correctness", "code_quality"]]
.mean()
.round(2)
.to_string()
)판정 분포
verdict_counts = Counter(rev["review"]["verdict"] for rev in reviews)
total = sum(verdict_counts.values())
print("Verdict distribution:")
for verdict, count in verdict_counts.most_common():
print(f" {verdict}: {count} ({count/total*100:.1f}%)")에이전트별 버그 비율
트레이스에 agent 필드가 포함되어 있다면, 에이전트 간 버그 비율을 비교할 수 있습니다:
agent_bugs = {}
for rev in reviews:
agent = rev.get("agent", "unknown")
bug_count = sum(
1 for c in rev["review"]["inline_comments"]
if c["category"] == "bug"
)
if agent not in agent_bugs:
agent_bugs[agent] = []
agent_bugs[agent].append(bug_count)
print("Average bugs per review by agent:")
for agent, bugs in sorted(agent_bugs.items()):
print(f" {agent}: {sum(bugs)/len(bugs):.2f} (n={len(bugs)})")활용 사례
코드 리뷰 모델 훈련
Potato의 코드 리뷰 어노테이션에서 나오는 구조화된 인라인 코멘트, 파일 평가, 판정은 자동화된 코드 리뷰 모델을 위한 이상적인 훈련 데이터입니다. 각 리뷰는 다음을 제공합니다:
- 특정 diff 줄에 묶인 위치 기반 피드백
- 범주화된 문제(bug 대 style 대 performance)
- 여러 세분화 수준의 품질 신호(줄, 파일, 전체)
이는 CodeRabbit이나 Graphite의 AI 리뷰어 같은 도구가 사용하는 데이터 형식이지만, LLM에서 증류한 것이 아니라 사람 전문가로부터 생성한 것입니다.
SWE-bench에서 코딩 에이전트 평가
SWE-bench는 에이전트가 이슈를 해결했는지(테스트 통과) 알려주지만, 코드가 머지 가능한지는 알려주지 않습니다. SWE-bench 솔루션에 코드 리뷰 어노테이션을 실행하면, 깔끔한 코드로 이슈를 해결하는 에이전트와 편법으로 이슈를 해결하는 에이전트를 식별할 수 있습니다. 이는 실제 개발자 경험과 상관관계가 있는, 더 섬세한 리더보드를 만들어 냅니다.
코드 품질 데이터셋 구축
여러 트레이스에 걸친 코드 리뷰 데이터를 집계하여 AI가 생성한 코드의 흔한 코드 품질 문제 데이터셋을 구축하세요. 이러한 데이터셋은 다음에 사용할 수 있습니다:
- 흔한 실수를 피하도록 코드 생성 모델을 파인튜닝
- AI 생성 코드 패턴에 특화된 린터 구축
- 사람 리뷰 전에 에이전트 출력의 유력한 문제를 표시하는 분류기 훈련
요약
Potato의 code_review 스키마는 GitHub PR 리뷰 워크플로를 에이전트 평가 안에 넣습니다. 여러분이 수집하는 인라인 코멘트, 파일 평가, 판정은 구조화된 코드 품질 데이터를 제공하며, 이는 통과/실패 테스트 결과가 알려주는 것보다 훨씬 많습니다. 코드 리뷰 모델을 훈련하든, 깔끔한 SWE-bench 솔루션을 편법투성이 솔루션과 구분하든, 아니면 그저 에이전트의 품질 기준선을 세우든, 그 데이터가 바로 여러분에게 필요한 것입니다.