Debugging Multi-Agent Failures: A Walkthrough
How to find why a multi-agent LLM system failed using Potato: the interaction graph, failure attribution, handoff review, per-agent scorecards, tool-contention timeline, and emergent-behavior tagging.
When a team of agents fails, the hard part is not noticing the failure — it is finding which agent caused it, at which step, and whether the real problem was a bad handoff between two agents that were each fine on their own. This walkthrough goes through the six Potato surfaces built for that, in the order you would actually use them on a broken run. Everything here is configured in YAML and runs on your own server; the full schema reference is Multi-Agent Team Evaluation.
A multi-agent system is several LLM agents with distinct roles — a planner, a coder, a reviewer — passing messages and handing off control. Research on why these systems break, the MAST taxonomy (Why Do Multi-Agent LLM Systems Fail?), found that most failures are inter-agent: a constraint dropped at a handoff, a team that never verifies its own work, agents talking past each other. A flat chat transcript hides exactly those, because the thing that went wrong lives in the space between two messages, not inside either one.
 The failure is between agents, at a handoff, not inside one transcript
The failure is between agents, at a handoff, not inside one transcript
How do I see the structure of a multi-agent run?
Start with the shape of the run, not the text. The agent_interaction_graph schema renders the whole run as a directed graph: nodes are agents, edges are the handoffs between them, thicker edges meaning more traffic. You click a node to mark it on the critical path and click an edge to cycle it from normal to critical to problematic.
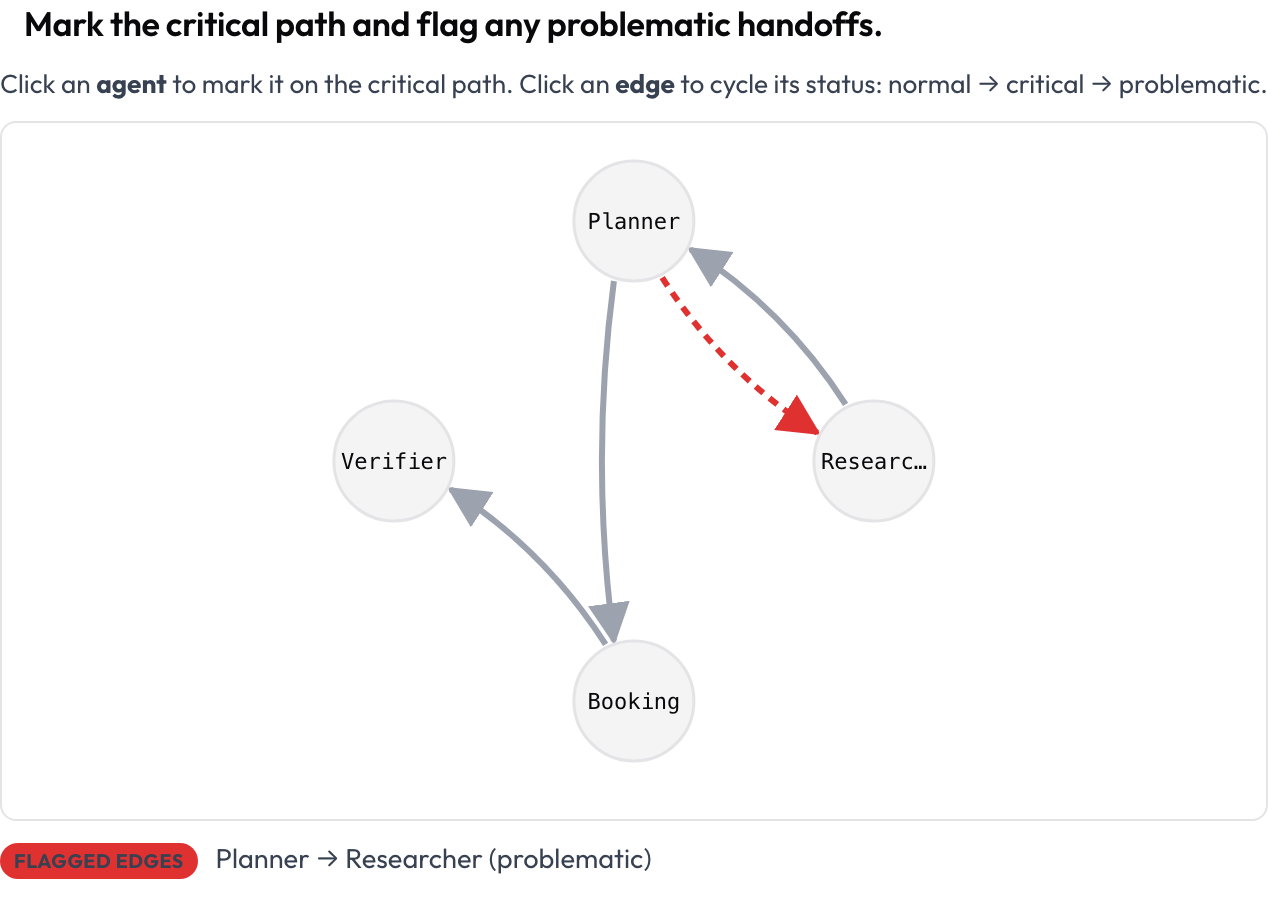 Mark the critical path and flag problematic handoffs
Mark the critical path and flag problematic handoffs
annotation_schemes:
- annotation_type: agent_interaction_graph
name: graph
description: "Mark the critical path and flag any problematic handoffs."
steps_key: steps
agent_key: agentThe graph is laid out automatically from the trace, so you do not draw anything. Every node and edge is keyboard-focusable and a text summary lists the critical nodes and flagged edges, so the meaning never rests on color alone. This view is the fastest way to answer "what talked to what, and where did the path go sideways."
How do I attribute a multi-agent failure to one agent?
Once you can see the run, pin the failure down. The failure_attribution schema asks for the triple from the failure-attribution literature (Zhang et al., Which Agent Causes Task Failures and When?, ICML 2025, the Who&When dataset): the responsible agent, the decisive step, and the reason. The agent dropdown and step picker are populated from the trace's own turns, so you can only attribute the failure to an agent and a step that actually happened.
 Attribute the failure to the responsible agent, the decisive step, and why
Attribute the failure to the responsible agent, the decisive step, and why
annotation_schemes:
- annotation_type: radio
name: outcome
description: "Did the system succeed?"
labels: [success, failure]
- annotation_type: failure_attribution
name: attribution
description: "If it failed: which agent, which step, and why?"
steps_key: steps
agent_key: agentPairing attribution with a success/failure radio means the triple is only collected on runs that failed, which keeps the annotator's time on the cases that carry signal.
What about the handoffs themselves?
Attribution names one decisive step. Handoff review looks at every control transfer. Wherever the acting agent changes between consecutive turns, Potato emits a handoff card A → B, and you flag what went wrong in the pass — information loss, a dropped constraint, garbling, goal drift — and rate the quality. The failure modes come from MAST's inter-agent category and the "echoing" phenomenon (Zhang et al., 2025).
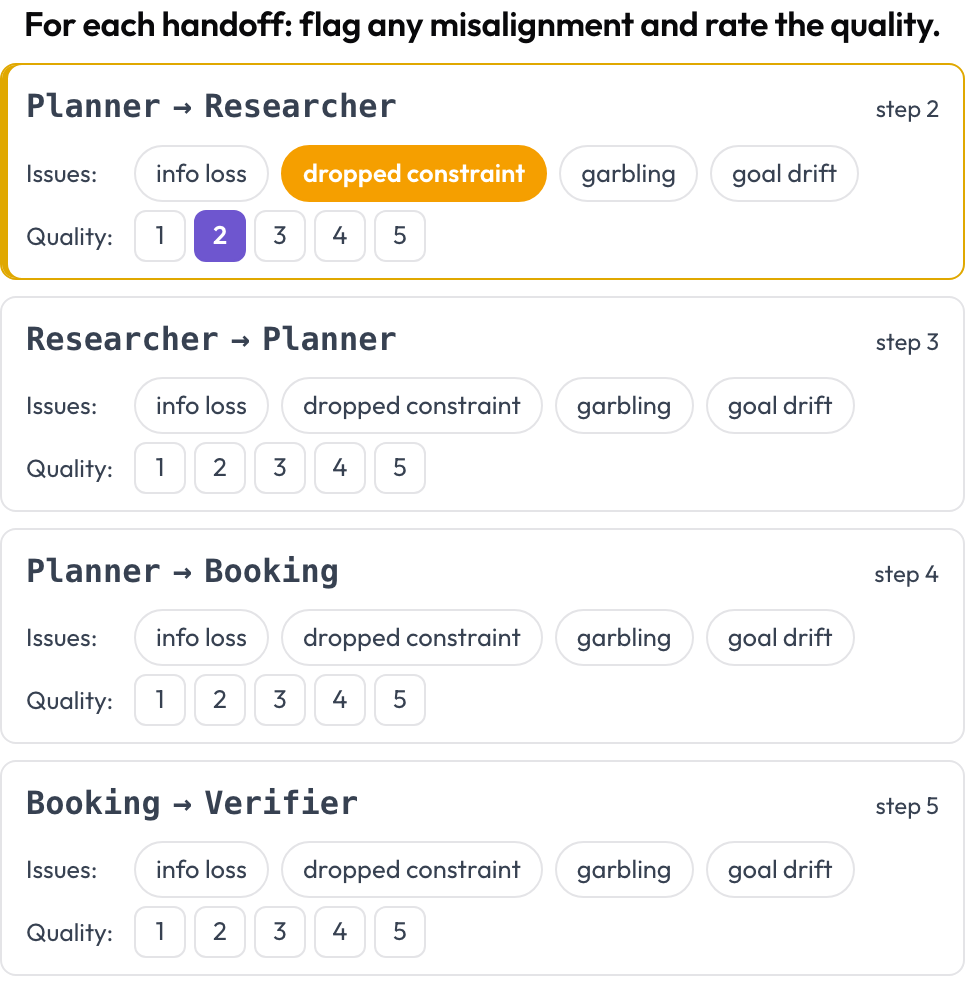 Flag inter-agent misalignment on every handoff and rate its quality
Flag inter-agent misalignment on every handoff and rate its quality
annotation_schemes:
- annotation_type: handoff_review
name: handoffs
description: "For each handoff: flag any misalignment and rate the quality."
steps_key: steps
agent_key: agent
flags: [info_loss, dropped_constraint, garbling, goal_drift]
quality_scale: 5Handoffs are derived at render time, so there is no manual setup. This is usually where the "each agent looked fine, the team still failed" cases resolve: the constraint was alive in agent A and gone by agent B.
How do I score the agents and the team?
A failure tells you what broke once. A scorecard tells you whether a design is good across many runs. The agent_scorecard schema scores two levels at once (MultiAgentBench, Zhou et al., ACL 2025): each agent on role fidelity, contribution, and coordination, and the team on its own shared dimensions, with optional milestones. Agent rows come from the trace, so the matrix matches who actually participated.
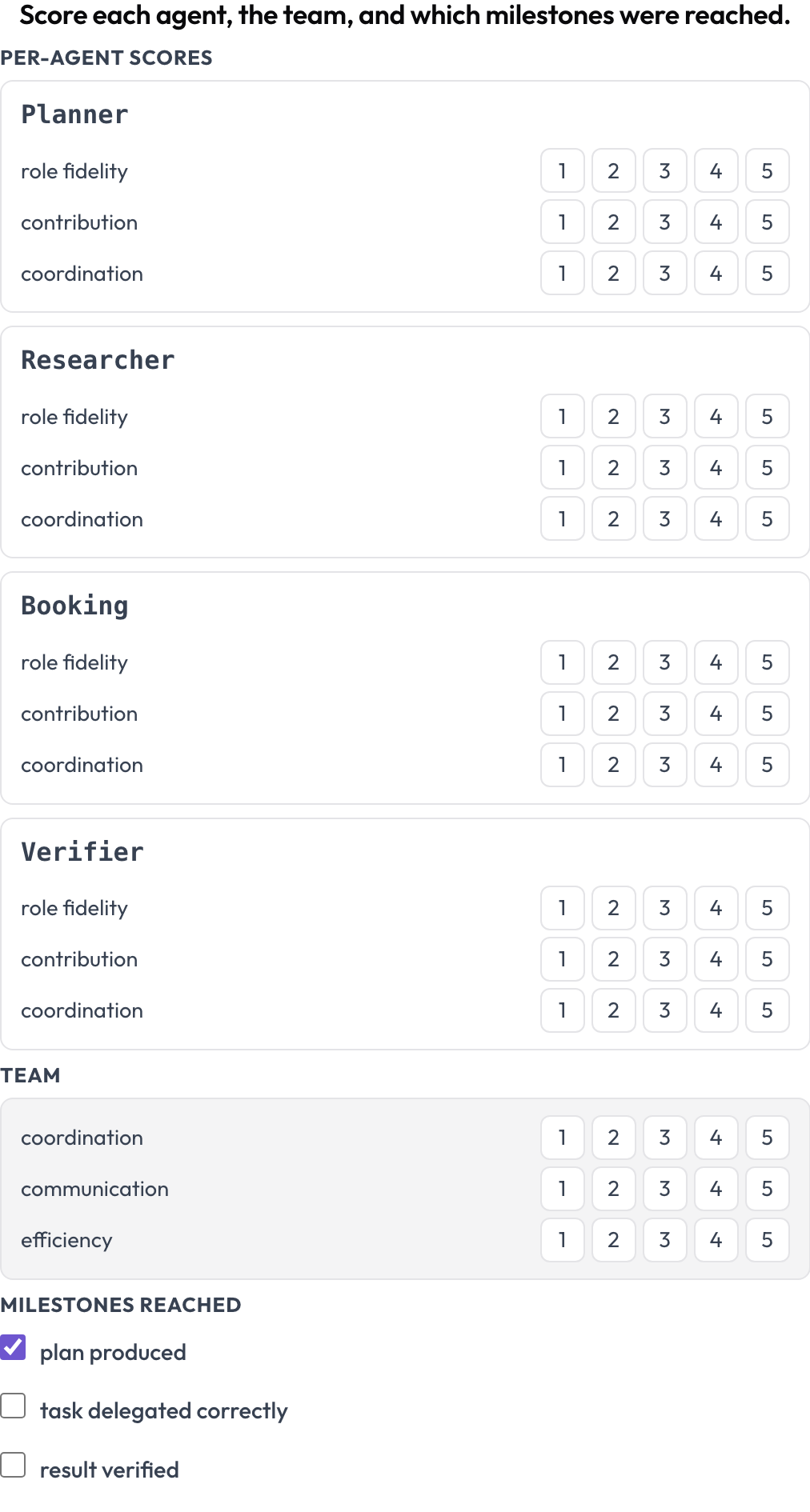 Score each agent on role fidelity, contribution, and coordination, plus the team
Score each agent on role fidelity, contribution, and coordination, plus the team
annotation_schemes:
- annotation_type: agent_scorecard
name: scorecard
description: "Score each agent, the team, and which milestones were reached."
steps_key: steps
agent_key: agent
scale: 5
agent_dimensions: [role fidelity, contribution, coordination]
team_dimensions: [coordination, communication, efficiency]
milestones: [plan produced, task delegated correctly, result verified]A strong agent stuck inside a poorly coordinated team shows up here as a high agent row next to low team dimensions, which is the pattern you want when you are comparing sequential against hierarchical against group-chat orchestration on the same tasks.
What about concurrency and collective failures?
Two more surfaces catch failures a turn-by-turn read cannot. The tool_contention timeline puts each agent on its own lane and highlights regions where two calls touch the same resource at overlapping times, which you classify as deadlock, circular wait, race condition, or benign (DPBench, 2026).
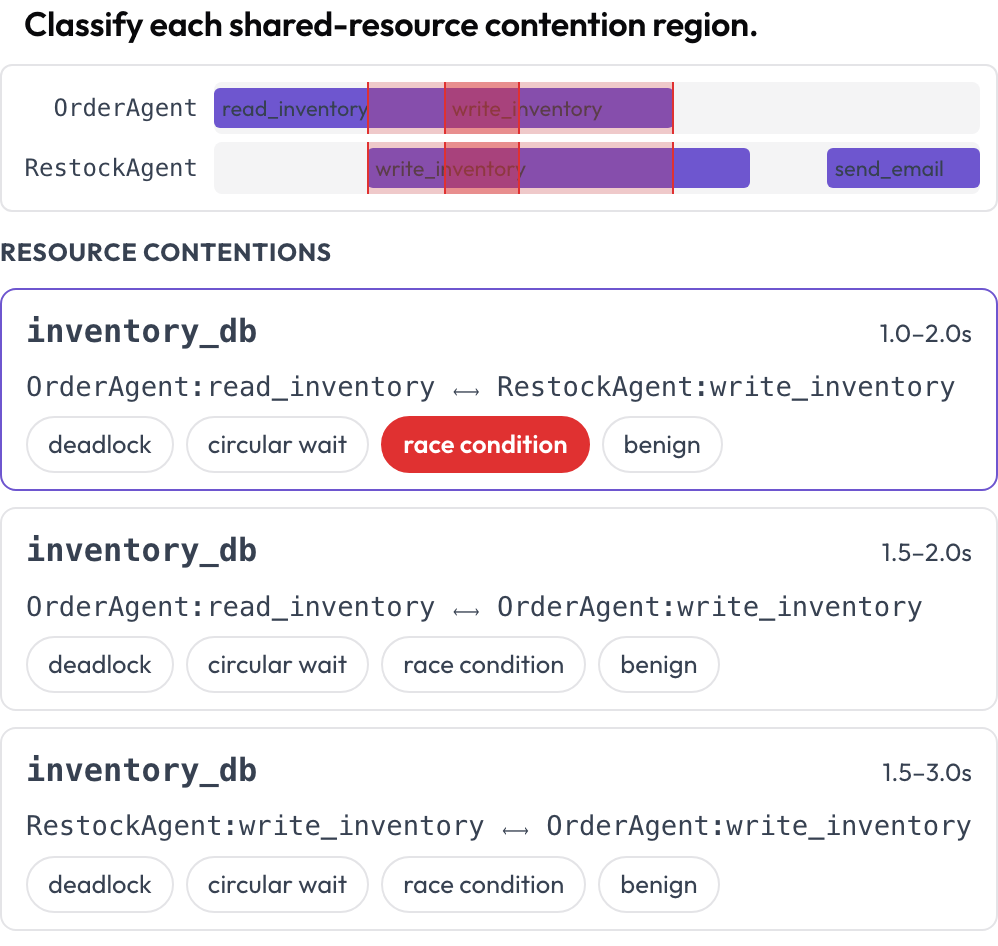 Spot deadlocks and race conditions on a per-agent tool-call timeline
Spot deadlocks and race conditions on a per-agent tool-call timeline
And emergent_behavior handles failures that are collective rather than located at one step — collusion, groupthink, cascading errors, role drift. An emergent behavior is not a contiguous span; it is a set of participating turns, possibly from different agents, so you check the turns that take part and add a note.
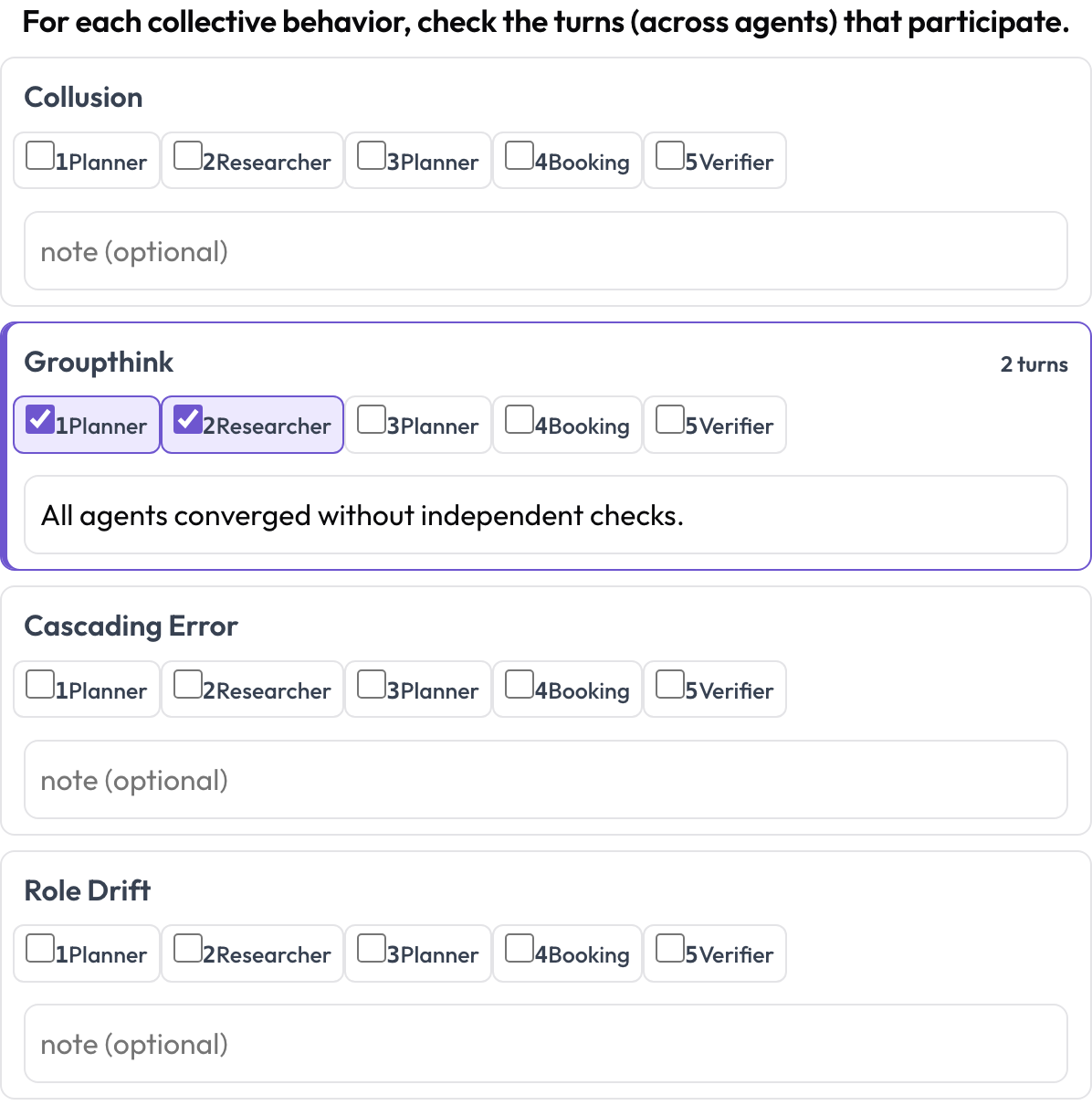 Tag collusion, groupthink, and cascading errors across agents and turns
Tag collusion, groupthink, and cascading errors across agents and turns
annotation_schemes:
- annotation_type: tool_contention
name: contention
description: "Classify each shared-resource contention region."
calls_key: calls
agent_key: agent
resource_key: resource
contention_labels: [deadlock, circular_wait, race_condition, benign]
- annotation_type: emergent_behavior
name: emergent
description: "For each collective behavior, check the turns that participate."
steps_key: steps
agent_key: agent
behaviors: [collusion, groupthink, cascading_error, role_drift]
allow_note: truePutting it in order
On a real broken run the sequence is usually: read the interaction graph to see the shape, use failure attribution to name the decisive step, open handoff review if the decisive step was a transfer, and reach for the contention timeline or emergent-behavior tagging when the failure is about timing or the group rather than one agent. Score with the scorecard once you are comparing designs rather than debugging one run. Measure agreement on attribution the way you would any subjective label; see Inter-Annotator Agreement.
Further reading
- Multi-Agent Team Evaluation — the full schema reference with YAML for each surface
- How to Evaluate Multi-Agent Systems — the decision guide for which method to use when
- Potato 2.6.2: A Complete Open-Source Agent-Evaluation Suite — everything that shipped across the 2.6.x line
- Annotating Agent Trajectories — per-step error taxonomies, including MAST tagging at step granularity