평가에서 학습 데이터로: SFT와 DPO를 위한 궤적 편집
대부분의 에이전트 평가는 점수에서 멈춘다. Potato 2.6의 trajectory_edit 스키마는 어노테이터가 잘못된 단계를 평가하는 대신 다시 작성하도록 하고, 각 수정을 지도 미세조정 타깃과 DPO 선호 쌍으로 내보낸다.
에이전트 평가는 보통 하나의 숫자로 끝난다. 어노테이터가 궤적을 읽고 세 번째 단계가 틀렸다고 판단한 뒤, 낮은 점수를 기록하거나 오류 유형을 태깅한다. 그 숫자는 에이전트가 얼마나 자주 실패하는지를 측정하는 데는 유용하다. 하지만 에이전트를 고치는 데는 훨씬 덜 유용하다. "세 번째 단계가 틀렸다"라는 말은 세 번째 단계가 어땠어야 하는지를 모델에게 알려주지 않기 때문이다.
곧 출시될 Potato 2.6은 점수가 아니라 답을 요구하는 스키마를 추가한다. trajectory_edit을 사용하면 어노테이터는 agent trace(에이전트 궤적)의 단계를 다시 작성한다. 즉 잘못된 추론 단계를 고치거나, 오타가 난 tool call(도구 호출)을 바로잡거나, 약한 최종 답변을 강화하며, Potato는 수정된 궤적을 원본 옆에 함께 보관한다. 그런 다음 trajectory_correction 익스포터가 각 (original, corrected) 쌍을 학습 데이터로 바꾼다. 즉 지도 미세조정 타깃과 직접 선호 최적화 선호 쌍이다.
이 글이 다루는 것은 바로 그 전환이다. 평가 도구를 학습 데이터 생산 도구로 바꾸고, 인간 어노테이터의 시간이 만들어내는 것을 바꾼다. 라벨이 아니라 학습 신호를 만들어내는 것이다.
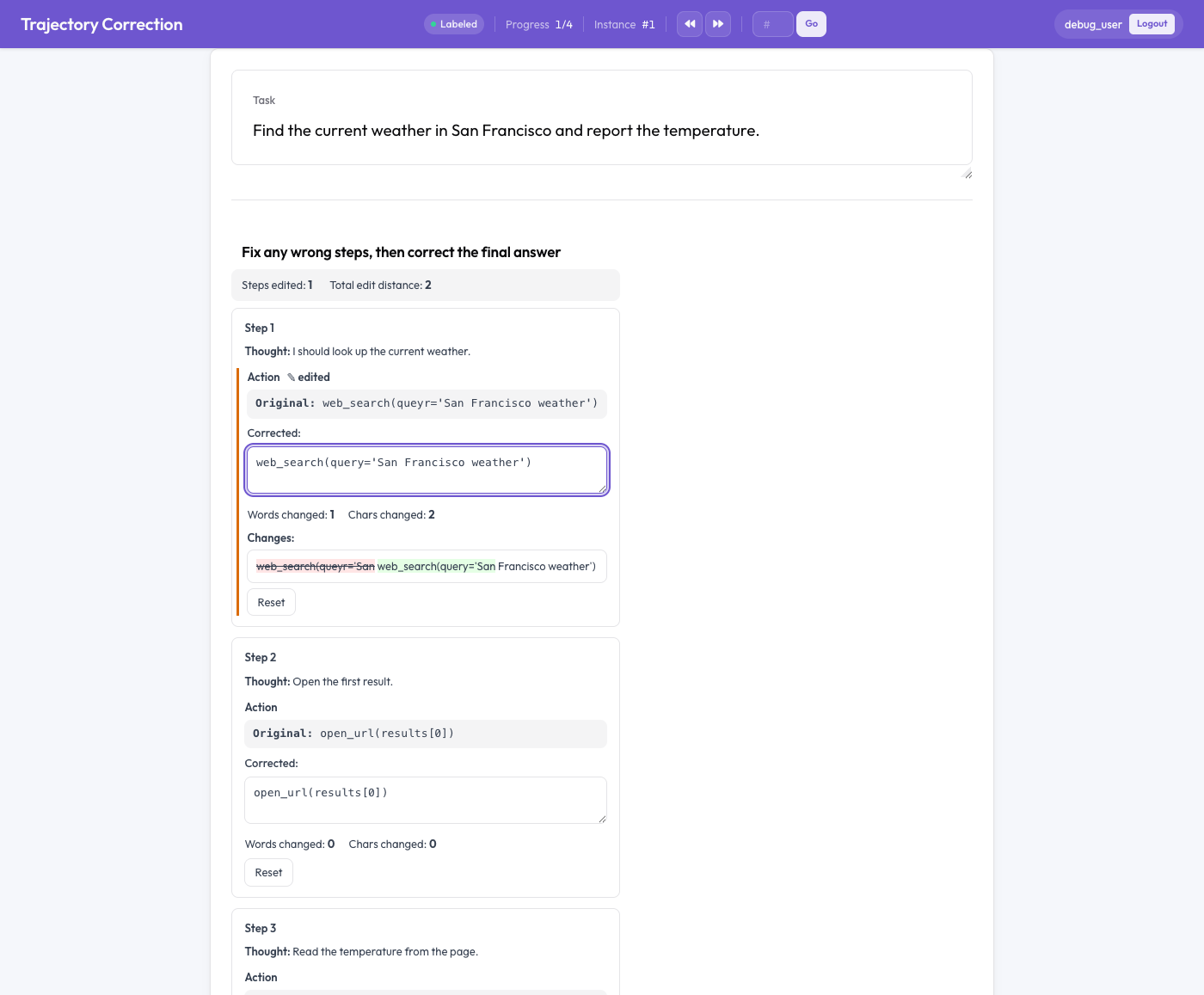 궤적 수정 편집기
궤적 수정 편집기
점수를 매기는 대신 편집하기
각 에이전트 단계는 두 부분으로 된 카드로 렌더링된다. 읽기 전용인 원본(original) 텍스트와, 원본이 미리 채워진 편집 가능한 수정(corrected) 상자다. 어노테이터는 수정 상자를 직접 편집한다. 입력하는 동안 세 가지 일이 일어난다.
- 실시간 단어 단위 diff가 삽입을 초록색으로, 삭제를 빨간색 취소선으로 강조하고,
- 변경된 단어 수와 문자 수가 집계되며,
- 변경된 필드에는 "edited"(편집됨) 플래그가 나타난다.
어노테이터가 마음을 바꾸면 "Reset" 버튼으로 해당 필드의 원본을 복원할 수 있다. 결정적으로, 그 어떤 것도 필수가 아니다. 트레이스를 읽고 올바르다고 판단한 어노테이터는 그냥 그대로 두면 되고, 편집되지 않은 트레이스는 학습 쌍을 만들지 않는다. 신호는 오직 실제 수정에서만 나온다.
구성
이 스키마는 데이터의 단계 목록을 가리키고, 어떤 필드가 편집 가능한지 지정한다.
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answer기본적으로는 각 단계의 action만 편집할 수 있다. 어노테이터가 에이전트의 행동뿐 아니라 추론까지 고치기를 원한다면 thought를 editable_fields에 추가하고, 각 변경에 서면 근거를 첨부하기를 원한다면 require_reason_on_edit: true로 설정한다. 이는 수정 자체를 검토하게 될 때 도움이 된다.
데이터 형식은 여러분의 트레이스가 이미 가지고 있는 그 모습 그대로다. 스키마는 steps_key로 지정된 필드에서 단계를 읽는다. 각 단계는 객체이며, 그 필드를 편집할 수 있다.
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}queyr의 오타는 어노테이터가 수정 상자에서 바로잡는 바로 그런 종류의 것으로, 모델이 학습할 수 있는 한 토큰짜리 수정을 만들어낸다.
저장소 루트에서 포함된 예제를 실행한다.
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000수정에서 학습 파일로
trajectory_correction 익스포터는 각각 다른 다운스트림 용도를 위한 세 개의 파일을 작성한다.
- **
trajectory_corrections.json**은 전체 레코드를 담는다.original_trace, 재구성된corrected_trace, 그리고 편집 거리와 사유가 포함된 필드별edits다. 이것이 여러분의 감사 추적이다. - **
trajectory_sft.jsonl**은 편집된 트레이스마다 한 줄씩,{"prompt": <task>, "completion": <corrected_trace>}을 가진다. 수정된 궤적은 모델이 미세조정을 통해 재현하도록 학습하는 타깃이 된다. - **
trajectory_dpo.jsonl**은 편집된 트레이스마다 한 줄씩,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}을 가진다. 인간의 편집이 선호를 정의한다. 즉 원본보다 수정본이 선호된다.
 편집이 어떻게 SFT와 DPO 학습 데이터가 되는가
편집이 어떻게 SFT와 DPO 학습 데이터가 되는가
DPO 파일은 공짜로 따라오는 부분이다. 일반적인 선호 데이터 파이프라인에서는 더 나은 응답과 짝지을 더 나쁜 응답을 생성하거나 수집해야 한다. 여기서는 더 나쁜 응답이 이미 존재하며(에이전트가 만들어낸 원본 궤적이 그것이다), 인간의 편집이 수정본이 선호된다는 증거가 된다. 하나의 어노테이션이 SFT 타깃과 DPO 쌍을 모두 만들어낸다.
무엇이 건너뛰어지며, 왜 그것이 중요한가
편집되지 않은 트레이스는 집계는 되지만 SFT와 DPO 파일에서는 제외된다. 변경되지 않은 궤적으로 학습하는 것은 모델에게 아무것도 가르치지 못하며, 더 나쁘게는 chosen == rejected 쌍으로 선호 데이터셋을 가득 채워 잡음을 더한다. 건너뛴 개수는 여전히 내보내기 통계에 나타나므로, 배치 중 얼마나 많은 부분이 이미 올바른 상태였는지를 볼 수 있다. 이는 그 자체로 에이전트 품질에 대한 유용한 신호다. 여러 어노테이터가 있는 경우, 특정 트레이스를 편집한 각 어노테이터가 하나의 SFT/DPO 레코드를 만들어내므로, 독립적인 수정이 모두 기여한다.
몇 가지 까다로운 지점
- diff는 단어 단위다. 공백이 없는 코드 같은 tool call(도구 호출)의 경우, 한 글자만 고쳐도 단일 토큰이 통째로 바뀐 것처럼 표시될 수 있다. 그런 경우에는 문자 거리 카운터가 정확한 신호다. 밀집된 도구 호출에서는 시각적 diff보다 그것을 신뢰하라.
- 편집은 점수 매기기와 자연스럽게 어울린다. 같은 트레이스에서 단계별 정확성 라벨이나 오류 분류 체계도 원한다면, 편집기와 나란히 단계 수준의 점수 매기기 스키마를 실행하라. 그러면 한 번의 패스로 진단과 수정을 모두 얻을 수 있다.
이것이 왜 중요한가
에이전트 튜닝 루프에는 언제나 "어떻게 했어야 하는가"라는 단계에서 병목이 있었다. 점수는 모델이 어디서 실패하는지 알려주지만, 학습할 수정된 행동을 만들어내지는 않는다. 그래서 팀들은 결국 합성 수정을 작성하거나 두 번째 라벨링 패스에 비용을 치르게 된다. 궤적 편집은 그것을 평가 자체로 접어 넣는다. 트레이스에 점수를 매겼을 바로 그 사람이 대신 그것을 고치고, 그 수리가 곧 학습 데이터다.
궤적 편집은 Potato 2.6에 포함된다. 전체 옵션 목록은 궤적 편집 문서를, 편집 전에 트레이스를 빠르게 읽으려면 eval_trace 표시를, 익스포터 세부 사항은 내보내기 형식 참조를 참고하라.