루프 닫기: 에이전트 오류와 평가자 불일치를 사람에게 되돌려보내기
에이전트 평가에서 사람의 검토 시간은 가장 희소한 자원입니다. Potato 2.6은 신호 기반 분류(triage) 큐와 평가자-사람 정렬을 결합해, 가장 나쁜 트레이스가 먼저 사람에게 도달하고 LLM 평가자가 계속 좋아지도록 합니다.
어느 정도 규모로 에이전트를 평가하기 시작하면, 제약은 더 이상 "이걸 레이블링할 수 있는가"가 아니라 "누구의 주의를, 무엇에 쓸 것인가"가 됩니다. 수천 건의 프로덕션 트레이스가 있는데 검토자는 한 줌뿐입니다. LLM 평가자가 모든 것을 사전 선별할 수 있지만 완벽하지 않으며, 평가자가 틀리는 사례야말로 사람의 시간을 들일 가치가 있는 사례입니다.
Potato 2.6의 두 기능이 함께 작동해 이 희소성을 관리합니다. 신호 기반 분류 큐는 사람이 무엇을 먼저 볼지 결정합니다. 평가자-사람 정렬은 평가자에게 얼마나 기댈 수 있는지를 측정하고 이를 개선합니다. 둘을 함께 실행하면 능동적 평가 루프가 생깁니다. 평가자가 쉬운 분량을 처리하고, 의심스러운 사례는 큐를 건너뛰어 사람에게 도달하며, 불일치는 더 나은 평가자로 되먹임됩니다.
이 글은 두 절반과 그것들이 어떻게 연결되는지를 다룹니다.
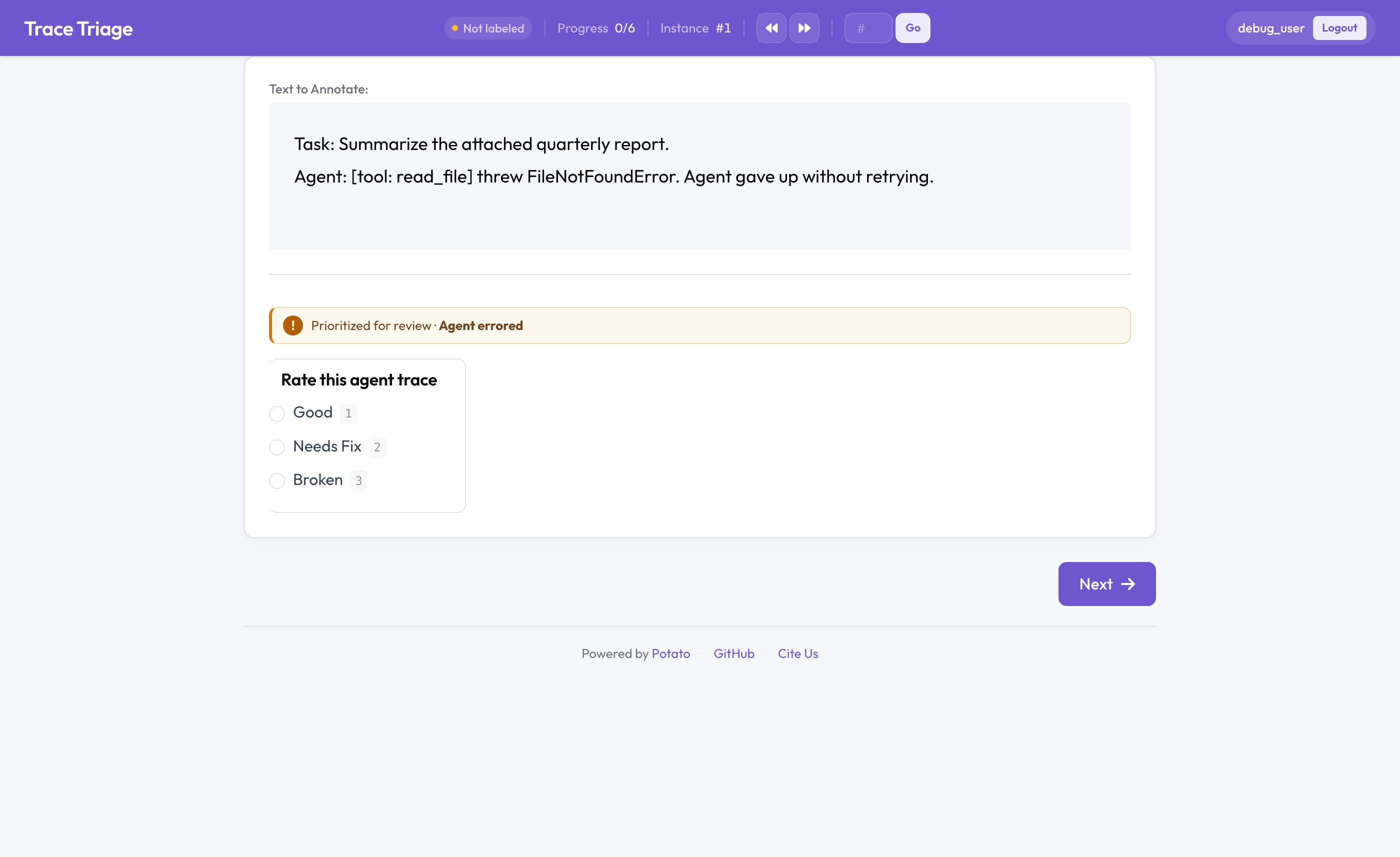 Potato의 분류 큐 배지
Potato의 분류 큐 배지
분류 절반: 선입선출이 아니라 최악부터 먼저
기본적으로 어노테이션 큐는 FIFO입니다. 항목은 로드된 순서대로 제공됩니다. 검토 시간이 희소할 때 이는 잘못된 순서입니다. 깨끗한 트레이스와 에이전트가 오류를 던진 트레이스는 사람의 주의를 들일 가치가 매우 다른데, FIFO는 둘을 똑같이 취급합니다.
분류 큐는 항목별 품질 신호로 큐를 재정렬합니다. 신호는 에이전트 오류, 프로덕션에서의 싫어요(thumbs-down), 낮은 자동 점수, 또는 데이터의 임의 필드일 수 있습니다.
triage:
enabled: true
order: desc # high priority first (default)
show_badge: true # banner during annotation explaining the priority
rules: # evaluated in order; highest matching priority wins
- name: "Agent errored"
priority: 100
when:
field: status
equals: error
- name: "Negative feedback"
priority: 80
when:
field: feedback
in: [thumbs_down, negative]
- name: "Low quality score"
priority: 60
when:
field: score
lt: 0.5
assignment_strategy: priority규칙은 위에서 아래로 평가되며 일치하는 것 중 가장 높은 우선순위가 이깁니다. 따라서 부정적 피드백도 함께 가진 오류 트레이스는 여전히 100에 안착합니다. rules를 완전히 생략하면 Potato는 합리적인 기본 세트(오류 상태 100, 부정적 피드백 80, 0.5 미만 점수 60)로 폴백하므로, 무언가를 조정하기 전에도 즉시 사용 가능한 동작이 합리적입니다.
조건 연산자는 실제로 필요한 비교를 모두 다룹니다.
| Operator | 의미 |
|---|---|
equals | 정확히 일치 (문자열은 대소문자 구분 없음) |
in | 값이 리스트 중 하나임 |
contains | 리스트가 포함하거나, 부분 문자열 일치 |
lt / lte / gt / gte | 수치 비교 |
exists | 필드가 존재하거나 부재함 |
신호가 이미 숫자인 경우, 규칙을 작성하는 대신 필드에서 곧바로 읽어올 수 있습니다.
triage:
enabled: true
signal_field: quality_score
invert_signal: true # lower score => higher priority실시간 트래픽에서도 작동합니다
우선순위 점수는 항목이 로드되거나 수집될 때 한 번 계산된 뒤 항목에 저장되므로, 할당은 계속 저렴하게 유지됩니다. 바로 그 설계 덕분에 런타임 수집도 그대로 작동합니다. 세션 도중 webhook 엔드포인트 또는 Langfuse 폴러를 통해 들어온 트레이스는 도착 시점에 점수가 매겨져 우선순위 순서에 자리 잡습니다. 오후 2시에 도착한 낮은 점수 또는 오류 트레이스는 오늘 아침부터 아직 기다리고 있는 깨끗한 트레이스들을 앞지릅니다. assignment_strategy: priority를 설정해야 큐가 실제로 그 순서대로 제공됩니다. show_badge는 독립적이므로, 다른 전략을 유지하더라도 "이것이 왜 표시되었는가" 배너가 나타납니다.
정렬 절반: 평가자를 얼마나 신뢰할 것인가
분류는 사람이 무엇을 볼지 결정합니다. 정렬은 나머지 중 얼마만큼을 감독 없이 평가자에게 맡길 수 있는지를 결정하고, 시간이 지나면서 평가자를 조여 줍니다.
Judge Alignment는 어노테이터가 이미 레이블링한 인스턴스에 대해 구성 가능한 LLM 평가자를 실행한 다음, 사람 골드 대비 Cohen's κ(코헨의 카파, 일치도 지표), 혼동 행렬, 불일치 목록을 보고합니다. 표준적인 관행(평가자를 약 100~200개의 골드 레이블에 정렬하고, 어디서 불일치하는지 점검하고, rubric을 다시 쓰고, 재실행하기)이 바로 이 기능이 중심에 두는 루프입니다.
ai_support:
enabled: true
endpoint_type: "ollama"
ai_config:
model: "llama3.2"
temperature: 0.0
judge_alignment:
enabled: true
schemas:
correctness:
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]평가자는 관리자 API에서 실행하며, 예측은 프롬프트 버전별로 캐시되므로 재실행 비용이 저렴합니다.
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'보정하고 싶을 때는 편집한 rubric을 전달하세요. 그러면 새 프롬프트 버전이 생성되므로, 라운드 간 κ를 비교하고 당신의 재작성이 실제로 도움이 되었는지 직접 확인할 수 있습니다.
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'이 보고서는 JSON으로, 또는 /admin/judge-alignment의 렌더링된 페이지로 제공되며, Landis–Koch 해석이 곁들여진 κ, 혼동 행렬, 평가자의 추론이 담긴 불일치 표, 그리고 프롬프트 버전 이력을 보여 줘서 보정 진행 상황이 라운드 간에 가시화됩니다.
인라인 모드는 그것을 어노테이터 앞에 둡니다
inline.enabled를 켜면, 각 어노테이션 페이지가 사람 레이블 옆에 평가자의 캐시된 판정(선택, 신뢰도, 펼칠 수 있는 추론)을 작업에 대한 실시간 κ와 함께 보여 줍니다. "수락"을 누르면 일치하는 선택지가 채워집니다. 사람이 저장할 때마다 사람↔평가자 비교가 기록되어 실시간 일치도에 반영되므로, 당신이 목표로 조율하는 κ는 사람들이 작업하는 동안 갱신됩니다.
둘을 합치기
이 기능들은 하나의 루프로 조합되도록 설계되었습니다.
 능동적 평가 루프: 분류, 사람 검토, 평가자 정렬, rubric 정제
능동적 평가 루프: 분류, 사람 검토, 평가자 정렬, rubric 정제
- 분류는 오류 및 낮은 신뢰도 트레이스를 사람 큐의 맨 앞으로 밀어 올립니다.
- 사람이 검토하여 이 고가치 항목들에 대해, 시스템이 가장 확신하지 못하는 바로 그곳에서 새로운 골드 레이블을 만들어 냅니다.
- 정렬은 그 골드 대비 평가자를 채점하고, 불일치 목록은 평가자와 사람이 어디서 갈라지는지를 정확히 보여 줍니다.
- 당신은 rubric을 정제하고, 재실행하고, κ가 움직이는 것을 지켜본 뒤, 더 잘 보정된 평가자가 쉬운 분량을 더 많이 흡수하게 하여 사람의 시간이 계속 어려운 사례로 흐르도록 합니다.
루프가 한 바퀴 돌 때마다 사람의 주의가 가장 가치 있는 곳에 쓰이고, 그것이 한 걸음 더 신뢰할 수 있는 평가자로 전환됩니다. 그것이 바로 핵심입니다. 에이전트 평가에서 사람을 빼는 것이 아니라, 사람의 조준을 맞추는 것입니다.
두 기능 모두 Potato 2.6에 포함됩니다. 전체 레퍼런스는 분류 큐 문서와 평가자 정렬 문서를, 우선순위가 매겨진 트레이스를 빠르게 읽으려면 eval_trace 디스플레이를 참고하세요.