Dalla valutazione ai dati di addestramento: l'editing delle traiettorie per SFT e DPO
La maggior parte delle valutazioni degli agenti si ferma a un punteggio. Lo schema trajectory_edit di Potato 2.6 permette agli annotatori di riscrivere un passo errato anziché valutarlo, ed esporta ogni correzione come target di fine-tuning supervisionato e coppie di preferenza per il DPO.
La valutazione di un agente di solito si chiude con un numero. Un annotatore legge una traiettoria, stabilisce che il terzo passo era sbagliato e registra un punteggio basso o assegna un tipo di errore. Quel numero è utile per misurare quanto spesso l'agente fallisce. È molto meno utile per correggerlo, perché "il terzo passo era sbagliato" non dice al modello quale avrebbe dovuto essere il terzo passo.
L'imminente versione Potato 2.6 aggiunge uno schema che chiede la risposta anziché il voto. Con trajectory_edit, gli annotatori riscrivono i passi di un agent trace (traccia dell'agente): correggono un passo di ragionamento andato male, riparano una tool call (chiamata a uno strumento) con un refuso o rafforzano una risposta finale debole, e Potato conserva la traiettoria corretta accanto all'originale. L'esportatore trajectory_correction trasforma poi ogni coppia (original, corrected) in dati di addestramento: target di fine-tuning supervisionato e coppie di preferenza per l'ottimizzazione diretta delle preferenze.
È di questo cambiamento che parla questo articolo. Trasforma uno strumento di valutazione in uno strumento di produzione di dati di addestramento e cambia ciò che il tempo di un annotatore umano produce: non un'etichetta, ma un segnale di apprendimento.
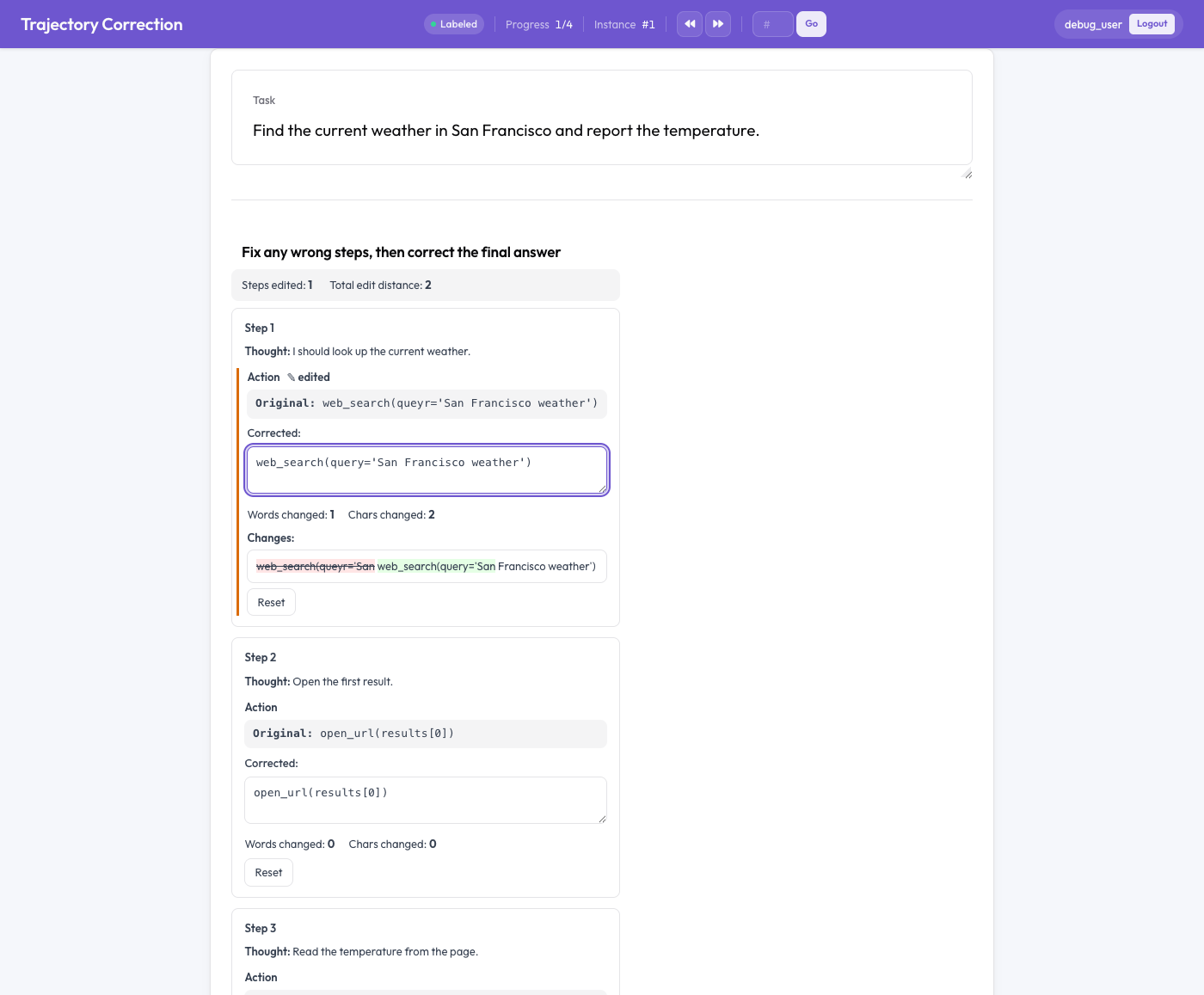 L'editor di correzione delle traiettorie
L'editor di correzione delle traiettorie
Modificare anziché valutare
Ogni passo dell'agente viene reso come una scheda in due metà: il testo originale, di sola lettura, e un riquadro corretto modificabile precompilato con l'originale. L'annotatore modifica direttamente il riquadro corretto. Mentre digita, accadono tre cose:
- un diff dal vivo a livello di parola evidenzia le inserzioni in verde e le cancellazioni in rosso barrato,
- vengono contati le parole e i caratteri modificati, e
- compare un contrassegno "edited" (modificato) su ogni campo che è cambiato.
Un pulsante "Reset" ripristina l'originale di un campo se l'annotatore cambia idea. Fondamentale: nulla è obbligatorio. Un annotatore che legge una traccia e la trova corretta semplicemente la lascia com'è, e una traccia non modificata non produce alcuna coppia di addestramento. Il segnale arriva solo da correzioni reali.
Configurazione
Lo schema punta all'elenco dei passi nei tuoi dati e indica quali campi sono modificabili:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerPer impostazione predefinita, solo l'action di ciascun passo è modificabile. Aggiungi thought a editable_fields quando vuoi che gli annotatori riparino il ragionamento dell'agente oltre alle sue azioni, e imposta require_reason_on_edit: true quando vuoi che a ogni modifica sia allegata una giustificazione scritta, cosa utile quando le correzioni stesse verranno revisionate.
Il formato dei dati è esattamente quello che le tue tracce hanno già. Lo schema legge i passi dal campo indicato da steps_key; ogni passo è un oggetto i cui campi possono essere modificati:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}Il refuso in queyr è esattamente il tipo di cosa che un annotatore corregge nel riquadro corretto, producendo una correzione di un solo token da cui il modello può imparare.
Esegui l'esempio incluso dalla radice del repository:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000Dalle correzioni ai file di addestramento
L'esportatore trajectory_correction scrive tre file, ciascuno per un diverso uso a valle:
trajectory_corrections.jsoncontiene il record completo: l'original_trace, ilcorrected_tracericostruito e glieditscampo per campo con distanze di modifica e motivazioni. È la tua pista di controllo.trajectory_sft.jsonlha una riga per traccia modificata,{"prompt": <task>, "completion": <corrected_trace>}. La traiettoria corretta diventa il target che un modello viene addestrato a riprodurre tramite fine-tuning.trajectory_dpo.jsonlha una riga per traccia modificata,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}. La modifica dell'umano definisce la preferenza: la corretta rispetto all'originale.
 Come le modifiche diventano dati di addestramento SFT e DPO
Come le modifiche diventano dati di addestramento SFT e DPO
Il file DPO è la parte che arriva gratis. In una normale pipeline di dati di preferenza occorre generare o raccogliere una risposta peggiore da accoppiare a quella migliore. Qui la risposta peggiore esiste già (è la traiettoria originale prodotta dall'agente) e la modifica dell'umano è la prova che la versione corretta è quella preferita. Una sola annotazione produce sia un target SFT sia una coppia DPO.
Cosa viene saltato, e perché conta
Le tracce non modificate vengono contate ma escluse dai file SFT e DPO. Addestrare su una traiettoria immutata non insegna nulla al modello e, peggio, inonderebbe un dataset di preferenza con coppie chosen == rejected che aggiungono rumore. Il conteggio delle saltate compare comunque nelle statistiche di esportazione, così puoi vedere quanta parte del lotto era già corretta, di per sé un segnale utile sulla qualità dell'agente. Con più annotatori, ogni annotatore che ha modificato una data traccia produce un record SFT/DPO, così tutte le correzioni indipendenti contribuiscono.
Un paio di spigoli vivi
- Il diff è a livello di parola. Per le tool call (chiamate a strumenti) simili a codice e prive di spazi, un singolo token può apparire come interamente cambiato anche per una correzione di un solo carattere. Il contatore della distanza in caratteri è il segnale preciso in questi casi; per le chiamate a strumenti dense fidati di esso più che del diff visivo.
- Modificare si abbina naturalmente al valutare. Se vuoi anche etichette di correttezza per passo o una tassonomia di errori sulla stessa traccia, esegui uno schema di valutazione a livello di passo accanto all'editor, così un solo passaggio produce sia la diagnosi sia la correzione.
Perché conta
Il ciclo di tuning degli agenti ha sempre avuto un collo di bottiglia al passo "cosa avrebbe dovuto fare". I punteggi ti dicono dove un modello fallisce; non producono il comportamento corretto su cui addestrarsi, così i team finiscono per scrivere correzioni sintetiche o pagare un secondo giro di etichettatura. L'editing delle traiettorie comprime tutto ciò nella valutazione stessa. La stessa persona che avrebbe valutato la traccia la ripara, e la riparazione è il dato di addestramento.
L'editing delle traiettorie arriva in Potato 2.6. Consulta la documentazione sull'editing delle traiettorie per l'elenco completo delle opzioni, la visualizzazione eval_trace per leggere rapidamente le tracce prima di modificarle, e il riferimento ai formati di esportazione per i dettagli dell'esportatore.