Von der Bewertung zu Trainingsdaten: Trajektorien-Editing für SFT und DPO
Die meisten Agentenbewertungen enden bei einer Punktzahl. Das trajectory_edit-Schema von Potato 2.6 lässt Annotatoren einen falschen Schritt umschreiben, statt ihn zu bewerten, und exportiert jede Korrektur als Ziele für überwachtes Fine-Tuning und als DPO-Präferenzpaare.
Die Agentenbewertung endet meist mit einer Zahl. Ein Annotator liest eine Trajektorie, entscheidet, dass Schritt drei falsch war, und vergibt eine niedrige Punktzahl oder markiert einen Fehlertyp. Diese Zahl ist nützlich, um zu messen, wie oft der Agent scheitert. Zum Beheben des Agenten taugt sie deutlich weniger, denn „Schritt drei war falsch" sagt dem Modell nicht, wie Schritt drei hätte aussehen sollen.
Das kommende Release Potato 2.6 ergänzt ein Schema, das nach der Antwort statt nach der Note fragt. Mit trajectory_edit schreiben Annotatoren die Schritte eines agent trace (einer Agenten-Trajektorie) um – sie korrigieren einen misslungenen Schlussfolgerungsschritt, reparieren einen vertippten tool call (Werkzeugaufruf) oder stärken eine schwache Endantwort –, und Potato bewahrt die korrigierte Trajektorie neben dem Original auf. Der trajectory_correction-Exporter verwandelt anschließend jedes (original, corrected)-Paar in Trainingsdaten: Ziele für überwachtes Fine-Tuning und Präferenzpaare für Direct Preference Optimization.
Um genau diese Verschiebung geht es in diesem Beitrag. Sie macht aus einem Bewertungswerkzeug ein Werkzeug zur Produktion von Trainingsdaten und verändert, was die Zeit eines menschlichen Annotators hervorbringt: kein Label, sondern ein Lernsignal.
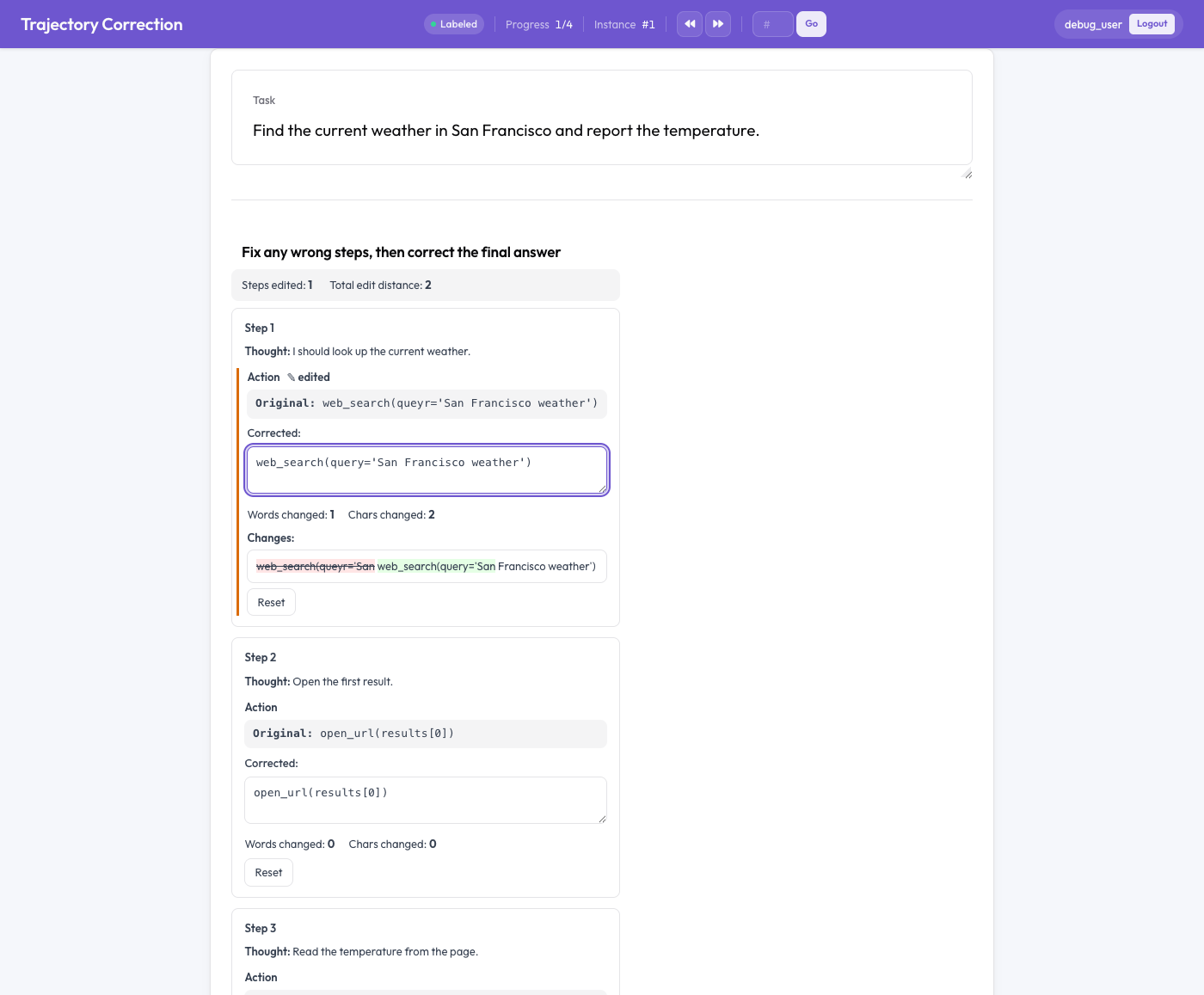 Der Editor zur Trajektorienkorrektur
Der Editor zur Trajektorienkorrektur
Editieren statt bewerten
Jeder Agentenschritt wird als Karte mit zwei Hälften dargestellt: der Original-Text, schreibgeschützt, und ein editierbares Korrektur-Feld, das mit dem Original vorbefüllt ist. Der Annotator bearbeitet das Korrekturfeld direkt. Während des Tippens geschehen drei Dinge:
- ein Live-Diff auf Wortebene hebt Einfügungen grün und Löschungen rot durchgestrichen hervor,
- die geänderten Wörter und Zeichen werden gezählt, und
- bei jedem geänderten Feld erscheint eine „edited"-Markierung (bearbeitet).
Eine „Reset"-Schaltfläche stellt das Original eines Feldes wieder her, falls der Annotator es sich anders überlegt. Entscheidend: Nichts ist erforderlich. Ein Annotator, der eine Trace liest und für korrekt befindet, lässt sie einfach unverändert, und eine unbearbeitete Trace erzeugt kein Trainingspaar. Das Signal entsteht nur aus echten Korrekturen.
Konfiguration
Das Schema verweist auf die Schrittliste in deinen Daten und benennt, welche Felder editierbar sind:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerStandardmäßig ist nur die action jedes Schritts editierbar. Füge thought zu editable_fields hinzu, wenn Annotatoren neben den Aktionen auch die Schlussfolgerungen des Agenten reparieren sollen, und setze require_reason_on_edit: true, wenn jeder Änderung eine schriftliche Begründung beiliegen soll – das hilft, wenn die Korrekturen selbst noch geprüft werden.
Das Datenformat ist genau das, in dem deine Traces ohnehin schon vorliegen. Das Schema liest die Schritte aus dem von steps_key benannten Feld; jeder Schritt ist ein Objekt, dessen Felder bearbeitet werden können:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}Der Tippfehler in queyr ist genau die Art von Sache, die ein Annotator im Korrekturfeld behebt und damit eine Ein-Token-Korrektur erzeugt, aus der das Modell lernen kann.
Führe das mitgelieferte Beispiel vom Wurzelverzeichnis des Repositorys aus aus:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000Von Korrekturen zu Trainingsdateien
Der trajectory_correction-Exporter schreibt drei Dateien, jede für eine andere nachgelagerte Verwendung:
trajectory_corrections.jsonenthält den vollständigen Datensatz: denoriginal_trace, den rekonstruiertencorrected_traceund die feldweiseneditsmit Editierdistanzen und Begründungen. Das ist dein Prüfpfad.trajectory_sft.jsonlhat eine Zeile pro bearbeiteter Trace,{"prompt": <task>, "completion": <corrected_trace>}. Die korrigierte Trajektorie wird zum Ziel, das ein Modell per Fine-Tuning reproduzieren soll.trajectory_dpo.jsonlhat eine Zeile pro bearbeiteter Trace,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}. Die Bearbeitung des Menschen definiert die Präferenz: korrigiert vor original.
 Wie aus Bearbeitungen SFT- und DPO-Trainingsdaten werden
Wie aus Bearbeitungen SFT- und DPO-Trainingsdaten werden
Die DPO-Datei ist der Teil, der gratis abfällt. In einer üblichen Pipeline für Präferenzdaten muss man eine schlechtere Antwort erzeugen oder einsammeln, um sie der besseren gegenüberzustellen. Hier existiert die schlechtere Antwort bereits (es ist die Original-Trajektorie, die der Agent erzeugt hat), und die Bearbeitung des Menschen ist der Beleg, dass die korrigierte Version bevorzugt wird. Eine einzige Annotation liefert sowohl ein SFT-Ziel als auch ein DPO-Paar.
Was übersprungen wird und warum das zählt
Unbearbeitete Traces werden gezählt, aber aus den SFT- und DPO-Dateien ausgeschlossen. Das Training auf einer unveränderten Trajektorie bringt dem Modell nichts bei und würde, schlimmer noch, einen Präferenzdatensatz mit chosen == rejected-Paaren überschwemmen, die Rauschen hinzufügen. Die Zahl der übersprungenen Traces erscheint dennoch in der Export-Statistik, sodass du sehen kannst, wie viel der Charge bereits korrekt war – an sich ein nützliches Signal zur Agentenqualität. Bei mehreren Annotatoren liefert jeder Annotator, der eine bestimmte Trace bearbeitet hat, einen SFT/DPO-Datensatz, sodass alle unabhängigen Korrekturen beitragen.
Ein paar scharfe Kanten
- Der Diff arbeitet auf Wortebene. Bei codeähnlichen tool calls (Werkzeugaufrufen) ohne Leerzeichen kann ein einzelnes Token selbst bei einer Ein-Zeichen-Korrektur als komplett verändert erscheinen. Der Zähler für die Zeichendistanz ist in diesen Fällen das präzise Signal; vertraue bei dichten Werkzeugaufrufen ihm mehr als dem visuellen Diff.
- Editieren passt natürlich mit Bewerten zusammen. Wenn du zusätzlich Korrektheits-Labels pro Schritt oder eine Fehlertaxonomie auf derselben Trace willst, lass ein schrittbasiertes Bewertungsschema neben dem Editor laufen, damit ein einziger Durchgang sowohl Diagnose als auch Korrektur liefert.
Warum das zählt
Die Agenten-Tuning-Schleife hatte schon immer einen Engpass beim Schritt „was hätte es tun sollen". Punktzahlen sagen dir, wo ein Modell scheitert; sie erzeugen nicht das korrigierte Verhalten, auf dem man trainieren kann, sodass Teams am Ende synthetische Korrekturen schreiben oder einen zweiten Labeling-Durchgang bezahlen. Trajektorien-Editing klappt das in die Bewertung selbst hinein. Derselbe Mensch, der die Trace bewertet hätte, repariert sie stattdessen, und die Reparatur ist das Trainingsdatum.
Trajektorien-Editing erscheint in Potato 2.6. Die vollständige Optionsliste findest du in der Dokumentation zum Trajektorien-Editing, die eval_trace-Darstellung zum schnellen Lesen von Traces vor dem Bearbeiten und die Referenz zu Exportformaten für die Details des Exporters.