Den Kreis schließen: Agentenfehler und Uneinigkeiten des Judges zurück an Menschen leiten
Menschliche Prüfzeit ist die knappste Ressource bei der Agenten-Evaluation. Potato 2.6 kombiniert eine signalbasierte Triage-Warteschlange mit Judge-Mensch-Abgleich, sodass die schlimmsten Traces zuerst zu Menschen gelangen und Ihr LLM-Judge immer besser wird.
Sobald Sie Agenten in irgendeinem Maßstab evaluieren, lautet die Einschränkung nicht mehr „Können wir das labeln?", sondern „Wessen Aufmerksamkeit setzen wir ein, und wofür?". Sie haben Tausende von Produktions-Traces und eine Handvoll Prüfer. Ein LLM-Judge kann alles vorab sieben, aber er ist nicht perfekt, und gerade die Fälle, in denen er falsch liegt, sind die Zeit eines Menschen wert.
Zwei Funktionen in Potato 2.6 wirken zusammen, um diese Knappheit zu bewältigen. Eine signalbasierte Triage-Warteschlange entscheidet, was Menschen zuerst sehen. Der Judge-Mensch-Abgleich misst, wie sehr Sie sich auf den Judge stützen können, und verbessert ihn. Führen Sie beide zusammen aus, erhalten Sie eine aktive Evaluationsschleife: Der Judge bewältigt das einfache Volumen, verdächtige Fälle überspringen die Warteschlange zu den Menschen, und die Uneinigkeiten fließen in einen besseren Judge zurück.
Dieser Beitrag behandelt beide Hälften und wie sie zusammenhängen.
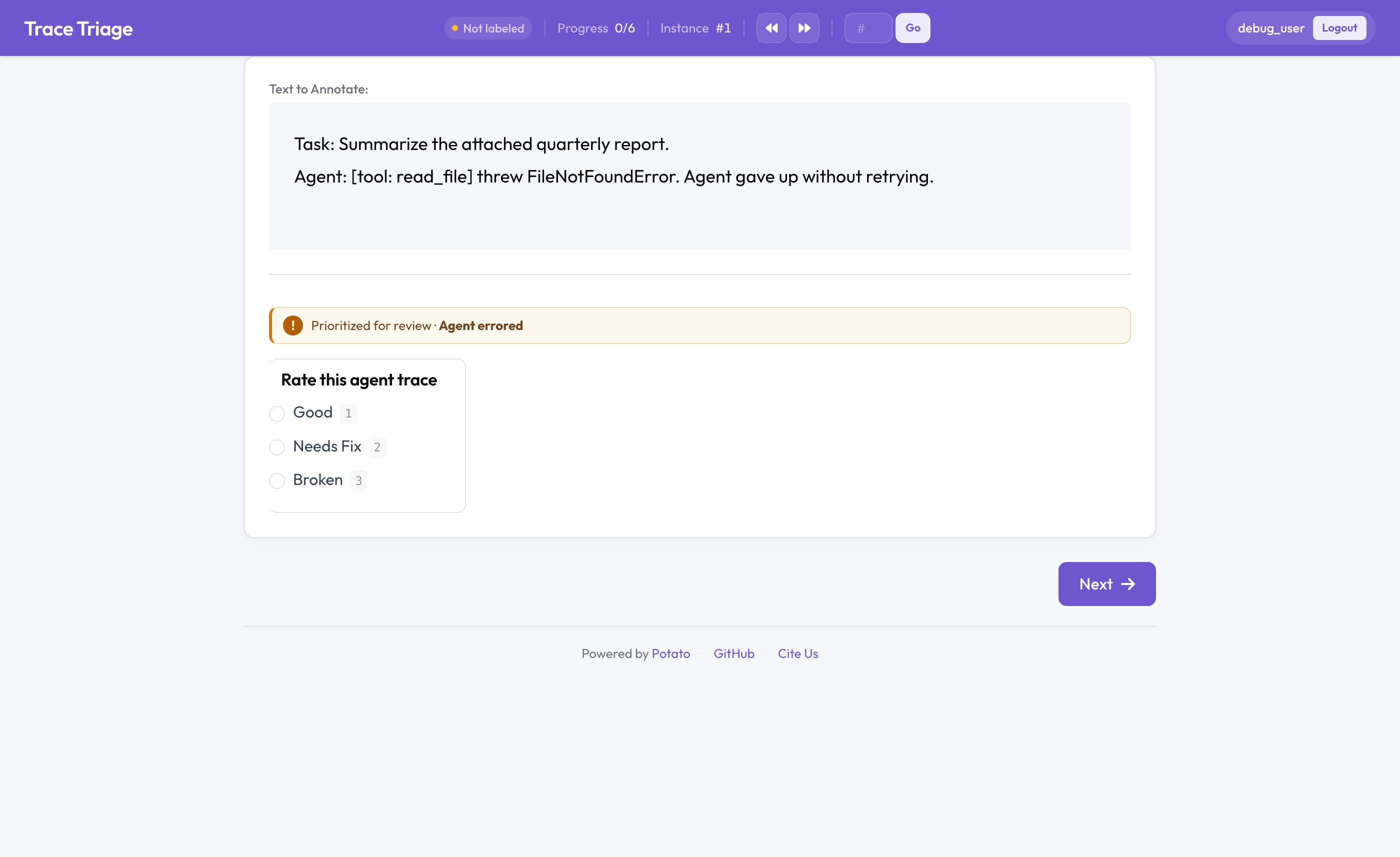 Das Triage-Warteschlangen-Badge in Potato
Das Triage-Warteschlangen-Badge in Potato
Die Triage-Hälfte: das Schlimmste zuerst, nicht First-In-First-Out
Standardmäßig ist eine Annotations-Warteschlange FIFO: Elemente werden in der Reihenfolge ausgeliefert, in der sie geladen wurden. Das ist die falsche Reihenfolge, wenn Prüfzeit knapp ist. Ein sauberer Trace und ein Trace, bei dem der Agent einen Fehler geworfen hat, sind sehr unterschiedliche Mengen menschlicher Aufmerksamkeit wert, und FIFO behandelt sie gleich.
Die Triage-Warteschlange ordnet die Warteschlange anhand eines Qualitätssignals pro Element neu. Das Signal kann ein Agentenfehler sein, ein Daumen-runter in der Produktion, eine niedrige automatische Bewertung oder ein beliebiges Feld in Ihren Daten:
triage:
enabled: true
order: desc # high priority first (default)
show_badge: true # banner during annotation explaining the priority
rules: # evaluated in order; highest matching priority wins
- name: "Agent errored"
priority: 100
when:
field: status
equals: error
- name: "Negative feedback"
priority: 80
when:
field: feedback
in: [thumbs_down, negative]
- name: "Low quality score"
priority: 60
when:
field: score
lt: 0.5
assignment_strategy: priorityRegeln werden von oben nach unten ausgewertet, und die höchste passende Priorität gewinnt, sodass ein fehlerhafter Trace, der auch negatives Feedback hat, dennoch bei 100 landet. Wenn Sie rules komplett weglassen, greift Potato auf eine sinnvolle Standardmenge zurück (Fehlerstatus bei 100, negatives Feedback bei 80, Bewertung unter 0.5 bei 60), sodass das schlüsselfertige Verhalten vernünftig ist, bevor Sie irgendetwas einstellen.
Die Bedingungsoperatoren decken die Vergleiche ab, die Sie tatsächlich brauchen:
| Operator | Bedeutung |
|---|---|
equals | exakte Übereinstimmung (Strings sind nicht case-sensitiv) |
in | Wert ist einer aus einer Liste |
contains | Liste enthält, oder Teilstring-Übereinstimmung |
lt / lte / gt / gte | numerischer Vergleich |
exists | Feld vorhanden oder nicht vorhanden |
Wenn das Signal bereits eine Zahl ist, können Sie es direkt aus dem Feld auslesen, anstatt Regeln zu schreiben:
triage:
enabled: true
signal_field: quality_score
invert_signal: true # lower score => higher priorityEs funktioniert auch bei Live-Traffic
Die Prioritätsbewertung wird einmal berechnet, wenn ein Element geladen oder aufgenommen wird, und dann auf dem Element gespeichert, sodass die Zuweisung günstig bleibt. Genau dieses Design sorgt dafür, dass die Aufnahme zur Laufzeit einfach funktioniert: Ein Trace, der mitten in der Sitzung über den Webhook-Endpunkt oder einen Langfuse-Poller eingespeist wird, wird bei der Ankunft bewertet und in die Prioritätsreihenfolge eingeordnet. Ein niedrig bewerteter oder fehlerhafter Trace, der um 14 Uhr eintrifft, springt vor die sauberen, die seit heute Morgen noch warten. assignment_strategy: priority zu setzen, ist das, was die Warteschlange tatsächlich in dieser Reihenfolge ausliefern lässt; show_badge ist unabhängig davon, sodass das „Warum wurde das markiert"-Banner selbst dann erscheint, wenn Sie eine andere Strategie beibehalten.
Die Abgleich-Hälfte: wie sehr dem Judge vertrauen
Die Triage entscheidet, was Menschen sehen. Der Abgleich entscheidet, wie viel vom Rest Sie dem Judge unbeaufsichtigt überlassen können, und er schärft den Judge im Lauf der Zeit.
Judge Alignment lässt einen konfigurierbaren LLM-Judge über Instanzen laufen, die Ihre Annotatoren bereits gelabelt haben, und meldet dann Cohens κ (Cohens Kappa, ein Maß für Übereinstimmung), eine Konfusionsmatrix und eine Liste von Uneinigkeiten gegenüber dem menschlichen Gold. Die gängige Praxis (einen Judge an etwa 100–200 Gold-Labels abgleichen, prüfen, wo er abweicht, die Rubric umschreiben und erneut ausführen) ist die Schleife, um die herum dies gebaut ist.
ai_support:
enabled: true
endpoint_type: "ollama"
ai_config:
model: "llama3.2"
temperature: 0.0
judge_alignment:
enabled: true
schemas:
correctness:
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]Sie führen den Judge über die Admin-API aus, und Vorhersagen werden pro Prompt-Version zwischengespeichert, sodass erneute Läufe günstig sind:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Wenn Sie kalibrieren möchten, übergeben Sie eine bearbeitete Rubric. Das erzeugt eine neue Prompt-Version, sodass Sie κ über Runden hinweg vergleichen und tatsächlich sehen können, ob Ihre Überarbeitung geholfen hat:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'Der Bericht, verfügbar als JSON oder als gerenderte Seite unter /admin/judge-alignment, zeigt κ mit einer Landis–Koch-Interpretation, die Konfusionsmatrix, eine Uneinigkeitstabelle mit der Begründung des Judges sowie eine Prompt-Versionshistorie, sodass der Kalibrierungsfortschritt über Runden hinweg sichtbar ist.
Der Inline-Modus stellt es dem Annotator direkt vor Augen
Mit inline.enabled zeigt jede Annotationsseite das zwischengespeicherte Urteil des Judges neben dem menschlichen Label (seine Wahl, Konfidenz und eine ausklappbare Begründung) zusammen mit einem laufenden κ für die Aufgabe. „Akzeptieren" füllt die passende Auswahl aus. Jedes menschliche Speichern erfasst einen Mensch↔Judge-Vergleich, der in die laufende Übereinstimmung einfließt, sodass sich das κ, auf das Sie hin abstimmen, aktualisiert, während die Leute arbeiten.
Beide zusammenführen
Die Funktionen sind so gestaltet, dass sie sich zu einer einzigen Schleife zusammenfügen:
 Die aktive Evaluationsschleife: Triage, menschliche Prüfung, Judge-Abgleich, Rubric-Verfeinerung
Die aktive Evaluationsschleife: Triage, menschliche Prüfung, Judge-Abgleich, Rubric-Verfeinerung
- Die Triage schiebt fehlerhafte und Traces mit geringer Konfidenz an den Anfang der menschlichen Warteschlange.
- Menschen prüfen diese hochwertigen Elemente und erzeugen frische Gold-Labels genau dort, wo das System am unsichersten ist.
- Der Abgleich bewertet den Judge gegen dieses Gold, und die Uneinigkeitsliste zeigt präzise, wo Judge und Menschen auseinandergehen.
- Sie verfeinern die Rubric, führen erneut aus und beobachten, wie sich κ bewegt; dann lassen Sie den besser kalibrierten Judge mehr vom einfachen Volumen aufnehmen, sodass menschliche Zeit weiterhin zu den schwierigen Fällen fließt.
Jede Runde der Schleife setzt menschliche Aufmerksamkeit dort ein, wo sie am meisten wert ist, und wandelt sie in einen Judge um, dem Sie ein Stück weiter vertrauen können. Genau darum geht es: nicht Menschen aus der Agenten-Evaluation zu entfernen, sondern sie auszurichten.
Beide Funktionen sind in Potato 2.6 enthalten. Die vollständige Referenz finden Sie in der Triage-Warteschlangen-Dokumentation und der Judge-Alignment-Dokumentation, und die eval_trace-Anzeige, um die priorisierten Traces schnell zu lesen.