From Evaluation to Training Data: Trajectory Editing for SFT and DPO
Most agent evaluation stops at a score. Potato 2.6's trajectory_edit schema lets annotators rewrite a wrong step instead of rating it, and exports each correction as supervised fine-tuning targets and DPO preference pairs.
Agent evaluation usually ends with a number. An annotator reads a trajectory, decides step three was wrong, and records a low score or tags an error type. That number is useful for measuring how often the agent fails. It is much less useful for fixing the agent, because "step three was wrong" does not tell the model what step three should have been.
The upcoming Potato 2.6 release adds a schema that asks for the answer instead of the grade. With trajectory_edit, annotators rewrite the steps of an agent trace (fixing a botched reasoning step, repairing a typo'd tool call, or strengthening a weak final answer), and Potato keeps the corrected trajectory next to the original. The trajectory_correction exporter then turns each (original, corrected) pair into training data: supervised fine-tuning targets and direct preference optimization preference pairs.
That is the shift this post is about. It turns an evaluation tool into a training-data production tool, and it changes what a human annotator's time produces: not a label, but a learning signal.
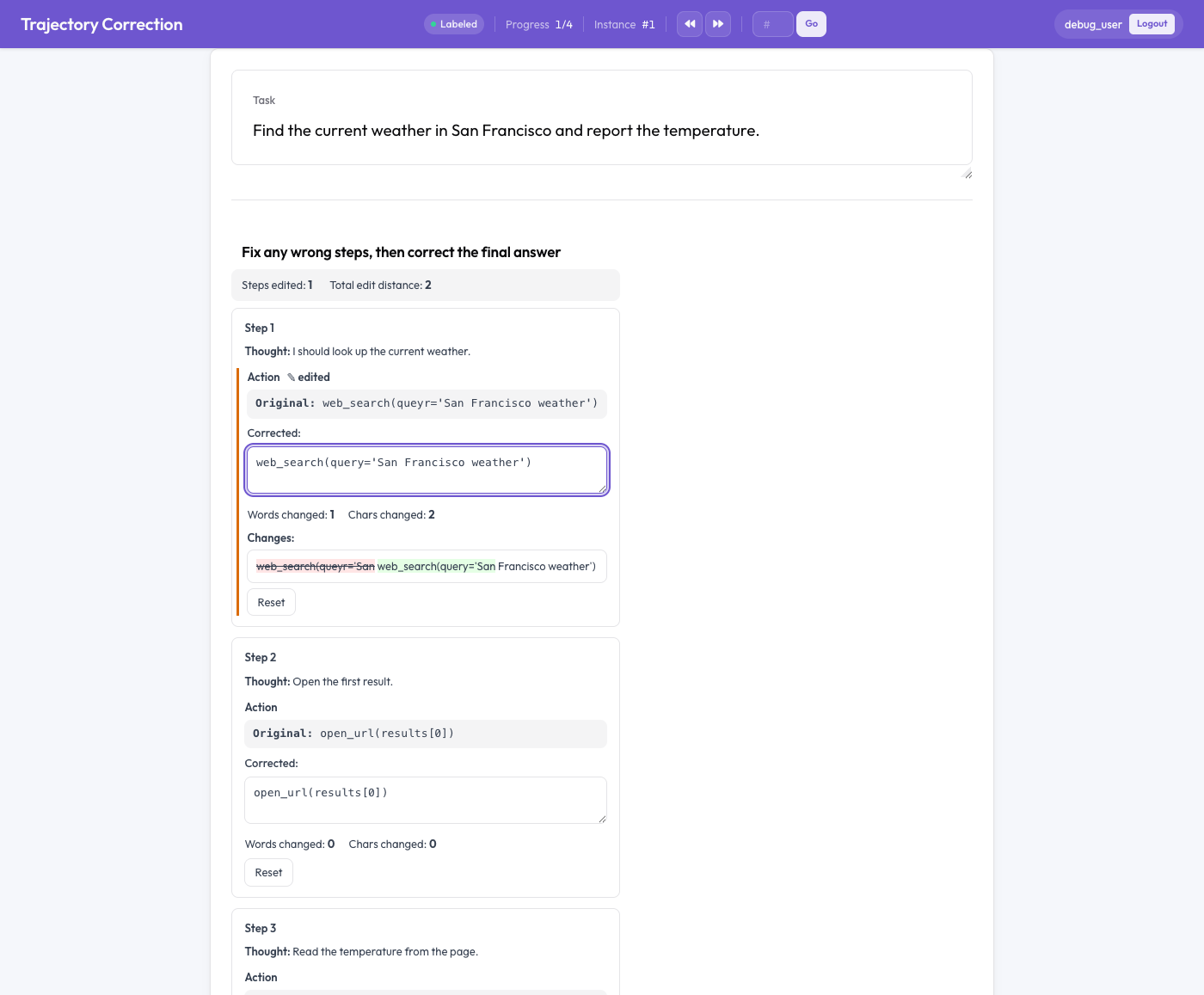 The trajectory correction editor
The trajectory correction editor
Editing instead of scoring
Each agent step renders as a card with two halves: the original text, read-only, and an editable corrected box pre-filled with the original. The annotator edits the corrected box directly. As they type, three things happen:
- a live word-level diff highlights insertions in green and deletions in red strikethrough,
- the words and characters changed are counted, and
- an "edited" flag appears on any field that changed.
A "Reset" button restores the original for a field if the annotator changes their mind. Crucially, nothing is required. An annotator who reads a trace and finds it correct simply leaves it alone, and an unedited trace produces no training pair. The signal comes only from real corrections.
Configuration
The schema points at the step list in your data and names which fields are editable:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerBy default only the action of each step is editable. Add thought to editable_fields when you want annotators to repair the agent's reasoning as well as its actions, and set require_reason_on_edit: true when you want a written justification attached to each change, which helps when the corrections themselves will be reviewed.
The data format is whatever your traces already look like. The schema reads steps from the field named by steps_key; each step is an object whose fields can be edited:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}The typo in queyr is exactly the kind of thing an annotator fixes in the corrected box, producing a one-token correction the model can learn from.
Run the bundled example from the repository root:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000From corrections to training files
The trajectory_correction exporter writes three files, each for a different downstream use:
trajectory_corrections.jsonholds the full record: theoriginal_trace, the reconstructedcorrected_trace, and per-fieldeditswith edit distances and reasons. This is your audit trail.trajectory_sft.jsonlhas one line per edited trace,{"prompt": <task>, "completion": <corrected_trace>}. The corrected trajectory becomes the target a model is fine-tuned to reproduce.trajectory_dpo.jsonlhas one line per edited trace,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}. The human's edit defines the preference: corrected over original.
 How edits become SFT and DPO training data
How edits become SFT and DPO training data
The DPO file is the part that comes for free. In a normal preference-data pipeline you have to generate or collect a worse response to pair against the better one. Here the worse response already exists (it is the original trajectory the agent produced) and the human edit is the proof that the corrected version is preferred. One annotation yields both an SFT target and a DPO pair.
What gets skipped, and why it matters
Unedited traces are counted but excluded from the SFT and DPO files. Training on an unchanged trajectory teaches the model nothing, and worse, it would flood a preference dataset with chosen == rejected pairs that add noise. The skipped count still appears in the export stats, so you can see how much of the batch was already correct, itself a useful signal about agent quality. With multiple annotators, each annotator who edited a given trace yields one SFT/DPO record, so independent corrections all contribute.
A couple of sharp edges
- The diff is word-level. For code-like tool calls with no spaces, a single token can show as wholly changed even for a one-character fix. The character-distance counter is the precise signal in those cases; trust it over the visual diff for dense tool calls.
- Editing pairs naturally with scoring. If you also want per-step correctness labels or an error taxonomy on the same trace, run a step-level scoring scheme alongside the editor, so one pass produces both the diagnosis and the fix.
Why this matters
The agent-tuning loop has always had a bottleneck at the "what should it have done" step. Scores tell you where a model fails; they do not produce the corrected behavior to train on, so teams end up writing synthetic corrections or paying for a second labeling pass. Trajectory editing collapses that into the evaluation itself. The same human who would have scored the trace instead repairs it, and the repair is the training data.
Trajectory editing ships in Potato 2.6. See the trajectory editing docs for the full option list, the eval_trace display for reading traces quickly before you edit, and the export formats reference for the exporter details.