Potato에 질적 코딩 도입하기: 코드북, 메모, 인비보 코드
Potato 2.6에 도입될 질적 데이터 분석 작업 공간인 QDA 모드를 살펴봅니다. 살아 있는 코드북, 인비보 코딩, 분석 메모, 케이스, 그리고 전체 코퍼스에 대한 전문 검색을 제공합니다.
인터뷰 전사본을 코딩해 본 적이 있다면 이 소프트웨어 이야기를 잘 알 것입니다. NVivo, ATLAS.ti, MAXQDA, Dedoose 같은 본격적인 질적 데이터 분석(QDA) 도구들은 강력하지만 비쌉니다. 데스크톱에서 돌아가고, 프로젝트를 독점 파일 형식에 가둬 두며, 협업을 라이선스 협상으로 바꿔 버립니다. 많은 연구자가 결국 스프레드시트로 코딩하다가 중간에 맥을 놓치고 마는데, 스프레드시트는 코드가 무엇인지 전혀 모르기 때문입니다.
Potato는 그 반대편에서, NLP와 머신러닝 데이터셋을 위한 텍스트 주석 도구로 출발했습니다. 지난 몇 번의 릴리스를 거치며 질적 워크플로에 필요한 부품들을 갖추게 되었습니다. 구절에 걸치는 스팬, 공유 코드북, 일치도 지표가 그것입니다. 곧 출시될 2.6 릴리스는 이들을 묶어, 질적 연구자가 실제로 일하는 방식에 맞춘 하나의 모드로 만들었습니다.
이 글에서는 QDA 모드를 살펴봅니다. 무엇이 켜지는지, 부품들이 어떻게 맞물리는지, 그리고 설정 파일이 어떻게 생겼는지 다룹니다. 레퍼런스가 필요하다면 QDA 모드 문서에 전체 옵션 목록이 있습니다.
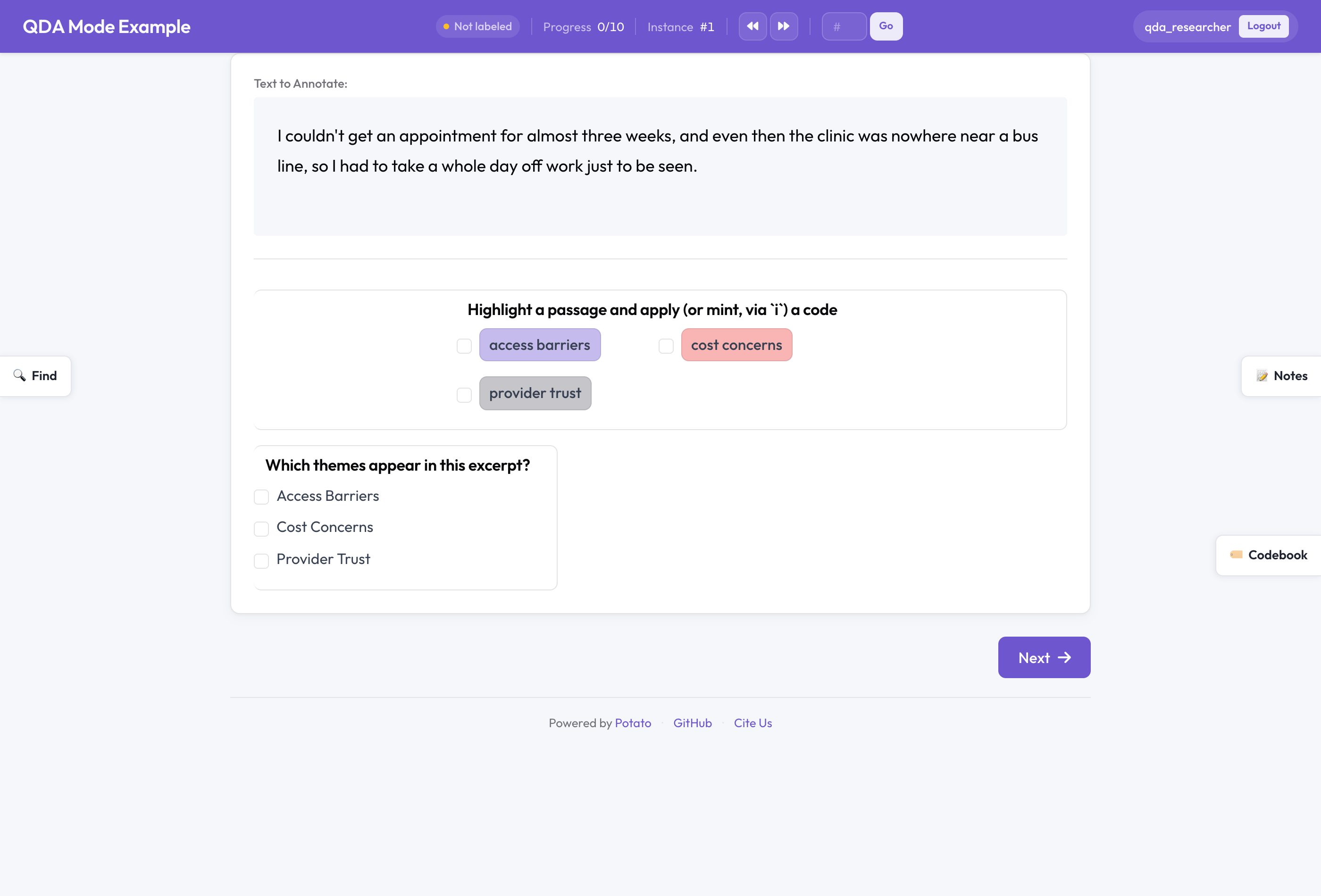 QDA 모드의 Potato
QDA 모드의 Potato
스위치 하나, 질적 기본값
Potato의 작동 방식 대부분은 서로 매우 다른 작업들 사이에서 공유됩니다. NER 데이터셋의 개체명에 레이블을 다는 바로 그 스팬 스킴이 인터뷰의 구절에도 레이블을 달 수 있습니다. 이 두 작업의 차이는 기능 집합이 아니라 자세에 있습니다. 크라우드소싱 NER 프로젝트는 고정된 레이블 집합과 일치도를 재기 위한 중첩 샘플링을 원합니다. 반면 인터뷰 스무 건을 홀로 코딩하는 연구자는 읽으면서 코드를 만들어 내고, 자신이 본 것에 대해 비공개 메모를 남기고 싶어 합니다.
QDA 모드는 그 두 번째 자세를 전제하는 단 하나의 스위치입니다.
qda_mode:
enabled: true # compose codebook + memos + cases + searchqda_mode.enabled: true로 설정하면 Potato의 범용 기능들이 질적 기본값으로 전환됩니다. 코드북은 잠기는 대신 코딩하는 동안 편집할 수 있게 됩니다. 메모 사이드바가 켜집니다. 케이스가 자동 감지와 함께 켜집니다. 코드북 기반으로 표시한 어떤 스팬 스킴에서든 인비보 코딩을 쓸 수 있게 됩니다.
| 기능 | 표준 기본값 | QDA 모드에서 |
|---|---|---|
| 코드북 모드 | fixed | open: 작업하면서 코드를 추가, 이름 변경, 색 변경, 이동, 삭제 |
| 메모 사이드바 | 꺼짐 | 켜짐 |
| 케이스 | 꺼짐 | 켜짐, 자동 감지 포함 |
| 주석자 검색-후-점유 | 꺼짐 | 사용 가능 (search.annotator_claim: true) |
| 인비보 코딩 키 | i | 코드북 기반의 모든 스팬 스킴에서 활성 |
이 가운데 어느 것도 못 박혀 있지 않습니다. QDA 모드는 출발점만 바꿀 뿐이며, 모든 기본값은 재정의할 수 있습니다. 단 하나의 예외는 안전장치입니다. Prolific이나 Mechanical Turk 같은 크라우드소싱 백엔드를 연결하면, Potato는 코드북을 강제로 fixed로 잠가, 보수를 받는 주석자가 공유 스킴을 당신 모르게 뜯어고치지 못하게 합니다.
부품들
살아 있는 코드북
근거 이론 방식의 코딩에서 코드북은 미리 작성해 두는 것이 아닙니다. 읽어 나가면서 자라납니다. 되풀이되는 생각을 알아채 이름을 붙이고, 일주일 뒤에는 두 코드가 사실 같은 것임을 깨달아 합칩니다.
스팬 스킴을 표시하면 코드북의 일부가 됩니다.
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]이 labels는 출발 집합일 뿐 우리가 아닙니다. open 코드북 모드에서는 작업하면서 코드를 추가, 이름 변경, 색 변경, 이동, 삭제합니다. extensible 모드는 코더가 코드를 추가하도록 허용하되 공유된 코드는 삭제하지 못하게 합니다. fixed는 스킴을 확정한 경우를 위한 잠긴 고전 모드입니다.
인비보 코딩
인비보 코딩은 참여자 자신의 말을 그대로 코드로 삼습니다. 누군가 "그냥 회신 전화를 받지 못했어요"라고 말하면 "회신 전화를 받지 못했다"가 글자 그대로 코드가 됩니다.
코드북 기반 스팬 스킴에서 구절을 선택하고 인비보 키(codebook_invivo_key, 기본값 i)를 누릅니다. Potato는 강조된 텍스트에서 곧장 코드를 주조합니다. 코퍼스 전반에 걸쳐 이렇게 하다 보면 파편화가 적이 됩니다. "회신 없음", "회신 전화를 받지 못했다", "끝내 전화가 안 왔다"가 하나의 생각을 가리키는 세 개의 코드가 되어 버리는 식입니다. 코드 작성기는 입력하는 동안 거의 중복되는 코드를 띄워 주어 이를 막습니다. 또 하나를 새로 만들어 내는 대신 기존 코드를 재사용하게 하는 것입니다.
메모
메모 없는 코딩은 코드 뒤에 깔린 추론을 잃습니다. 메모는 인스턴스나 특정 텍스트 선택에 붙는 분석적 노트입니다. 비공개로 둘 수도, 팀과 공유할 수도 있습니다. "왜 이걸 이렇게 코딩했는가"가 사는 곳이며, 인용문과 함께 내보내져 프로젝트가 끝난 뒤에도 감사 추적이 살아남습니다.
케이스
케이스는 발췌들을 하나의 분석 단위로 묶습니다. 참여자, 문서, 현장 방문 같은 것입니다. 발췌가 묶이고 나면 케이스 수준의 속성이 위로 끌어올려져, 참여자 변수에 견주어 코드를 표로 집계할 수 있습니다. 각 인터뷰에 condition 필드가 있다면, 관리자 교차표는 어떤 코드가 조건별로 어떻게 분포하는지 보여 줄 수 있습니다.
cases:
enabled: true
key: participant_id
attributes: [condition]검색
코퍼스는 어떤 단어의 어느 언급으로든 바로 건너뛸 수 있어야 비로소 탐색할 수 있습니다. QDA 모드에는 데이터셋 전체에 대한 FTS5 전문 검색이 들어 있습니다. annotator_claim: true이면 코더는 어떤 검색 결과든 곧바로 자신의 큐로 끌어올 수 있습니다. 한 명의 분석자가 처음부터 끝까지 순서대로 읽는 대신 주제별로 코퍼스를 헤쳐 나가는 방식이 바로 이것입니다.
search:
enabled: true
annotator_claim: true어떻게 맞물리는가
내부에서는 코드북, 메모, 케이스, 검색이 모두 같은 프로젝트 데이터베이스를 읽고 씁니다. 그래서 한곳에서 주조한 코드가 다른 모든 곳에서 곧바로 검색되고 내보낼 수 있게 됩니다.
 QDA 모드가 공유 저장소 위에서 부품들을 어떻게 구성하는가
QDA 모드가 공유 저장소 위에서 부품들을 어떻게 구성하는가
완전한 설정 예시
작지만 완결된 연구 예시입니다. cases, search, 메모 블록은 선택 사항이며(QDA 모드는 케이스와 메모를 이미 켭니다), 케이스 키 같은 기본값을 조정할 때만 적습니다.
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]2.6을 설치한 뒤 리포지토리 루트에서 실행합니다.
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000코딩 결과를 다시 꺼내기
두 개의 익스포터가 코딩된 데이터를 질적 논문에 필요한 산출물로 바꿔 줍니다.
- **
codebook**은 코드마다 한 행을 주며, 계층, 설명, 색상, 사용 횟수를 담습니다. - **
quotation_report**는 코딩된 스팬마다 한 행을 줍니다. 인용문, 문자 오프셋, 출처 인스턴스, 코더입니다.include_memos=true를 더하면 메모도 붙습니다.
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csv같은 자료를 두 명 이상이 코딩한다면 신뢰도 수치가 필요할 것입니다. Potato는 코드에 대해 Cohen's 및 Fleiss' kappa를 보고하며, 이 기능은 이 익스포터들과 함께 2.5 릴리스에서 도입되었습니다.
어디에 자리하는가
QDA 모드는 모든 축에서 NVivo의 기능을 능가하려 하지 않습니다. 그것이 내놓는 것은 다른 교환입니다. 무료이고, 오픈 소스이며, 웹 기반이고, 협업이 가능하며, 머신러닝 주석과 에이전트 평가와 같은 도구 안에 함께 자리합니다. 연구실에서 이미 레이블링에 Potato를 돌리고 있다면, 질적 코딩은 이제 라이선스가 걸린 별도의 데스크톱 소프트웨어가 아니라 설정 블록 하나 거리에 있습니다.
QDA 모드는 Potato 2.6에 실립니다. 전체 문서는 모든 옵션을 다루며, 주석자 간 일치도 가이드는 신뢰도 지표를 설명합니다.