더 나은 코딩 에이전트를 학습하기 위한 프로세스 보상 데이터 수집 방법
Potato를 사용해 PRM 학습을 위한 단계별 보상 신호를 수집하는 단계별 가이드. 첫-오류 모드, 단계별 어노테이션, 학습 파이프라인으로의 내보내기를 다룹니다.
프로세스 보상 모델이란?
 Two ways to label process rewards
Two ways to label process rewards
결과 보상 모델(ORM)은 코딩 에이전트 궤적의 끝만 봅니다. 코드가 컴파일되었는가, 테스트가 통과했는가, 이슈가 해결되었는가? 프로세스 보상 모델(PRM)은 그 대신 중간 단계마다 점수를 매깁니다. 모든 단계에 보상 신호가 있으면 학습 방법이 에이전트가 어디서 잘못했는지 짚어낼 수 있고, 이는 학습을 더 표본 효율적으로 만들고 일반화에도 도움이 되는 경향이 있습니다.
최근 연구가 이를 뒷받침합니다. AgentPRM은 단계별 보상 신호가 결과만으로 하는 지도학습 대비 SWE-bench에서 에이전트 성능을 12-18% 향상시킨다고 보고했습니다. ToolRM은 도구 호출별 보상이 에이전트가 언제 어떤 도구를 써야 하는지 학습하는 데 도움이 된다는 것을 밝혔습니다. DeepSWE는 프로세스 보상을 몬테카를로 트리 탐색과 결합해 어려운 소프트웨어 엔지니어링 과제에서 최첨단 결과를 냈습니다.
이 모든 것이 필요로 하는 것은 좋은 단계별 인간 어노테이션이며, 보통 이것이 병목입니다. Potato의 프로세스 보상 스키마는 그 데이터 수집을 더 빠르게 하도록 만들어졌습니다. 기반이 되는 스키마는 궤적 평가 문서를, 트레이스 입력 세부사항은 에이전트 트레이스 문서를 참고하십시오.
두 가지 어노테이션 모드
Potato에는 속도와 세분성을 맞바꾸는 두 가지 PRM 어노테이션 모드가 있습니다. 데이터 예산과 목표에 맞는 것을 고르십시오.
첫-오류 모드
첫-오류 모드에서는 어노테이터가 궤적을 위에서 아래로 읽으며 에이전트가 실수를 저지른 첫 번째 단계를 클릭합니다. 그러면 Potato가 그 이전의 모든 단계를 정확으로, 클릭한 단계부터 끝까지의 모든 단계를 부정확으로 표시합니다.
이는 어노테이터가 단 하나의 결정 지점만 찾으면 되기 때문에 빠릅니다. 오류가 연쇄적으로 번질 때, 즉 에이전트가 한번 길을 벗어나면 좀처럼 회복하지 못할 때 잘 작동하는데, 이것이 실제로 흔한 경우입니다.
annotation_schemes:
- annotation_type: process_reward
name: prm_first_error
mode: "first_error"
labels:
correct: "Correct"
incorrect: "Incorrect"
description: >
Review the agent's steps from top to bottom. Click on the
first step where the agent makes a mistake. All steps before
your selection will be marked correct; all steps after
(including the selected step) will be marked incorrect.
allow_all_correct: true
allow_all_incorrect: true
highlight_clicked_step: true
auto_scroll_on_click: true
show_step_numbers: true
confirmation_dialog: true # Confirm before submitting첫-오류 어노테이션 워크플로는 다음과 같습니다.
- 어노테이터가 트레이스를 열면 CodingTraceDisplay 컴포넌트로 렌더링된 모든 단계를 봅니다.
- diff, 터미널 출력, 추론을 살피면서 단계를 순차적으로 읽어 나갑니다.
- 첫 번째 부정확한 단계를 찾으면 그 옆의 오류 마커를 클릭합니다.
- 단계 0부터 N-1까지는 초록색(정확)으로, 단계 N부터 끝까지는 빨간색(부정확)으로 바뀝니다.
- 어노테이터가 자동 라벨링을 검토하고 "Submit"을 클릭해 확정합니다.
트레이스 전체가 정확하다면(에이전트가 과제를 완벽하게 해결했다면) 어노테이터는 "All Correct"를 클릭합니다. 맨 첫 단계가 이미 틀렸다면 단계 0을 클릭하거나 "All Incorrect"를 사용합니다.
다음은 작동 중인 PRM 어노테이션 인터페이스입니다.
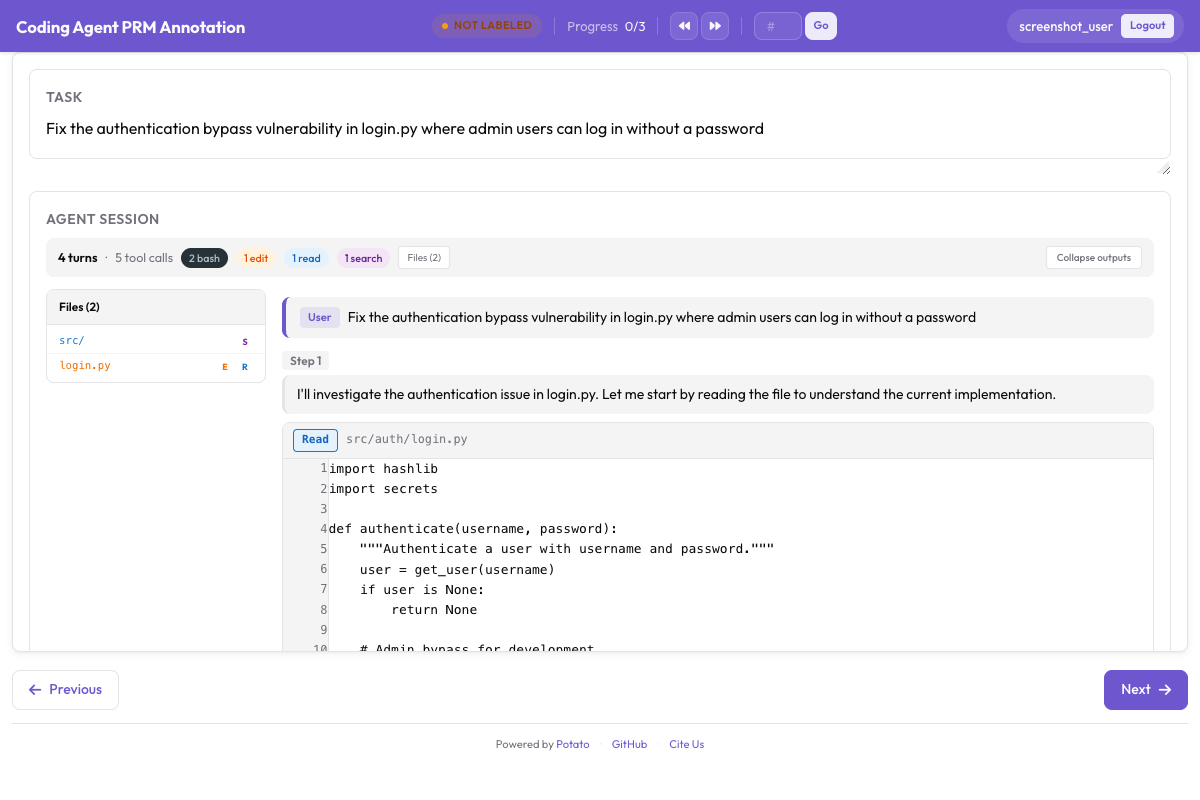 첫-오류 모드에서는 첫 번째 부정확한 단계를 클릭하면 이후의 모든 단계가 자동으로 표시됩니다
첫-오류 모드에서는 첫 번째 부정확한 단계를 클릭하면 이후의 모든 단계가 자동으로 표시됩니다
단계별 모드
단계별 모드에서는 모든 단계가 각자의 라벨을 받습니다. 이는 에이전트가 오류에서 부분적으로 회복하거나, 해롭지 않지만 불필요한 우회를 하거나, 그 자체로는 괜찮지만 맥락상 틀린 단계를 밟는 경우까지 포착하므로 더 풍부한 데이터를 만들어 냅니다.
annotation_schemes:
- annotation_type: process_reward
name: prm_per_step
mode: "per_step"
labels:
correct:
text: "Correct"
description: >
This step is logically sound, makes progress toward the goal,
and does not introduce bugs or unnecessary complexity.
keyboard_shortcut: "1"
color: "#22c55e"
partially_correct:
text: "Partially Correct"
description: >
This step is in the right direction but has flaws: incomplete
fix, unnecessary side effects, suboptimal approach, or missing
edge cases.
keyboard_shortcut: "2"
color: "#eab308"
incorrect:
text: "Incorrect"
description: >
This step is wrong, counterproductive, or introduces new bugs.
The agent should not have taken this action.
keyboard_shortcut: "3"
color: "#ef4444"
neutral:
text: "Neutral"
description: >
This step neither helps nor hurts. Includes reading files for
context or running diagnostic commands.
keyboard_shortcut: "4"
color: "#94a3b8"
require_all_steps: true
show_progress_bar: true
enable_keyboard_navigation: true
step_navigation:
next_step: "j"
previous_step: "k"
next_unlabeled: "n"PRM 어노테이션 프로젝트 설정하기
1단계: 트레이스 데이터 준비
입력 데이터는 각 줄이 에이전트의 궤적을 담은 JSON 객체인 JSONL 파일이어야 합니다. 핵심 필드는 id, issue_description, structured_turns입니다.
{
"id": "trace_001",
"issue_description": "Fix the TypeError in parse_config() when config file is empty",
"repo": "myorg/myproject",
"base_commit": "a1b2c3d",
"structured_turns": [
{
"step_idx": 0,
"type": "thinking",
"content": "I need to understand what parse_config does and where the TypeError occurs. Let me read the file first."
},
{
"step_idx": 1,
"type": "file_read",
"path": "src/config.py",
"content": "def parse_config(path):\n with open(path) as f:\n data = json.load(f)\n return data['settings']",
"start_line": 1,
"end_line": 4
},
{
"step_idx": 2,
"type": "thinking",
"content": "The bug is on line 4. When the file is empty, json.load returns None, and None['settings'] raises TypeError. I should add a check."
},
{
"step_idx": 3,
"type": "file_edit",
"path": "src/config.py",
"diff": "--- a/src/config.py\n+++ b/src/config.py\n@@ -1,4 +1,6 @@\n def parse_config(path):\n with open(path) as f:\n data = json.load(f)\n+ if data is None:\n+ return {}\n return data['settings']"
},
{
"step_idx": 4,
"type": "bash_command",
"command": "python -m pytest tests/test_config.py -v",
"output": "tests/test_config.py::test_parse_config_empty PASSED\ntests/test_config.py::test_parse_config_valid PASSED\n\n2 passed in 0.12s",
"exit_code": 0
}
]
}기존 에이전트 포맷에서 변환하는 경우 트레이스 변환기 도구를 사용하십시오.
# Convert Claude Code traces
potato convert-traces \
--format claude_code \
--input ./raw_traces/ \
--output ./data/traces.jsonl
# Convert SWE-Agent trajectories
potato convert-traces \
--format swe_agent \
--input ./swe_agent_output/ \
--output ./data/traces.jsonlPotato는 적절한 diff 강조와 함께 코딩 에이전트 트레이스를 렌더링합니다.
 코드 diff, 터미널 출력, 파일 읽기가 구문 강조와 함께 렌더링됩니다
코드 diff, 터미널 출력, 파일 읽기가 구문 강조와 함께 렌더링됩니다
2단계: 설정 만들기
다음은 첫-오류 모드를 사용하는 PRM 어노테이션을 위한 완전한 프로젝트 설정입니다.
# config.yaml
project_name: "PRM Data Collection - SWE-bench Traces"
port: 8000
data:
source: "local"
input_path: "./data/traces.jsonl"
data_format: "coding_trace"
coding_agent:
display:
diff_style: "unified"
context_lines: 3
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
position: "left"
collapsible:
auto_collapse_thinking: true
auto_collapse_long_output: true
long_output_threshold: 50
annotation_schemes:
- annotation_type: process_reward
name: step_reward
mode: "first_error"
labels:
correct: "Correct Step"
incorrect: "Incorrect Step"
allow_all_correct: true
allow_all_incorrect: true
description: >
Review the agent's trajectory step by step. Click the first
step where the agent makes an error. If the entire trajectory
is correct, click "All Correct."
highlight_clicked_step: true
confirmation_dialog: true
- annotation_type: radio
name: outcome
label: "Did the agent resolve the issue?"
options:
- value: "resolved"
text: "Fully Resolved"
- value: "partial"
text: "Partially Resolved"
- value: "not_resolved"
text: "Not Resolved"
- annotation_type: text_input
name: error_description
label: "If incorrect, briefly describe the error"
placeholder: "e.g., Agent edited the wrong file..."
required: false
show_if:
field: "step_reward"
condition: "has_error"
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 15
minimum_time_per_instance: 20
annotators:
- username: "reviewer1"
password: "pw_reviewer1"
- username: "reviewer2"
password: "pw_reviewer2"
- username: "reviewer3"
password: "pw_reviewer3"3단계: 어노테이션 서버 실행
# Start the annotation server
potato start config.yaml -p 8000
# Or run in the background
nohup potato start config.yaml -p 8000 > potato.log 2>&1 &http://localhost:8000으로 이동해 구성된 어노테이터 계정 중 하나로 로그인한 뒤 트레이스 검토를 시작하십시오.
4단계: 진행 상황 모니터링
어노테이션이 진행되는 동안 진행 상황과 일치도를 모니터링하십시오.
# Check annotation progress
potato status config.yaml
# View inter-annotator agreement
potato agreement config.yaml --metric krippendorff_alpha학습 포맷으로 내보내기
어노테이션이 완료되면 학습 파이프라인이 기대하는 포맷으로 데이터를 내보내십시오.
보상 모델 학습을 위한 PRM 포맷
PRM 내보내기 포맷은 단계별 라벨이 담긴, 트레이스당 하나의 JSON 객체를 만들어 냅니다.
potato export \
--format prm \
--project ./output/ \
--output ./training_data/prm_labels.jsonl출력은 다음과 같습니다.
{
"trace_id": "trace_001",
"issue_description": "Fix the TypeError in parse_config() when config file is empty",
"total_steps": 5,
"first_error_step": null,
"all_correct": true,
"steps": [
{"step_idx": 0, "type": "thinking", "label": "correct", "reward": 1.0},
{"step_idx": 1, "type": "file_read", "label": "correct", "reward": 1.0},
{"step_idx": 2, "type": "thinking", "label": "correct", "reward": 1.0},
{"step_idx": 3, "type": "file_edit", "label": "correct", "reward": 1.0},
{"step_idx": 4, "type": "bash_command", "label": "correct", "reward": 1.0}
]
}DPO/RLHF 선호도 쌍
같은 이슈에 대한 여러 트레이스(예: 서로 다른 에이전트나 서로 다른 실행)가 있을 때, Potato는 PRM 라벨을 기반으로 선호도 쌍을 생성할 수 있습니다.
potato export \
--format preference_pairs \
--project ./output/ \
--output ./training_data/preferences.jsonl \
--pair_by "issue_id"선호도 쌍 내보내기는 같은 과제를 시도한 트레이스들을 비교하고 단계별 라벨을 기반으로 더 나은 것을 선택합니다.
{
"prompt": "Fix the TypeError in parse_config() when config file is empty",
"chosen_trace_id": "trace_001",
"rejected_trace_id": "trace_002",
"chosen_first_error": null,
"rejected_first_error": 3,
"chosen_steps": 5,
"rejected_steps": 7,
"margin": 0.8
}SWE-bench 호환 결과
벤치마킹을 위해 SWE-bench 포맷으로 내보내십시오.
potato export \
--format swe_bench \
--project ./output/ \
--output ./training_data/swe_bench_results.json분석 예시
어노테이션을 수집한 뒤, 데이터를 분석하고 패턴을 찾기 위해 다음 Python 스니펫을 사용하십시오.
단계 유형별 단계 수준 정확도
import json
from collections import defaultdict
# Load PRM annotations
with open("training_data/prm_labels.jsonl") as f:
traces = [json.loads(line) for line in f]
# Compute accuracy by step type
type_stats = defaultdict(lambda: {"correct": 0, "total": 0})
for trace in traces:
for step in trace["steps"]:
step_type = step["type"]
type_stats[step_type]["total"] += 1
if step["label"] == "correct":
type_stats[step_type]["correct"] += 1
print("Step-Level Accuracy by Type:")
print("-" * 45)
for step_type, stats in sorted(type_stats.items()):
acc = stats["correct"] / stats["total"] * 100
print(f" {step_type:<20} {acc:5.1f}% ({stats['correct']}/{stats['total']})")공통 실패 지점 찾기
import json
from collections import Counter
with open("training_data/prm_labels.jsonl") as f:
traces = [json.loads(line) for line in f]
# Analyze where errors first occur
error_positions = []
error_types_at_first_error = Counter()
for trace in traces:
if trace["first_error_step"] is not None:
pos = trace["first_error_step"]
total = trace["total_steps"]
# Normalize position to 0-1 range
error_positions.append(pos / total)
# Track what type of step caused the first error
error_step = trace["steps"][pos]
error_types_at_first_error[error_step["type"]] += 1
if error_positions:
avg_pos = sum(error_positions) / len(error_positions)
print(f"Average first-error position: {avg_pos:.2f} (0=start, 1=end)")
print(f"Traces with errors: {len(error_positions)}/{len(traces)}")
print()
print("Most common step types at first error:")
for step_type, count in error_types_at_first_error.most_common(5):
print(f" {step_type}: {count}")PRM 라벨에 대한 어노테이터 간 일치도 계산
import json
import numpy as np
from sklearn.metrics import cohen_kappa_score
def load_annotations(annotator_file):
"""Load annotations from a single annotator's output file."""
with open(annotator_file) as f:
data = {item["trace_id"]: item for item in
(json.loads(line) for line in f)}
return data
ann1 = load_annotations("output/reviewer1/annotations.jsonl")
ann2 = load_annotations("output/reviewer2/annotations.jsonl")
# Find overlapping traces
overlap_ids = set(ann1.keys()) & set(ann2.keys())
print(f"Overlapping traces: {len(overlap_ids)}")
# Compare first-error step labels
labels1 = []
labels2 = []
for trace_id in overlap_ids:
fe1 = ann1[trace_id].get("first_error_step", -1)
fe2 = ann2[trace_id].get("first_error_step", -1)
# Bin into: all_correct, early_error (first half), late_error (second half)
total = ann1[trace_id]["total_steps"]
for fe, labels in [(fe1, labels1), (fe2, labels2)]:
if fe is None or fe == -1:
labels.append("all_correct")
elif fe < total / 2:
labels.append("early_error")
else:
labels.append("late_error")
kappa = cohen_kappa_score(labels1, labels2)
print(f"Cohen's kappa (binned first-error): {kappa:.3f}")효율적인 PRM 데이터 수집을 위한 팁
속도를 위해서는 첫-오류 모드를 사용하십시오. 탐색(MCTS, best-of-N 샘플링)을 안내할 PRM을 학습하는 경우, 첫-오류 모드는 단계별 모드의 2-3배 어노테이션 속도로도 충분한 신호를 줍니다. 어차피 대부분의 에이전트는 연쇄적으로 실패합니다. 한 번의 실수가 잘못된 단계들의 연쇄로 이어집니다.
세부 정보가 필요할 때는 단계별 모드를 사용하십시오. 부분적 회복, 해롭지 않은 우회에 관심이 있거나, 두 개를 초과하는 라벨로 단계 수준 보상 모델을 구축하고 있다면, 단계별 모드는 추가 시간을 들일 만한 값을 합니다.
PRM을 쌍대 비교와 결합하십시오. 트레이스를 PRM으로 개별 라벨링한 뒤, 같은 이슈를 시도한 트레이스에 대해 쌍대 비교를 실행하십시오. 한 번의 어노테이션 작업으로 단계별 보상과 선호도 쌍을 모두 얻습니다.
숙련된 어노테이터로 시작하십시오. PRM 어노테이션은 코드, diff, 터미널 출력을 읽는 일을 뜻합니다. 숙련된 개발자 소수로 시작해 일치도를 측정하고, 예시에 맞춰 보정한 뒤 규모를 키우십시오.
인스턴스당 최소 시간을 설정하십시오. 트레이스는 복잡해집니다. 30초의 하한은 어노테이터가 실제로 변경 사항을 읽지 않고 서둘러 넘어가는 것을 막아 줍니다. 평균 트레이스 길이에 맞춰 조정하십시오.
보정 예시를 제공하십시오. 프로덕션 어노테이션 전에, 모두가 같은 10-20개 트레이스를 라벨링하고 어디서 의견이 갈렸는지 이야기 나누게 하십시오. 이는 일관성에 큰 차이를 만듭니다.