AI 에이전트를 나란히 비교하기: 이진, 척도, 다차원 모드
Potato에서 세 가지 모드로 쌍대 에이전트 비교를 설정합니다: 이진 선호, 연속 척도, 정당화가 필수인 차원별 다기준 판단.
에이전트 평가에 쌍대 비교를 쓰는 이유
코딩 에이전트의 trace를 1에서 10까지의 척도로 평가하도록 요청하면 노이즈가 많은 데이터를 얻게 되는데, 사람마다 그 척도를 다르게 보정하기 때문입니다. 한 어노테이터의 7은 다른 어노테이터의 5입니다. 쌍대 비교는 이 문제를 우회합니다. trace를 단독으로 평가하는 대신, 어노테이터는 두 개를 나란히 보고 어느 쪽이 더 나은지 말합니다. 이런 일대일 판단은 내리기가 더 쉽고, 사람들 사이에서 더 일관되며, 마침 Direct Preference Optimization(DPO)과 Reinforcement Learning from Human Feedback(RLHF)에 정확히 필요한 바로 그것입니다.
이는 언어 모델 정렬을 위한 보상 모델을 훈련할 때 쓰이는 것과 같은 접근 방식이며, 코딩 에이전트에도 깔끔하게 이어집니다: 에이전트 궤적 쌍 사이의 인간 선호를 수집하고, 그것으로 보상 모델을 훈련한 다음, 그 모델로 에이전트 훈련을 안내하거나 추론 시 N개 후보 중 최선을 고릅니다.
Potato에는 세 가지 쌍대 비교 모드가 있으며, 각각 서로 다른 평가 필요와 데이터 예산에 맞습니다.
인터페이스는 두 trace를 나란히 배치합니다:
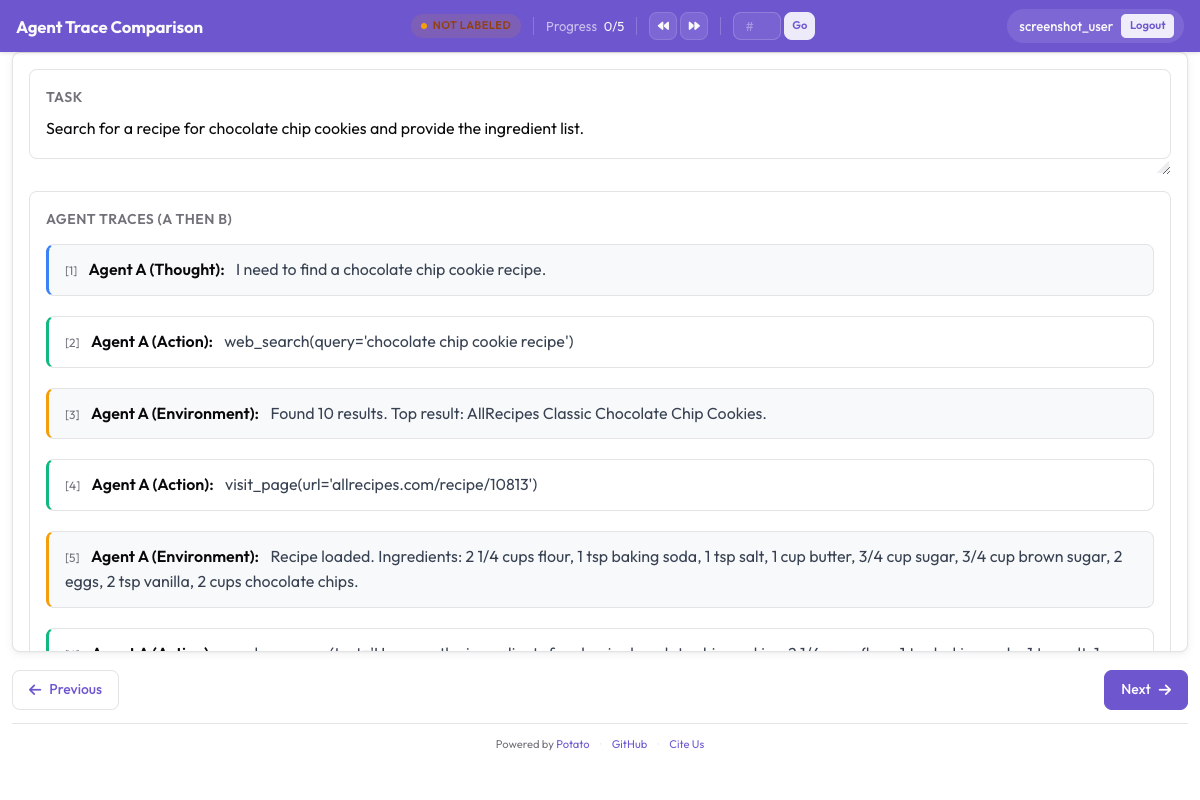 Annotators compare two agent traces and select which approach was better
Annotators compare two agent traces and select which approach was better
모드 1: 이진 선호
이것은 가장 단순하고 빠른 모드입니다. 어노테이터는 두 trace를 나란히 보고 더 나은 쪽을 클릭합니다. 선택 사항인 무승부 버튼은 둘 다 똑같이 좋거나 똑같이 나쁜 경우를 처리합니다.
이진 모드를 언제 쓸까
많은 선호 데이터를 빠르게 모아야 할 때 이진 모드를 택하십시오. 기본 보상 모델 훈련, 에이전트 승률 산출, Elo 리더보드 구축에 잘 맞습니다. 단점은 뉘앙스를 잃는다는 것입니다. 어느 trace가 이겼는지는 알지만, 얼마나 또는 어떤 면에서 이겼는지는 알 수 없습니다.
설정
# config.yaml
project_name: "Agent Comparison - Binary"
port: 8000
data:
source: "local"
input_path: "./data/paired_traces.jsonl"
data_format: "paired_coding_trace"
coding_agent:
display:
diff_style: "unified"
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
position: "left"
collapsible:
auto_collapse_thinking: true
comparison:
layout: "side_by_side" # "side_by_side" or "tabbed"
label_a: "Agent A"
label_b: "Agent B"
randomize_order: true # Randomize which trace appears on which side
show_agent_identity: false # Hide agent names to avoid bias
sync_scroll: false # Independent scrolling for each trace
annotation_schemes:
- annotation_type: pairwise_comparison
name: preference
mode: "binary"
question: "Which agent produced a better solution?"
options:
- value: "a"
text: "Agent A is better"
keyboard_shortcut: "1"
- value: "b"
text: "Agent B is better"
keyboard_shortcut: "2"
- value: "tie"
text: "Tie (equally good or equally bad)"
keyboard_shortcut: "3"
allow_tie: true
require_justification: false # No text explanation needed
- annotation_type: radio
name: confidence
label: "How confident are you?"
options:
- value: "high"
text: "Very confident"
- value: "medium"
text: "Somewhat confident"
- value: "low"
text: "Not confident"
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 20
attention_checks:
enabled: true
frequency: 10 # Insert a check every 10 instances
type: "duplicate_reversed" # Re-show a pair with A/B swapped
annotators:
- username: "judge1"
password: "judge_pw_1"
- username: "judge2"
password: "judge_pw_2"어노테이션 작업 흐름
어노테이터는 분할 화면을 받습니다. 왼쪽에는 Trace A가 전체 CodingTraceDisplay와 함께 렌더링됩니다: diff, 터미널 블록, 파일 읽기, 사고 과정. 오른쪽에는 같은 작업에 대한 Trace B가 있습니다. 각 측은 독립적으로 스크롤됩니다.
작업 설명은 두 trace 위에 자리해, 어노테이터가 두 에이전트가 무엇을 하려 했는지 알 수 있습니다.
그 아래에는 세 개의 버튼이 있습니다: "Agent A is better", "Agent B is better", "Tie." randomize_order가 켜져 있으면 어느 에이전트가 A이고 어느 쪽이 B인지가 인스턴스마다 섞이므로, 어노테이터가 왼쪽이나 오른쪽 측에 치우치는 습관에 빠지지 않습니다.
더 세밀한 평가를 위해 인터페이스는 여러 차원도 지원합니다:
 Binary preference, continuous scale, and multi-dimension modes are available
Binary preference, continuous scale, and multi-dimension modes are available
모드 2: 연속 척도
척도 모드에서는 어느 쪽이 이겼는지뿐 아니라 한 trace가 얼마나 더 나은지를 어노테이터가 말할 수 있습니다. 한 번의 클릭 대신, 왼쪽의 "A가 훨씬 더 나음"부터 오른쪽의 "B가 훨씬 더 나음"까지 이어지고 가운데에 "동일"이 있는 슬라이더를 끕니다.
척도 모드를 언제 쓸까
선호의 방향뿐 아니라 강도가 중요할 때 척도 모드를 사용하십시오. 슬라이더가 극단에 가까우면 명확한 품질 차이를 뜻하고, 중앙에 가까우면 둘이 막상막하였음을 뜻합니다. DPO와 유사한 파이프라인은 그 강도로 예제에 가중치를 주어 명백한 판단에 더 무게를 둘 수 있습니다.
설정
# config.yaml
project_name: "Agent Comparison - Scale"
port: 8000
data:
source: "local"
input_path: "./data/paired_traces.jsonl"
data_format: "paired_coding_trace"
coding_agent:
display:
diff_style: "unified"
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
collapsible:
auto_collapse_thinking: true
comparison:
layout: "side_by_side"
randomize_order: true
show_agent_identity: false
annotation_schemes:
- annotation_type: pairwise_comparison
name: preference_scale
mode: "scale"
question: "Which agent produced a better solution, and by how much?"
scale:
points: 7 # 7-point scale
labels:
1: "A is much better"
2: "A is better"
3: "A is slightly better"
4: "Equal"
5: "B is slightly better"
6: "B is better"
7: "B is much better"
default: 4 # Start at "Equal"
show_numeric_value: true
require_justification: true
justification_label: "Briefly explain your rating"
justification_min_length: 20
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 20
annotators:
- username: "judge1"
password: "judge_pw_1"
- username: "judge2"
password: "judge_pw_2"5점 척도 사용하기
더 빠른 어노테이션과 약간 낮은 세밀도를 위해 5점 척도로 줄이십시오:
annotation_schemes:
- annotation_type: pairwise_comparison
name: preference_scale_5
mode: "scale"
question: "Compare the two solutions"
scale:
points: 5
labels:
1: "A is clearly better"
2: "A is somewhat better"
3: "About equal"
4: "B is somewhat better"
5: "B is clearly better"
default: 3모드 3: 다차원 비교
이것은 가장 상세한 모드입니다. 하나의 전체 선호 대신, 어노테이터는 각 trace를 여러 독립 차원에서 평가합니다. 모든 차원은 자체 A/B/무승부 판단을 받고, 모든 판단에는 작성된 정당화가 필요합니다.
다차원 모드를 언제 쓸까
어느 에이전트가 이겼는지뿐 아니라 왜 그런지를 알고 싶을 때 이것을 사용하십시오. 한 trace는 코드가 올바르지만 효율이 형편없을 수 있고, 다른 하나는 효율적이지만 엣지 케이스를 놓칠 수 있습니다. 여기서 나오는 차원별 데이터는 차원별 보상 모델을 훈련하거나, 에이전트를 만드는 사람들에게 상세한 피드백을 돌려줄 수 있습니다.
설정
# config.yaml
project_name: "Agent Comparison - Multi-Dimension"
port: 8000
data:
source: "local"
input_path: "./data/paired_traces.jsonl"
data_format: "paired_coding_trace"
coding_agent:
display:
diff_style: "unified"
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
collapsible:
auto_collapse_thinking: true
comparison:
layout: "side_by_side"
randomize_order: true
show_agent_identity: false
annotation_schemes:
- annotation_type: pairwise_comparison
name: multi_dim_comparison
mode: "multi_dimension"
question: "Compare the two solutions along each dimension"
dimensions:
- name: "correctness"
label: "Correctness"
description: >
Does the solution correctly fix the issue? Are there remaining
bugs, missed edge cases, or incorrect logic?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Why is this solution more correct?"
weight: 0.4 # Weight for computing overall preference
- name: "efficiency"
label: "Efficiency"
description: >
How efficient is the agent's process? Does it take unnecessary
steps, read irrelevant files, or make redundant edits?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which agent was more efficient and why?"
weight: 0.2
- name: "code_quality"
label: "Code Quality"
description: >
Is the code well-written? Consider readability, naming,
error handling, documentation, and adherence to existing patterns.
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which produces better quality code?"
weight: 0.2
- name: "communication"
label: "Communication"
description: >
How well does the agent explain its reasoning? Are its thinking
steps clear and logical? Does it identify the root cause?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which agent communicates its approach better?"
weight: 0.1
- name: "robustness"
label: "Robustness"
description: >
Does the solution handle edge cases? Does the agent verify its
changes with tests? Is the fix narrow and targeted or fragile?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which solution is more robust?"
weight: 0.1
overall_preference:
enabled: true # Also ask for overall preference
question: "Overall, which solution do you prefer?"
options: ["A", "B", "Tie"]
require_justification: true
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 25 # Higher overlap for this detailed task
minimum_time_per_instance: 120 # 2 minutes minimum for thorough review
annotators:
- username: "judge1"
password: "judge_pw_1"
- username: "judge2"
password: "judge_pw_2"페어링된 trace 데이터 준비하기
세 모드 모두 페어링된 trace를 입력으로 받습니다. JSONL 파일의 각 줄은 같은 작업을 시도한 두 trace를 담습니다.
데이터 형식
{
"id": "pair_001",
"task_description": "Fix the IndexError in process_batch() when the input list is empty",
"repo": "myorg/myproject",
"trace_a": {
"agent": "claude_code",
"model": "claude-sonnet-4-20250514",
"structured_turns": [
{
"step_idx": 0,
"type": "file_read",
"path": "src/batch.py",
"content": "def process_batch(items):\n result = items[0]\n ...",
"start_line": 10,
"end_line": 25
},
{
"step_idx": 1,
"type": "file_edit",
"path": "src/batch.py",
"diff": "--- a/src/batch.py\n+++ b/src/batch.py\n@@ -10,3 +10,5 @@\n def process_batch(items):\n+ if not items:\n+ return []\n result = items[0]\n"
},
{
"step_idx": 2,
"type": "bash_command",
"command": "python -m pytest tests/test_batch.py -v",
"output": "PASSED",
"exit_code": 0
}
]
},
"trace_b": {
"agent": "swe_agent",
"model": "gpt-4o",
"structured_turns": [
{
"step_idx": 0,
"type": "bash_command",
"command": "find . -name '*.py' | xargs grep 'process_batch'",
"output": "src/batch.py:def process_batch(items):\ntests/test_batch.py: process_batch([])",
"exit_code": 0
},
{
"step_idx": 1,
"type": "file_read",
"path": "src/batch.py",
"content": "def process_batch(items):\n result = items[0]\n ...",
"start_line": 1,
"end_line": 50
},
{
"step_idx": 2,
"type": "file_edit",
"path": "src/batch.py",
"diff": "--- a/src/batch.py\n+++ b/src/batch.py\n@@ -10,3 +10,6 @@\n def process_batch(items):\n+ if items is None or len(items) == 0:\n+ logger.warning('Empty input to process_batch')\n+ return []\n result = items[0]\n"
},
{
"step_idx": 3,
"type": "bash_command",
"command": "python -m pytest tests/ -v",
"output": "PASSED (12 tests)",
"exit_code": 0
}
]
}
}개별 trace로부터 쌍 만들기
같은 작업을 모두 수행한 개별 trace가 있다면, 페어링 유틸리티가 이를 조립해 줍니다:
# Generate all possible pairs for each task
potato pair-traces \
--input ./data/individual_traces.jsonl \
--output ./data/paired_traces.jsonl \
--pair_by "task_id" \
--strategy "all_pairs"
# Or sample a fixed number of pairs per task
potato pair-traces \
--input ./data/individual_traces.jsonl \
--output ./data/paired_traces.jsonl \
--pair_by "task_id" \
--strategy "sample" \
--pairs_per_task 3비교 데이터 내보내기
DPO/RLHF 선호 쌍
쌍대 비교의 주요 내보내기 형식은 DPO 또는 RLHF 훈련을 위한 선호 쌍입니다:
potato export \
--format dpo_preferences \
--project ./output/ \
--output ./training_data/preferences.jsonl이진 모드의 경우 출력이 단순합니다:
{
"prompt": "Fix the IndexError in process_batch() when the input list is empty",
"chosen": {"agent": "claude_code", "trace_id": "trace_a_001", "steps": [...]},
"rejected": {"agent": "swe_agent", "trace_id": "trace_b_001", "steps": [...]},
"annotator": "judge1",
"confidence": "high"
}척도 모드는 선호 강도를 추가합니다:
{
"prompt": "Fix the IndexError in process_batch()",
"chosen": {"agent": "claude_code", "trace_id": "trace_a_001"},
"rejected": {"agent": "swe_agent", "trace_id": "trace_b_001"},
"preference_strength": 0.83,
"scale_value": 2,
"justification": "Agent A found and fixed the bug in fewer steps with cleaner code"
}다차원 모드는 차원별 선호를 함께 담습니다:
{
"prompt": "Fix the IndexError in process_batch()",
"chosen": {"agent": "claude_code", "trace_id": "trace_a_001"},
"rejected": {"agent": "swe_agent", "trace_id": "trace_b_001"},
"overall_preference": "A",
"dimensions": {
"correctness": {"preference": "Tie", "justification": "Both correctly fix the bug"},
"efficiency": {"preference": "A", "justification": "A solves it in 3 steps vs 4"},
"code_quality": {"preference": "B", "justification": "B adds logging and handles None"},
"communication": {"preference": "A", "justification": "A's reasoning is more focused"},
"robustness": {"preference": "B", "justification": "B runs full test suite, not just one file"}
},
"weighted_score_a": 0.55,
"weighted_score_b": 0.45
}분석: 승률, Elo 레이팅, 차원별 분석
승률 계산하기
import json
from collections import defaultdict
with open("training_data/preferences.jsonl") as f:
prefs = [json.loads(line) for line in f]
wins = defaultdict(lambda: {"wins": 0, "losses": 0, "ties": 0})
for pref in prefs:
agent_chosen = pref["chosen"]["agent"]
agent_rejected = pref["rejected"]["agent"]
if agent_chosen == agent_rejected:
continue # Skip self-comparisons
if pref.get("overall_preference") == "Tie":
wins[agent_chosen]["ties"] += 1
wins[agent_rejected]["ties"] += 1
else:
wins[agent_chosen]["wins"] += 1
wins[agent_rejected]["losses"] += 1
print("Agent Win Rates:")
print("-" * 55)
for agent, record in sorted(wins.items()):
total = record["wins"] + record["losses"] + record["ties"]
win_rate = (record["wins"] + 0.5 * record["ties"]) / total * 100
print(f" {agent:<20} {win_rate:5.1f}% "
f"(W:{record['wins']} L:{record['losses']} T:{record['ties']})")Elo 레이팅 계산하기
import json
import math
from collections import defaultdict
def compute_elo(preferences, k=32, initial_rating=1500):
"""Compute Elo ratings from pairwise preferences."""
ratings = defaultdict(lambda: initial_rating)
for pref in preferences:
agent_a = pref["chosen"]["agent"]
agent_b = pref["rejected"]["agent"]
ra = ratings[agent_a]
rb = ratings[agent_b]
# Expected scores
ea = 1.0 / (1.0 + math.pow(10, (rb - ra) / 400))
eb = 1.0 / (1.0 + math.pow(10, (ra - rb) / 400))
overall = pref.get("overall_preference", "A")
if overall == "Tie":
sa, sb = 0.5, 0.5
else:
# "chosen" is the winner
sa, sb = 1.0, 0.0
ratings[agent_a] = ra + k * (sa - ea)
ratings[agent_b] = rb + k * (sb - eb)
return dict(ratings)
with open("training_data/preferences.jsonl") as f:
prefs = [json.loads(line) for line in f]
ratings = compute_elo(prefs)
print("Elo Ratings:")
print("-" * 35)
for agent, rating in sorted(ratings.items(), key=lambda x: -x[1]):
print(f" {agent:<20} {rating:.0f}")차원별 분석
다차원 비교의 경우, 각 에이전트가 어느 차원에서 잘하는지 살펴보십시오:
import json
from collections import defaultdict
with open("training_data/preferences.jsonl") as f:
prefs = [json.loads(line) for line in f]
# Only process multi-dimension annotations
multi_dim = [p for p in prefs if "dimensions" in p]
dim_wins = defaultdict(lambda: defaultdict(lambda: {"A": 0, "B": 0, "Tie": 0}))
for pref in multi_dim:
agent_a = pref["chosen"]["agent"]
agent_b = pref["rejected"]["agent"]
pair_key = f"{agent_a} vs {agent_b}"
for dim_name, dim_data in pref["dimensions"].items():
dim_wins[dim_name][pair_key][dim_data["preference"]] += 1
print("Per-Dimension Win Rates:")
print("=" * 60)
for dim_name, matchups in sorted(dim_wins.items()):
print(f"\n {dim_name.upper()}")
print(f" {'-' * 50}")
for pair, counts in matchups.items():
total = counts["A"] + counts["B"] + counts["Tie"]
a_rate = (counts["A"] + 0.5 * counts["Tie"]) / total * 100
print(f" {pair}: A={a_rate:.0f}% B={100-a_rate:.0f}% "
f"(A:{counts['A']} B:{counts['B']} Tie:{counts['Tie']})")실전에서 통하는 것
모드 고르기
수천 개의 선호를 빠르게 원하거나, 범용 보상 모델, 또는 리더보드 순위를 원할 때 이진 모드가 옳은 선택입니다. 비교당 대략 1~2분을 예상하십시오.
선호 강도가 훈련 파이프라인에 들어갈 때 척도 모드가 제값을 합니다. 마진 가중치를 적용한 DPO는 강한 선호(슬라이더가 극단)와 약한 선호(슬라이더가 중앙 근처) 사이의 차이를 중요하게 봅니다. 비교당 2~3분을 예상하십시오.
에이전트가 어디서 강하고 약한지 알아야 할 때, 차원별 보상 모델을 훈련할 때, 또는 에이전트 개발자에게 상세한 보고서를 빚지고 있을 때 다차원 모드는 추가 시간을 들일 가치가 있습니다. 비교당 4~6분을 예상하십시오.
비교가 몇 개나 필요한가
신뢰할 만한 승률을 얻으려면 에이전트 쌍당 최소 100건의 비교를 모으십시오. 다섯 개 이상의 에이전트에 걸친 Elo 레이팅의 경우, 총 200~300건의 비교면 순위가 안정됩니다. DPO 보상 모델의 경우, 쉬운 작업과 어려운 작업을 두루 아우르는 1,000개 이상의 선호 쌍을 목표로 하십시오.
순서 무작위화하기
항상 randomize_order: true로 설정하십시오. 왼쪽이나 첫 번째 탭에 나타나는 trace를 선호하는 경향인 위치 편향은 인간 평가 연구에서 잘 문서화되어 있습니다. 같은 측만 계속 클릭하는 사람을 잡아내려면 무작위화를 attention_checks.type: "duplicate_reversed" 검사와 함께 쓰십시오.
무승부 다루기
이진 모드에서는 무승부를 허용하되 무승부 비율을 주시하십시오. 30%를 넘어가면 에이전트들이 이진 판단을 내리기에는 너무 가까운 것이므로 척도나 다차원 모드로 옮겨야 합니다. 척도 모드에서 무승부는 그저 중앙점입니다. 다차원 모드에서 개별 차원의 무승부는 예상되는 일이며 당신에게 무언가를 말해 줍니다.
에이전트 정체 숨기기
보여 줄 실질적인 이유가 없는 한 show_agent_identity: false를 유지하십시오. 어노테이터가 어느 에이전트가 trace를 만들었는지 알면, 이미 더 강하리라 기대하는 쪽을 편드는 경향이 있습니다.
모드 조합하기
철저한 평가를 위해서는, 먼저 많은 쌍 풀에 대해 이진 모드를 돌려 전체 순위를 얻은 다음, 더 작고 층화된 부분집합에 대해 다차원 모드를 돌려 진단적 세부 정보를 얻으십시오. 이진 비교는 보상 모델 훈련에 들어가고, 다차원 비교는 에이전트 개선을 어디에 집중할지 알려 줍니다.
이 모드들 뒤에 있는 설정 레퍼런스는 원본 문서를 참고하십시오. 에이전트를 처음부터 끝까지 평가하는 더 폭넓은 안내가 필요하다면 에이전트 평가 가이드에서 시작하십시오.