La codifica qualitativa arriva in Potato: libri dei codici, memo e codici in vivo
Uno sguardo alla modalità QDA, lo spazio di lavoro per l'analisi dei dati qualitativi in arrivo con Potato 2.6: un libro dei codici vivo, codifica in vivo, memo analitici, casi e ricerca full-text su un intero corpus.
Chi ha mai codificato trascrizioni di interviste conosce la storia del software. Gli strumenti seri per l'analisi dei dati qualitativi (QDA), come NVivo, ATLAS.ti, MAXQDA e Dedoose, sono potenti e costosi. Vivono sul desktop, rinchiudono il progetto in un file proprietario e trasformano la collaborazione in una trattativa di licenze. Molti ricercatori finiscono per codificare in un foglio di calcolo, salvo poi perdere il filo a metà strada, perché un foglio di calcolo non ha alcuna idea di che cosa sia un codice.
Potato è nato dall'altra parte della barricata, come strumento di annotazione testuale per dataset di NLP e machine learning. Nel corso delle ultime versioni ha sviluppato i pezzi che servono a un flusso di lavoro qualitativo: span sui passaggi, un libro dei codici condiviso, metriche di accordo. La prossima versione 2.6 li collega in una modalità costruita sul modo in cui i ricercatori qualitativi lavorano davvero.
Questo articolo percorre la modalità QDA: che cosa attiva, come si incastrano i pezzi e che aspetto ha una configurazione. Se cerchi il riferimento, la documentazione della modalità QDA contiene l'elenco completo delle opzioni.
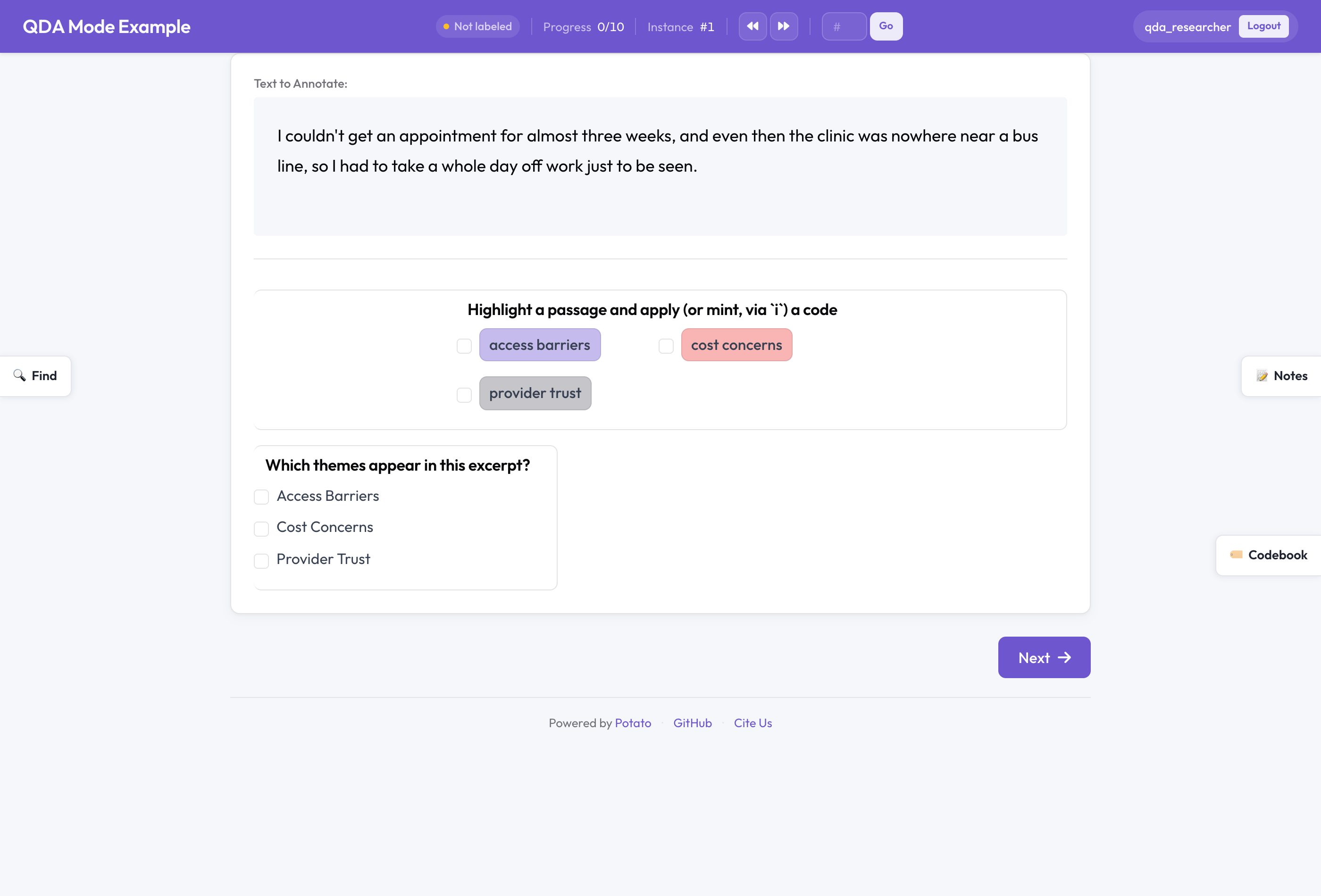 Potato in modalità QDA
Potato in modalità QDA
Un solo interruttore, valori predefiniti qualitativi
La maggior parte del meccanismo di Potato è condivisa tra compiti molto diversi. Lo stesso schema di span che etichetta le entità nominate in un dataset NER può etichettare i passaggi di un'intervista. La differenza tra questi due lavori non è l'insieme delle funzionalità, ma la postura. Un progetto NER in crowdsourcing vuole un insieme fisso di etichette e un campionamento con sovrapposizione per misurare l'accordo. Una ricercatrice che codifica da sola venti interviste vuole inventare i codici mentre legge e conservare note private su ciò che osserva.
La modalità QDA è l'unico interruttore che assume quella seconda postura:
qda_mode:
enabled: true # compose codebook + memos + cases + searchImpostare qda_mode.enabled: true commuta le funzionalità universali di Potato sui loro valori predefiniti qualitativi. Il libro dei codici diventa modificabile mentre codifichi, anziché bloccato. La barra laterale dei memo si attiva. I casi si attivano, con rilevamento automatico. La codifica in vivo diventa disponibile su qualsiasi schema di span che contrassegni come sostenuto dal libro dei codici.
| Funzionalità | Valore predefinito standard | In modalità QDA |
|---|---|---|
| Modalità del libro dei codici | fixed | open: aggiungi, rinomina, ricolora, sposta o elimina codici mentre procedi |
| Barra laterale dei memo | disattivata | attivata |
| Casi | disattivati | attivati, con rilevamento automatico |
| Ricerca-e-rivendicazione per annotatore | disattivata | disponibile (search.annotator_claim: true) |
| Tasto per la codifica in vivo | i | attivo su qualsiasi schema di span sostenuto dal libro dei codici |
Niente di tutto questo è fissato in modo irreversibile. La modalità QDA cambia solo il punto di partenza; ogni valore predefinito può essere sovrascritto. L'unica eccezione è una protezione: se colleghi un backend di crowdsourcing come Prolific o Mechanical Turk, Potato blocca forzatamente il libro dei codici su fixed, così gli annotatori retribuiti non possono rimodellare lo schema condiviso alle tue spalle.
I pezzi
Un libro dei codici vivo
Nella codifica in stile teoria fondata, il libro dei codici non è qualcosa che scrivi in anticipo. Cresce mentre leggi. Noti un'idea ricorrente, le dai un nome e una settimana dopo ti accorgi che due dei tuoi codici sono in realtà lo stesso e li unisci.
Uno schema di span entra a far parte del libro dei codici quando lo contrassegni:
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Quelle labels sono un insieme di partenza, non una gabbia. Nella modalità open del libro dei codici aggiungi, rinomini, ricolori, sposti ed elimini codici mentre lavori. La modalità extensible consente ai codificatori di aggiungere codici ma non di eliminare quelli condivisi; fixed è il classico bloccato, per quando hai definito uno schema.
Codifica in vivo
La codifica in vivo prende le parole stesse del partecipante come codice. Qualcuno dice «semplicemente non riuscivo a farmi richiamare» e «farsi richiamare» diventa il codice, alla lettera.
Seleziona un passaggio su uno schema di span sostenuto dal libro dei codici e premi il tasto in vivo (codebook_invivo_key, predefinito i). Potato conia un codice direttamente dal testo evidenziato. Man mano che lo fai su un intero corpus, la frammentazione diventa il nemico: ti ritrovi con «nessuna richiamata», «non riuscivo a farmi richiamare» e «non mi hanno mai richiamato» come tre codici per un'unica idea. Il compositore di codici contrasta tutto ciò facendo emergere i codici quasi duplicati mentre digiti, così riutilizzi un codice esistente invece di generarne un altro.
Memo
Codificare senza note fa perdere il ragionamento dietro i codici. I memo sono note analitiche allegate a un'istanza o a una specifica selezione di testo. Puoi tenerli privati o condividerli con il team. Sono il luogo in cui vive il «perché ho codificato questo in questo modo», e vengono esportati insieme alle citazioni, così la tua traccia di audit sopravvive al progetto.
Casi
Un caso raggruppa estratti in un'unità di analisi: un partecipante, un documento, un sopralluogo. Una volta raggruppati gli estratti, gli attributi a livello di caso vengono sollevati così da poter tabulare i codici rispetto alle variabili dei partecipanti. Se ogni intervista porta un campo condition, la tabella incrociata di amministrazione può mostrare come un codice si distribuisce tra le condizioni.
cases:
enabled: true
key: participant_id
attributes: [condition]Ricerca
Un corpus è navigabile solo se puoi saltare a qualsiasi occorrenza di una parola. La modalità QDA include la ricerca full-text FTS5 sull'intero dataset. Con annotator_claim: true, un codificatore può tirare qualsiasi corrispondenza della ricerca direttamente nella propria coda: è così che un singolo analista attraversa un corpus per tema invece di leggerlo rigorosamente dall'inizio alla fine.
search:
enabled: true
annotator_claim: trueCome tutto si tiene insieme
Sotto il cofano, libro dei codici, memo, casi e ricerca leggono e scrivono tutti sullo stesso database del progetto, così un codice coniato in un punto diventa immediatamente ricercabile ed esportabile ovunque.
 Come la modalità QDA compone i suoi pezzi su un archivio condiviso
Come la modalità QDA compone i suoi pezzi su un archivio condiviso
Una configurazione completa
Ecco uno studio piccolo ma completo. I blocchi cases, search e memo sono facoltativi (la modalità QDA attiva già casi e memo), quindi li scrivi solo per regolare un valore predefinito come la chiave del caso.
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Eseguila dalla radice del repository una volta installata la 2.6:
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000Riportare fuori la tua codifica
Due esportatori trasformano i dati codificati nei risultati di cui ha bisogno un articolo qualitativo:
codebookrestituisce una riga per codice, con la sua gerarchia, descrizione, colore e conteggio degli utilizzi.quotation_reportrestituisce una riga per ogni span codificato: la citazione, i suoi offset di carattere, l'istanza di origine e il codificatore. Aggiungiinclude_memos=trueper accodare i tuoi memo.
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csvSe più di una persona codifica lo stesso materiale, ti servirà un numero di affidabilità. Potato riporta i kappa di Cohen e di Fleiss sui codici, funzionalità arrivata nella versione 2.5 insieme a questi esportatori.
Dove si colloca
La modalità QDA non cerca di superare NVivo in funzionalità su ogni asse. Quello che offre è uno scambio diverso: gratuita, open source, basata sul web e collaborativa, ospitata nello stesso strumento della tua annotazione per il machine learning e della tua valutazione degli agenti. Se il tuo laboratorio usa già Potato per l'etichettatura, la codifica qualitativa è ora a un blocco di configurazione di distanza, e non più a quella di un software desktop con licenza a parte.
La modalità QDA arriva in Potato 2.6. La documentazione completa copre ogni opzione, e la guida all'accordo tra annotatori spiega le metriche di affidabilità.