Cerrar el ciclo: derivar los errores del agente y los desacuerdos del juez de vuelta a las personas
El tiempo de revisión humana es el recurso más escaso en la evaluación de agentes. Potato 2.6 combina una cola de triaje basada en señales con la alineación juez-humano, para que las peores trazas lleguen primero a las personas y tu juez LLM siga mejorando.
En cuanto evalúas agentes a cualquier escala, la restricción deja de ser "¿podemos etiquetar esto?" y pasa a ser "¿en quién gastamos la atención, y en qué?". Tienes miles de trazas de producción y un puñado de revisores. Un juez LLM puede filtrar todo de antemano, pero es imperfecto, y los casos en los que se equivoca son precisamente los que merecen el tiempo de una persona.
Dos funciones de Potato 2.6 colaboran para gestionar esa escasez. Una cola de triaje basada en señales decide qué ven las personas primero. La alineación juez-humano mide cuánto puedes apoyarte en el juez y lo va mejorando. Ejecútalas juntas y obtienes un ciclo de evaluación activo: el juez se encarga del volumen sencillo, los casos sospechosos se saltan la cola hacia las personas y los desacuerdos retroalimentan un juez mejor.
Esta publicación cubre ambas mitades y cómo se conectan.
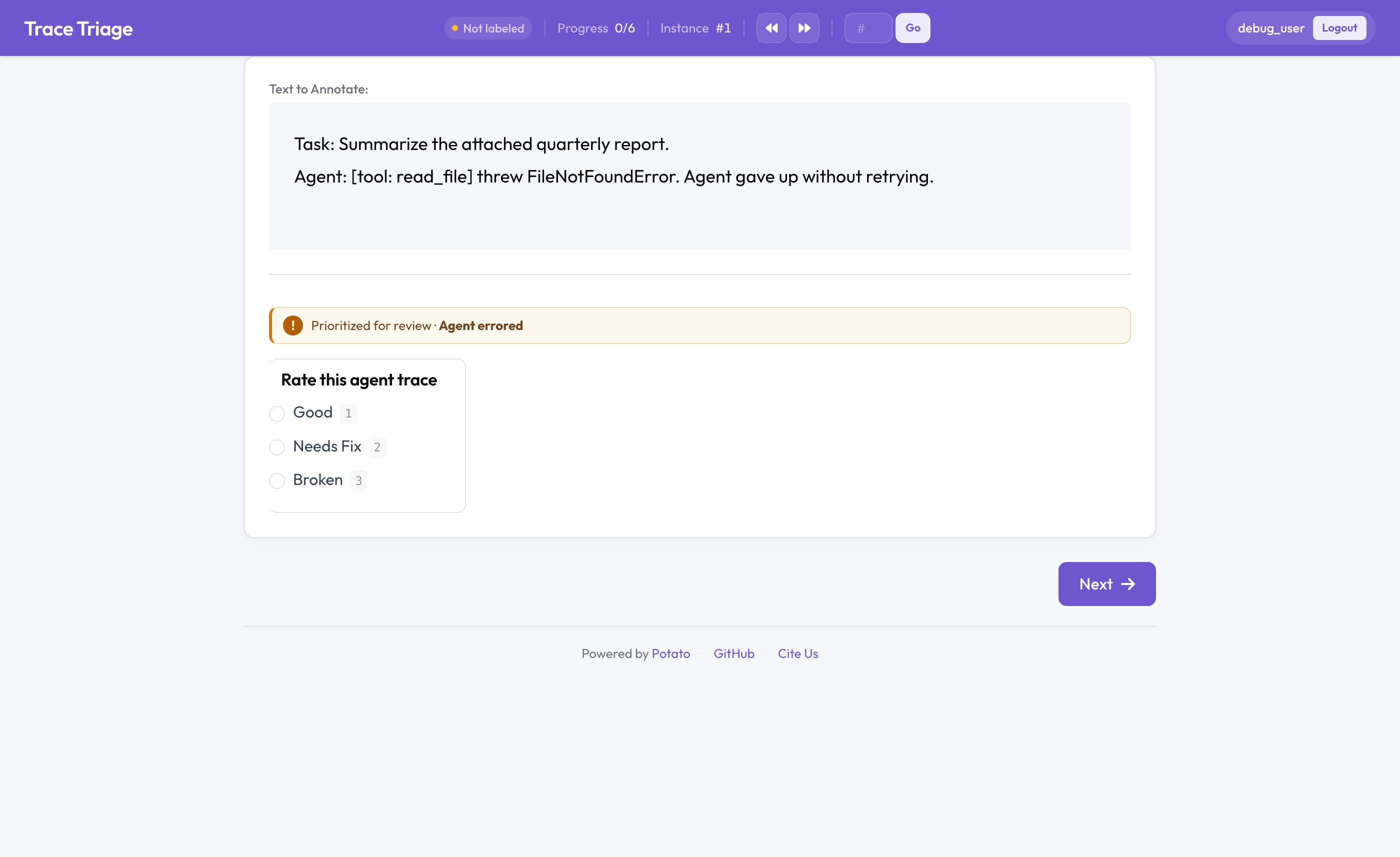 La insignia de la cola de triaje en Potato
La insignia de la cola de triaje en Potato
La mitad del triaje: lo peor primero, no primero en entrar primero en salir
Por defecto, una cola de anotación es FIFO: los elementos se sirven en el orden en que se cargaron. Ese es el orden equivocado cuando el tiempo de revisión es escaso. Una traza limpia y una traza en la que el agente lanzó un error merecen cantidades de atención humana muy distintas, y FIFO las trata igual.
La cola de triaje reordena la cola según una señal de calidad por elemento. La señal puede ser un error del agente, un pulgar abajo en producción, una puntuación automática baja o cualquier campo de tus datos:
triage:
enabled: true
order: desc # high priority first (default)
show_badge: true # banner during annotation explaining the priority
rules: # evaluated in order; highest matching priority wins
- name: "Agent errored"
priority: 100
when:
field: status
equals: error
- name: "Negative feedback"
priority: 80
when:
field: feedback
in: [thumbs_down, negative]
- name: "Low quality score"
priority: 60
when:
field: score
lt: 0.5
assignment_strategy: priorityLas reglas se evalúan de arriba abajo y gana la prioridad coincidente más alta, así que una traza con error que además tiene retroalimentación negativa sigue cayendo en 100. Si omites rules por completo, Potato recurre a un conjunto predeterminado razonable (estado de error en 100, retroalimentación negativa en 80, puntuación inferior a 0.5 en 60), de modo que el comportamiento listo para usar es razonable antes de que ajustes nada.
Los operadores de condición cubren las comparaciones que de verdad necesitas:
| Operator | Significado |
|---|---|
equals | coincidencia exacta (las cadenas no distinguen mayúsculas) |
in | el valor es uno de una lista |
contains | la lista contiene, o coincidencia de subcadena |
lt / lte / gt / gte | comparación numérica |
exists | el campo está presente o ausente |
Cuando la señal ya es un número, puedes leerla directamente del campo en vez de escribir reglas:
triage:
enabled: true
signal_field: quality_score
invert_signal: true # lower score => higher priorityTambién funciona con tráfico en vivo
La puntuación de prioridad se calcula una sola vez cuando un elemento se carga o se ingiere, y luego se almacena en el elemento, así que la asignación sigue siendo barata. Ese mismo diseño hace que la ingesta en tiempo de ejecución simplemente funcione: una traza que entra a mitad de sesión a través del endpoint webhook o un poller de Langfuse se puntúa al llegar y se acomoda en el orden de prioridad. Una traza con poca puntuación o con error que aterriza a las 2 de la tarde se adelanta a las limpias que siguen esperando desde la mañana. Configurar assignment_strategy: priority es lo que hace que la cola sirva realmente en ese orden; show_badge es independiente, así que el banner de "por qué se marcó esto" aparece aunque mantengas otra estrategia.
La mitad de la alineación: cuánto confiar en el juez
El triaje decide qué ven las personas. La alineación decide cuánto del resto puedes entregar al juez sin supervisión, y va afinando al juez con el tiempo.
Judge Alignment ejecuta un juez LLM configurable sobre instancias que tus anotadores ya etiquetaron, y luego informa la κ de Cohen (kappa de Cohen, una medida de concordancia), una matriz de confusión y una lista de desacuerdos frente al gold humano. La práctica estándar (alinear un juez con unas 100–200 etiquetas gold, inspeccionar dónde discrepa, reescribir la rúbrica y volver a ejecutar) es el ciclo en torno al cual está construido esto.
ai_support:
enabled: true
endpoint_type: "ollama"
ai_config:
model: "llama3.2"
temperature: 0.0
judge_alignment:
enabled: true
schemas:
correctness:
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]Ejecutas el juez desde la API de administración, y las predicciones se almacenan en caché por versión de prompt para que las reejecuciones sean baratas:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Cuando quieras calibrar, pasa una rúbrica editada. Eso crea una nueva versión de prompt, así que puedes comparar κ entre rondas y ver de verdad si tu reescritura ayudó:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'El informe, disponible como JSON o como página renderizada en /admin/judge-alignment, muestra κ con una interpretación Landis–Koch, la matriz de confusión, una tabla de desacuerdos con el razonamiento del juez y un historial de versiones de prompt, de modo que el progreso de la calibración sea visible entre rondas.
El modo en línea lo pone frente al anotador
Con inline.enabled, cada página de anotación muestra el veredicto cacheado del juez junto a la etiqueta humana (su elección, su confianza y un razonamiento expandible) junto a una κ en curso para la tarea. "Aceptar" rellena la opción coincidente. Cada guardado humano registra una comparación humano↔juez que alimenta la concordancia en curso, así que la κ hacia la que estás afinando se actualiza a medida que la gente trabaja.
Juntar las dos
Las funciones están diseñadas para componerse en un solo ciclo:
 El ciclo de evaluación activo: triaje, revisión humana, alineación del juez, refinamiento de la rúbrica
El ciclo de evaluación activo: triaje, revisión humana, alineación del juez, refinamiento de la rúbrica
- El triaje empuja las trazas con error y de baja confianza al frente de la cola humana.
- Las personas revisan esos elementos de alto valor, produciendo etiquetas gold frescas justo donde el sistema está menos seguro.
- La alineación puntúa al juez frente a ese gold, y la lista de desacuerdos muestra con precisión dónde se separan el juez y las personas.
- Refinas la rúbrica, vuelves a ejecutar y observas cómo se mueve κ; luego dejas que el juez mejor calibrado absorba más del volumen sencillo, para que el tiempo humano siga fluyendo hacia los casos difíciles.
Cada vuelta del ciclo gasta la atención humana donde más vale y la convierte en un juez en el que puedes confiar un poco más. Ese es justo el punto: no quitar a las personas de la evaluación de agentes, sino apuntarlas.
Ambas funciones se incluyen en Potato 2.6. Consulta los documentos de la cola de triaje y los documentos de alineación del juez para la referencia completa, y la visualización eval_trace para leer rápido las trazas priorizadas.