Announcing Coding Agent Annotation: Evaluate Claude Code, Aider, and SWE-Agent Traces
Potato now supports coding agent annotation with diff rendering, terminal output display, and process reward schemas. Import traces from Claude Code, Aider, and SWE-Agent.
Why Coding Agent Annotation Matters
Coding agents like Claude Code, Aider, and SWE-Agent have gotten good fast, and now people actually need to grade their work. A single run is a messy trajectory: code edits, terminal commands, file reads, and reasoning steps strung together. To train a better agent you need human feedback on those runs, and the annotation tools most teams had were never built for this kind of data.
A plain text annotation interface cannot render a unified diff, format terminal output, or deal with the nested structure of an agent trace. So labs end up writing their own evaluation UIs, redoing the same work and ending up with datasets that do not talk to each other.
Potato now handles coding agent annotation directly, with rendering components built for traces, annotation schemas for this kind of evaluation, and exports that feed straight into training. For the full feature reference, see the coding agent annotation docs and the broader agent evaluation guide.
CodingTraceDisplay: A Trace Viewer
Most of the annotation experience runs through the CodingTraceDisplay component. It renders each step of an agent's trajectory using whatever visualization fits that step type.
Here's what the coding agent annotation interface looks like in Potato:
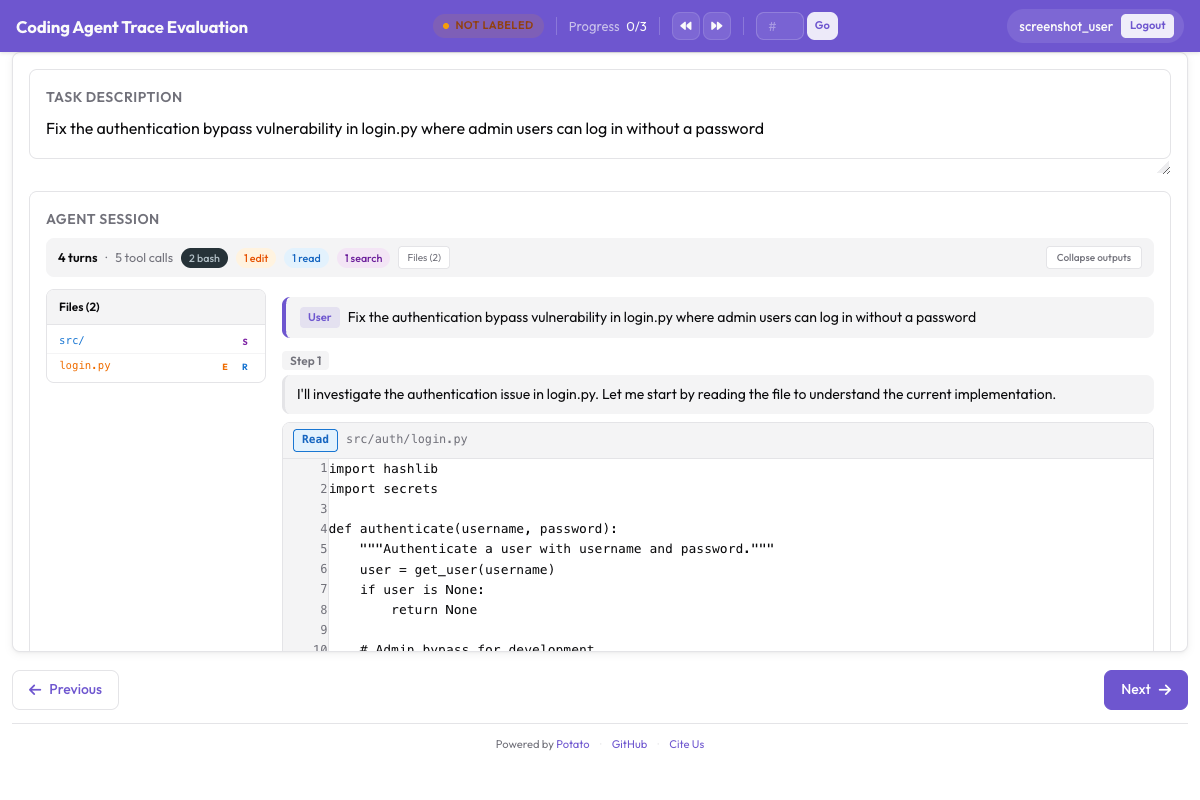 The CodingTraceDisplay renders code diffs, terminal output, and file reads with proper formatting
The CodingTraceDisplay renders code diffs, terminal output, and file reads with proper formatting
Unified Diff View
Code edits are rendered as unified diffs with red/green highlighting for removed and added lines. The diff view includes line numbers, file path headers, and context lines around changes. This mirrors the familiar GitHub pull request experience that most developers already understand.
# The diff rendering is automatic when your trace data includes tool_use
# steps with file edit operations. No special config is needed.
coding_agent:
display:
diff_style: "unified" # "unified" or "split" side-by-side
context_lines: 3 # Lines of context around changes
syntax_highlighting: true # Language-aware highlighting
collapse_large_diffs: true # Auto-collapse diffs > 100 lines
large_diff_threshold: 100Dark Terminal Blocks
Bash commands and their outputs are rendered in dark terminal blocks with monospace font, proper ANSI color support, and scrollable output for long results. The terminal blocks show the command that was executed, the working directory, and the exit code.
coding_agent:
display:
terminal_theme: "dark" # "dark" or "light"
max_terminal_height: 400 # pixels, scrollable beyond this
show_exit_codes: true
show_working_directory: true
ansi_colors: true # Render ANSI escape sequencesLine-Numbered Code Blocks
File read operations are displayed as syntax-highlighted code blocks with line numbers. When the agent reads a specific range of lines, only those lines are shown with their original line numbers preserved, making it easy to cross-reference with the actual file.
File Tree Sidebar
A collapsible sidebar shows all files touched during the trajectory, organized in a tree structure. Each file shows an icon indicating whether it was created, modified, read, or deleted. Clicking a file in the tree scrolls to its first appearance in the trace.
coding_agent:
display:
file_tree:
enabled: true
position: "left" # "left" or "right"
show_change_icons: true # Icons for created/modified/deleted
group_by: "directory" # "directory" or "chronological"Collapsible Outputs
Long outputs from any step type can be collapsed to keep the trace readable. Annotators can expand individual steps as needed, or use "Expand All" / "Collapse All" controls. The thinking/reasoning blocks from agents are collapsed by default but available for review.
coding_agent:
display:
collapsible:
auto_collapse_thinking: true
auto_collapse_long_output: true
long_output_threshold: 50 # lines
default_expanded_types: # These step types start expanded
- "file_edit"
- "bash_command"Process Reward Model (PRM) Schema
Process reward models assign credit at the step level rather than only evaluating the final outcome. Potato supports two PRM annotation modes designed for different speed-accuracy tradeoffs.
First-Error Mode
In first-error mode, the annotator scrolls through the trajectory and clicks on the first step where the agent goes wrong. All steps before the clicked step are automatically marked as correct, and all steps after it (including the clicked step) are automatically marked as incorrect. This dramatically speeds up annotation since the annotator only needs to identify a single point.
annotation_schemes:
- annotation_type: process_reward
name: prm_first_error
mode: "first_error"
labels:
correct: "Correct"
incorrect: "Incorrect"
description: "Click the first step where the agent makes an error"
allow_all_correct: true # Button to mark entire trace as correct
allow_all_incorrect: true # Button to mark entire trace as wrong from step 1
highlight_clicked_step: true
auto_scroll_on_click: truePer-Step Mode
In per-step mode, every step receives an independent rating. This produces more detailed training data but takes longer per trace. Annotators rate each step as correct, incorrect, or partially correct.
annotation_schemes:
- annotation_type: process_reward
name: prm_per_step
mode: "per_step"
labels:
correct:
text: "Correct"
description: "This step is logically sound and makes progress"
keyboard_shortcut: "1"
partially_correct:
text: "Partially Correct"
description: "Right direction but flawed execution"
keyboard_shortcut: "2"
incorrect:
text: "Incorrect"
description: "This step is wrong or counterproductive"
keyboard_shortcut: "3"
require_all_steps: true # Cannot submit until all steps rated
show_progress_bar: trueCode Review Schema
The code review interface provides GitHub PR-style annotation controls:
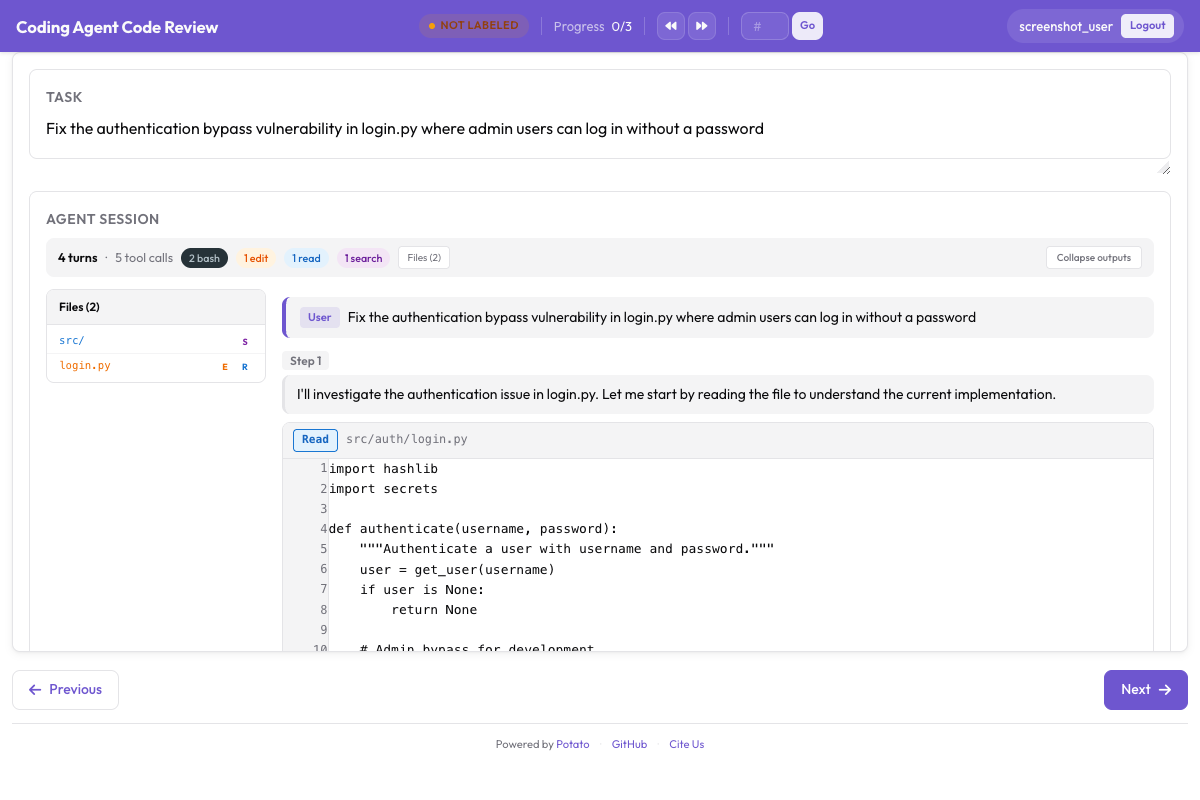 Annotators can click diff lines to add inline comments, rate files, and give approve/reject verdicts
Annotators can click diff lines to add inline comments, rate files, and give approve/reject verdicts
The code review schema brings GitHub PR-style annotation to agent traces. Annotators can leave inline comments on specific lines within diffs, rate individual files, and provide an overall verdict.
annotation_schemes:
- annotation_type: code_review
name: agent_review
inline_comments:
enabled: true
categories: # Optional categorization for comments
- "Bug"
- "Style"
- "Logic Error"
- "Unnecessary Change"
- "Missing Error Handling"
file_ratings:
enabled: true
scale: [1, 2, 3, 4, 5]
labels: ["Poor", "Below Average", "Acceptable", "Good", "Excellent"]
verdict:
enabled: true
options:
- value: "approve"
text: "Approve"
description: "Changes are correct and complete"
- value: "request_changes"
text: "Request Changes"
description: "Changes need fixes before merging"
- value: "comment"
text: "Comment"
description: "General feedback, no strong opinion"
require_comment_on_reject: trueTrace Converters: Import From Any Agent
Potato includes built-in converters for the three most popular coding agent formats. The converters normalize each format into Potato's internal structured trace representation.
Claude Code (Anthropic Messages API)
Claude Code traces use the Anthropic Messages API format with tool_use and tool_result content blocks. The converter extracts file edits, bash commands, and file reads from tool calls and preserves the assistant's reasoning text.
# Convert Claude Code traces to Potato format
potato convert-traces \
--format claude_code \
--input ./claude_traces/ \
--output ./potato_data/traces.jsonlAider (Markdown Chat with Edit Blocks)
Aider produces markdown-formatted chat logs with SEARCH/REPLACE edit blocks. The converter parses these blocks to reconstruct file edits and extracts shell commands from fenced code blocks.
# Convert Aider chat logs
potato convert-traces \
--format aider \
--input ./aider_logs/ \
--output ./potato_data/traces.jsonlSWE-Agent (Thought/Action/Observation)
SWE-Agent uses a thought/action/observation loop format. The converter maps actions to the appropriate step types (edit, bash, read) and preserves the agent's chain-of-thought reasoning as collapsible thinking blocks.
# Convert SWE-Agent trajectories
potato convert-traces \
--format swe_agent \
--input ./swe_agent_trajectories/ \
--output ./potato_data/traces.jsonlAuto-Detection
If you have traces from multiple agents, Potato can auto-detect the format based on the structure of each file:
# Auto-detect format for mixed trace directories
potato convert-traces \
--format auto \
--input ./mixed_traces/ \
--output ./potato_data/traces.jsonlTraining Pipeline Exports
Annotated traces can be exported in formats ready for model training.
PRM Format
Step-level reward labels for training process reward models:
# Exported PRM format (one line per trace)
{
"trace_id": "trace_001",
"steps": [
{"step_idx": 0, "content": "Read file src/main.py", "label": "correct"},
{"step_idx": 1, "content": "Edit src/main.py: fix import", "label": "correct"},
{"step_idx": 2, "content": "Run tests", "label": "correct"},
{"step_idx": 3, "content": "Edit src/utils.py: wrong fix", "label": "incorrect"},
{"step_idx": 4, "content": "Run tests again", "label": "incorrect"}
],
"first_error_step": 3
}DPO/RLHF Preference Pairs
When combined with pairwise comparison annotations, Potato generates preference pairs suitable for Direct Preference Optimization or RLHF training:
# Exported preference pair format
{
"prompt": "Fix the failing test in src/test_utils.py",
"chosen": {"trace_id": "trace_001", "steps": [...]},
"rejected": {"trace_id": "trace_002", "steps": [...]},
"preference_strength": 0.85
}SWE-bench Compatible Results
Export annotations in a format compatible with the SWE-bench evaluation harness for direct comparison with published benchmarks:
# Export to SWE-bench format
potato export \
--format swe_bench \
--project ./my_project/ \
--output ./swe_bench_results.jsonQuick Start
Going from zero to a running annotation server takes about five minutes.
Installation
pip install potato-annotation[coding-agents]Convert Your Traces
# Convert traces from your coding agent
potato convert-traces \
--format auto \
--input ./my_agent_traces/ \
--output ./data/traces.jsonlCreate Your Config
Here is a complete configuration for a coding agent evaluation project that uses both PRM and code review schemas:
# config.yaml
project_name: "Coding Agent Evaluation"
port: 8000
data:
source: "local"
input_path: "./data/traces.jsonl"
data_format: "coding_trace"
coding_agent:
display:
diff_style: "unified"
context_lines: 3
syntax_highlighting: true
collapse_large_diffs: true
terminal_theme: "dark"
max_terminal_height: 400
show_exit_codes: true
file_tree:
enabled: true
position: "left"
show_change_icons: true
collapsible:
auto_collapse_thinking: true
auto_collapse_long_output: true
annotation_schemes:
- annotation_type: process_reward
name: prm_evaluation
mode: "first_error"
labels:
correct: "Correct"
incorrect: "Incorrect"
allow_all_correct: true
description: "Click the first step where the agent makes a mistake"
- annotation_type: code_review
name: code_quality
inline_comments:
enabled: true
categories: ["Bug", "Logic Error", "Style", "Missing Error Handling"]
file_ratings:
enabled: true
scale: [1, 2, 3, 4, 5]
verdict:
enabled: true
options:
- value: "approve"
text: "Approve"
- value: "request_changes"
text: "Request Changes"
- value: "comment"
text: "Comment"
- annotation_type: text_input
name: overall_notes
label: "Additional Notes"
placeholder: "Any other observations about this trace..."
required: false
output:
path: "./output/"
format: "jsonl"
export_formats:
- "prm"
- "swe_bench"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 20
minimum_time_per_instance: 30 # seconds
annotators:
- username: "annotator1"
password: "secure_password_1"
- username: "annotator2"
password: "secure_password_2"Launch the Server
potato start config.yaml -p 8000Open http://localhost:8000 in your browser, log in, and start annotating. You get the full diff rendering, terminal output, and process reward annotation described above.
What Comes Next
This is a first release, and there is more we want to do. On the list: support for more agent formats, better visualization for multi-file refactors, and closer integration with training frameworks like OpenRLHF and TRL.
If you write a new trace converter, schema, or export format, we would love a contribution. And if your team is evaluating coding agents and hits something this setup does not cover, open an issue on our GitHub repository.