Qualitatives Codieren in Potato: Codebücher, Memos und In-vivo-Codes
Ein Blick auf den QDA-Modus, die kommende Arbeitsumgebung für qualitative Datenanalyse in Potato 2.6: ein lebendiges Codebuch, In-vivo-Codierung, analytische Memos, Fälle und Volltextsuche über ein ganzes Korpus.
Wer schon einmal Interviewtranskripte codiert hat, kennt die Software-Geschichte. Die ernsthaften Werkzeuge für die qualitative Datenanalyse (QDA), etwa NVivo, ATLAS.ti, MAXQDA und Dedoose, sind leistungsfähig und teuer. Sie laufen auf dem Desktop, sperren das Projekt in ein proprietäres Dateiformat und machen aus Zusammenarbeit eine Lizenzverhandlung. Viele Forschende codieren am Ende doch in einer Tabellenkalkulation und verlieren auf halbem Weg den Faden, weil eine Tabelle keine Vorstellung davon hat, was ein Code ist.
Potato begann auf der anderen Seite des Zauns, als Textannotationswerkzeug für NLP- und Machine-Learning-Datensätze. Über die letzten Versionen hinweg wuchsen ihm die Bausteine zu, die ein qualitativer Workflow braucht: Spans über Passagen, ein gemeinsames Codebuch, Übereinstimmungsmaße. Die kommende Version 2.6 verknüpft sie zu einem Modus, der auf die tatsächliche Arbeitsweise qualitativ Forschender zugeschnitten ist.
Dieser Beitrag führt durch den QDA-Modus: was er einschaltet, wie die Bausteine zusammenpassen und wie eine Konfiguration aussieht. Wer die Referenz sucht, findet in der Dokumentation zum QDA-Modus die vollständige Optionsliste.
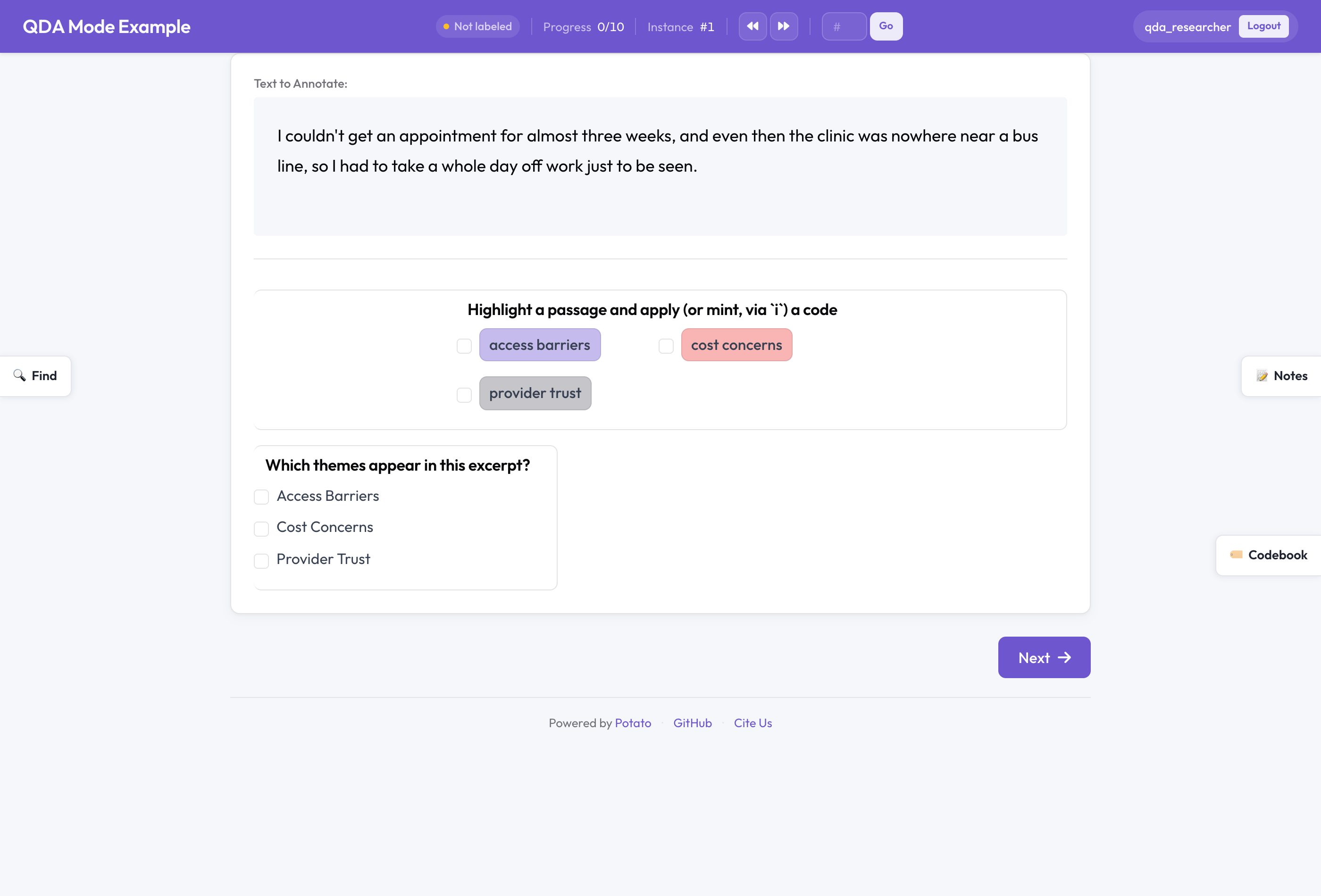 Potato im QDA-Modus
Potato im QDA-Modus
Ein Schalter, qualitative Standardeinstellungen
Der Großteil von Potatos Maschinerie ist über sehr unterschiedliche Aufgaben hinweg geteilt. Dasselbe Span-Schema, das in einem NER-Datensatz Eigennamen kennzeichnet, kann Passagen in einem Interview kennzeichnen. Der Unterschied zwischen diesen beiden Aufgaben liegt nicht im Funktionsumfang, sondern in der Haltung. Ein Crowdsourcing-NER-Projekt will ein festes Labelset und Überlappungs-Sampling, um die Übereinstimmung zu messen. Eine Forscherin, die allein zwanzig Interviews codiert, will Codes im Lesen erfinden und private Notizen zu ihren Beobachtungen führen.
Der QDA-Modus ist der eine Schalter, der diese zweite Haltung voraussetzt:
qda_mode:
enabled: true # compose codebook + memos + cases + searchqda_mode.enabled: true zu setzen stellt Potatos universelle Funktionen auf ihre qualitativen Standardwerte um. Das Codebuch wird während des Codierens bearbeitbar, statt gesperrt zu sein. Die Memo-Seitenleiste geht an. Fälle gehen an, mit automatischer Erkennung. In-vivo-Codierung wird auf jedem Span-Schema verfügbar, das Sie als codebuchgestützt markieren.
| Funktion | Standardvorgabe | Im QDA-Modus |
|---|---|---|
| Codebuch-Modus | fixed | open: Codes laufend hinzufügen, umbenennen, umfärben, verschieben oder löschen |
| Memo-Seitenleiste | aus | an |
| Fälle | aus | an, mit automatischer Erkennung |
| Annotator-Suche-und-Beanspruchung | aus | verfügbar (search.annotator_claim: true) |
| Taste für In-vivo-Codierung | i | aktiv auf jedem codebuchgestützten Span-Schema |
Nichts davon ist festgezurrt. Der QDA-Modus ändert nur den Ausgangspunkt; jede Vorgabe lässt sich überschreiben. Die einzige Ausnahme ist eine Leitplanke: Wenn Sie ein Crowdsourcing-Backend wie Prolific oder Mechanical Turk anhängen, sperrt Potato das Codebuch zwangsweise auf fixed, damit bezahlte Annotatoren das gemeinsame Schema nicht hinter Ihrem Rücken umbauen können.
Die Bausteine
Ein lebendiges Codebuch
Beim Codieren im Stil der Grounded Theory ist das Codebuch nichts, was Sie vorab schreiben. Es wächst beim Lesen. Sie bemerken eine wiederkehrende Idee, benennen sie, und eine Woche später merken Sie, dass zwei Ihrer Codes eigentlich derselbe sind, und führen sie zusammen.
Ein Span-Schema wird Teil des Codebuchs, wenn Sie es markieren:
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Diese labels sind ein Anfangssatz, kein Käfig. Im Codebuch-Modus open fügen Sie Codes während der Arbeit hinzu, benennen sie um, färben sie um, verschieben und löschen sie. Der Modus extensible lässt Codierende Codes hinzufügen, aber gemeinsame nicht löschen; fixed ist der abgeschlossene Klassiker, für den Fall, dass Sie sich auf ein Schema festgelegt haben.
In-vivo-Codierung
Die In-vivo-Codierung nimmt die eigenen Worte der teilnehmenden Person als Code. Jemand sagt „Ich habe einfach keinen Rückruf bekommen", und „keinen Rückruf bekommen" wird wortwörtlich zum Code.
Wählen Sie eine Passage auf einem codebuchgestützten Span-Schema aus und drücken Sie die In-vivo-Taste (codebook_invivo_key, Standard i). Potato prägt direkt aus dem markierten Text einen Code. Tun Sie das über ein ganzes Korpus hinweg, wird Zersplitterung zum Feind: Sie enden mit „kein Rückruf", „keinen Rückruf bekommen" und „nie zurückgerufen" als drei Codes für eine einzige Idee. Der Code-Komponist wirkt dem entgegen, indem er beim Tippen nahezu identische Codes einblendet, damit Sie einen vorhandenen Code wiederverwenden, statt einen weiteren zu erzeugen.
Memos
Codieren ohne Notizen verliert die Begründung hinter den Codes. Memos sind analytische Notizen, die an eine Instanz oder an eine bestimmte Textauswahl geheftet sind. Sie können sie privat halten oder mit dem Team teilen. Hier wohnt das „Warum habe ich das so codiert", und sie werden zusammen mit den Zitaten exportiert, damit Ihre Prüfspur das Projekt überdauert.
Fälle
Ein Fall gruppiert Auszüge zu einer Analyseeinheit: eine teilnehmende Person, ein Dokument, ein Vor-Ort-Besuch. Sind die Auszüge gruppiert, werden Attribute auf Fallebene hochgezogen, sodass Sie Codes gegen Teilnehmervariablen tabellieren können. Trägt jedes Interview ein condition-Feld, kann die Admin-Kreuztabelle zeigen, wie sich ein Code über die Bedingungen verteilt.
cases:
enabled: true
key: participant_id
attributes: [condition]Suche
Ein Korpus ist nur navigierbar, wenn Sie zu jeder Erwähnung eines Wortes springen können. Der QDA-Modus enthält FTS5-Volltextsuche über den gesamten Datensatz. Mit annotator_claim: true kann ein Codierender jeden Suchtreffer direkt in die eigene Warteschlange ziehen — so bewegt sich eine einzelne analysierende Person nach Thema durch ein Korpus, statt es strikt von vorn bis hinten zu lesen.
search:
enabled: true
annotator_claim: trueWie alles zusammenspielt
Unter der Haube lesen und schreiben Codebuch, Memos, Fälle und Suche alle dieselbe Projektdatenbank, sodass ein an einer Stelle geprägter Code überall sonst sofort durchsuchbar und exportierbar ist.
 Wie der QDA-Modus seine Bausteine über einem gemeinsamen Speicher zusammensetzt
Wie der QDA-Modus seine Bausteine über einem gemeinsamen Speicher zusammensetzt
Eine vollständige Konfiguration
Hier ist eine kleine, aber vollständige Studie. Die Blöcke cases, search und Memo sind optional (der QDA-Modus schaltet Fälle und Memos bereits ein), Sie schreiben sie also nur, um eine Vorgabe wie den Fallschlüssel zu justieren.
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Führen Sie sie nach der Installation von 2.6 aus dem Repository-Stamm aus:
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000Ihre Codierung wieder herausholen
Zwei Exporter verwandeln codierte Daten in die Ergebnisse, die ein qualitatives Paper braucht:
codebookliefert eine Zeile pro Code, mit Hierarchie, Beschreibung, Farbe und Verwendungszahl.quotation_reportliefert eine Zeile pro codiertem Span: das Zitat, seine Zeichen-Offsets, die Quellinstanz und die codierende Person. Mitinclude_memos=truewerden Ihre Memos angehängt.
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csvCodieren mehrere Personen dasselbe Material, brauchen Sie eine Reliabilitätszahl. Potato berichtet Cohens und Fleiss' Kappa über die Codes, was in Version 2.5 zusammen mit diesen Exportern kam.
Wo das hingehört
Der QDA-Modus versucht nicht, NVivo auf jeder Achse funktional zu übertreffen. Was er bietet, ist ein anderer Tausch: kostenlos, quelloffen, webbasiert und kollaborativ, untergebracht im selben Werkzeug wie Ihre Machine-Learning-Annotation und Ihre Agent-Evaluierung. Wenn Ihr Labor Potato ohnehin zum Labeln betreibt, ist qualitatives Codieren jetzt nur noch einen Konfigurationsblock entfernt statt eine separate, lizenzierte Desktop-Software.
Der QDA-Modus erscheint in Potato 2.6. Die vollständige Dokumentation deckt jede Option ab, und der Leitfaden zur Interrater-Übereinstimmung erläutert die Reliabilitätsmaße.