GitHub PR-Style Code Review for AI Coding Agents
Set up GitHub PR-style code review annotation in Potato with inline diff comments, file-level quality ratings, and approve or reject verdicts for coding agent output.
Why Code Review Annotation Matters
Most coding agent benchmarks reduce evaluation to a binary: did the tests pass or not? SWE-bench reports a percentage of resolved issues. HumanEval reports pass@k. These metrics are useful for leaderboards but useless for understanding code quality.
An agent can pass every test and still write code that nobody would want to maintain, code with a security hole, a slow path, or a style that fights the rest of the codebase. A human reviewer would request changes on that PR even though the tests are green. If you want agents that write code people actually merge, you have to review the code, not just run the tests.
Potato's code_review annotation schema brings the GitHub PR review experience into an annotation tool. Annotators see unified diffs with syntax highlighting, click on diff lines to add inline comments, rate files on a couple of quality dimensions, and give an approve, request-changes, or comment verdict, the same as reviewing a real pull request. For the full schema reference, see the coding agent annotation docs and the agent evaluation guide.
Here's the code review interface in Potato, showing inline diff comments and file-level ratings:
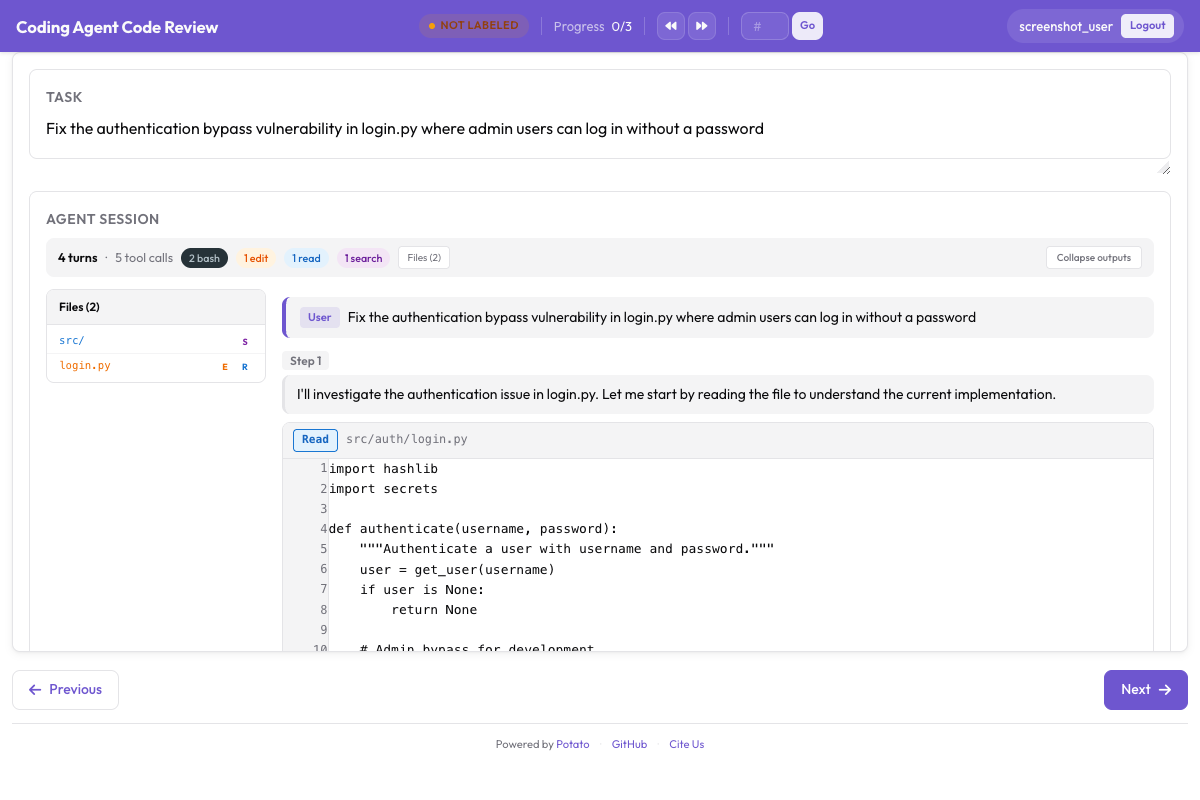 Potato's code review interface with inline diff comments and file-level quality ratings
Potato's code review interface with inline diff comments and file-level quality ratings
Code Review Schema Overview
The code_review schema has three layers:
- Inline diff comments: Annotators click on any line in the diff to attach a categorized comment (bug, style, performance, security, logic, suggestion, question)
- File-level ratings: Each modified file gets independent ratings for correctness (1-5) and code quality (1-5)
- Overall verdict: The annotator renders a final verdict: approve, request changes, or comment only
This mirrors a real code review, so it feels natural to developers, and the structured output it produces maps directly onto code review model training.
CodingTraceDisplay: How Diffs Are Rendered
The CodingTraceDisplay component renders coding agent traces as a sequence of tool calls and their outputs, with special handling for file edits. When the agent edits a file, the display shows a unified diff with:
- Red lines: Deleted lines (prefixed with
-) - Green lines: Added lines (prefixed with
+) - Gray lines: Context lines (unchanged)
- Line numbers: Both old and new line numbers in the gutter
- Syntax highlighting: Language-aware highlighting based on file extension
- Click-to-comment: Clicking any line opens a comment form anchored to that line
The diff is computed automatically from the agent's edit operations. If the agent used a search-and-replace tool, Potato reconstructs the before/after states and generates the unified diff.
For agents that produce multiple file edits in a single trace (common for real-world bug fixes), each file gets its own collapsible diff section, similar to the GitHub PR "Files changed" tab.
The CodingTraceDisplay renders code changes with proper syntax highlighting:
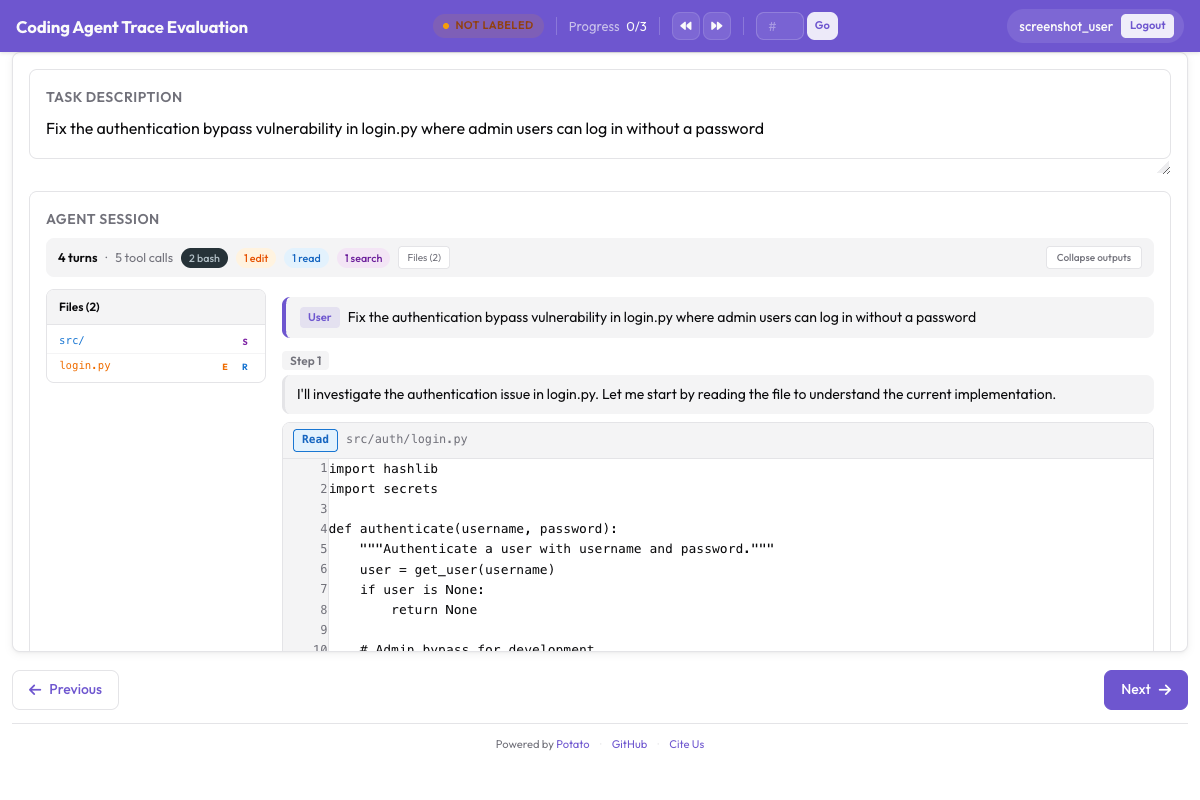 CodingTraceDisplay rendering unified diffs with syntax highlighting and a file tree sidebar
CodingTraceDisplay rendering unified diffs with syntax highlighting and a file tree sidebar
Comment Categories
When an annotator clicks a diff line to add a comment, they select a category:
| Category | Color | Description | Example |
|---|---|---|---|
bug | Red | The code has a functional error | "This will throw a NullPointerException if user is None" |
style | Blue | Code style or convention issue | "Project uses snake_case for functions, not camelCase" |
performance | Orange | Inefficient code | "This queries the database inside a loop; use a batch query" |
security | Purple | Security vulnerability | "User input is passed directly to SQL query without sanitization" |
logic | Yellow | Logic issue that may not cause immediate failure | "This condition should be >= not >, off-by-one on boundary" |
suggestion | Green | Improvement suggestion, not an error | "Consider using a context manager here for cleaner resource handling" |
question | Gray | Clarification needed | "Why was this import added? It does not appear to be used" |
Each comment also has a free-text body where the annotator explains the issue in detail, just like writing a real PR comment.
File-Level Ratings
After reviewing the diff for each file, the annotator rates it on two dimensions:
Correctness (1-5):
- 1: Does not work, introduces new bugs
- 2: Partially works, has significant issues
- 3: Works for the happy path but misses edge cases
- 4: Works correctly with minor issues
- 5: Fully correct, handles edge cases appropriately
Code Quality (1-5):
- 1: Unmaintainable, no structure
- 2: Poor quality, significant style/design issues
- 3: Acceptable, follows basic conventions
- 4: Good quality, clean and readable
- 5: Excellent, idiomatic, well-documented
Verdict Options
After reviewing all files, the annotator selects one of three verdicts:
- Approve: The code is ready to merge as-is, or with only trivial changes
- Request Changes: The code needs significant revisions before merging
- Comment Only: Providing feedback without making a merge decision
This maps directly to GitHub's three PR review states.
Step-by-Step Setup
Step 1: Convert Coding Agent Traces
Coding agent traces come in many formats. Here are examples for three popular agents.
From Claude Code (JSON export):
python -m potato.convert_traces \
--input claude_code_sessions/ \
--output data/code_traces.jsonl \
--format claude_codeFrom Aider (chat history):
python -m potato.convert_traces \
--input aider_logs/ \
--output data/code_traces.jsonl \
--format aiderFrom SWE-Agent (trajectories directory):
python -m potato.convert_traces \
--input swe_agent_trajectories/ \
--output data/code_traces.jsonl \
--format swe_agentThe converter produces a standardized JSONL format. Each line contains a trace with the task, the agent's steps, and the file diffs:
{
"trace_id": "swe_bench_123",
"task": "Fix the TypeError in django/db/models/query.py when calling .values() on an empty QuerySet",
"repo": "django/django",
"base_commit": "a1b2c3d",
"steps": [
{
"type": "thought",
"content": "Let me look at the QuerySet.values() method to understand the TypeError."
},
{
"type": "action",
"tool": "search",
"input": "def values",
"file": "django/db/models/query.py"
},
{
"type": "observation",
"content": "Found at line 234: def values(self, *fields):\n ..."
},
{
"type": "action",
"tool": "edit",
"file": "django/db/models/query.py",
"old_content": " def values(self, *fields):\n clone = self._clone()\n clone.query.set_values(fields)",
"new_content": " def values(self, *fields):\n clone = self._clone()\n if not fields and not self.query.values_select:\n return clone\n clone.query.set_values(fields)"
},
{
"type": "action",
"tool": "edit",
"file": "tests/queries/test_values.py",
"old_content": "class ValuesTests(TestCase):",
"new_content": "class ValuesTests(TestCase):\n def test_empty_queryset_values(self):\n \"\"\"Calling .values() on empty QuerySet should not raise TypeError.\"\"\"\n qs = Author.objects.none()\n result = list(qs.values())\n self.assertEqual(result, [])"
}
],
"files_changed": [
{
"path": "django/db/models/query.py",
"diff": "--- a/django/db/models/query.py\n+++ b/django/db/models/query.py\n@@ -234,6 +234,8 @@\n def values(self, *fields):\n clone = self._clone()\n+ if not fields and not self.query.values_select:\n+ return clone\n clone.query.set_values(fields)"
},
{
"path": "tests/queries/test_values.py",
"diff": "--- a/tests/queries/test_values.py\n+++ b/tests/queries/test_values.py\n@@ -1,4 +1,10 @@\n class ValuesTests(TestCase):\n+ def test_empty_queryset_values(self):\n+ \"\"\"Calling .values() on empty QuerySet should not raise TypeError.\"\"\"\n+ qs = Author.objects.none()\n+ result = list(qs.values())\n+ self.assertEqual(result, [])"
}
]
}Step 2: Configure the Code Review Schema
Create your config.yaml:
annotation_task_name: "Coding Agent Code Review"
data_files:
- "data/code_traces.jsonl"
item_properties:
id_key: "trace_id"
text_key: "task"
# Display coding agent traces with diff rendering
display:
type: "coding_trace"
trace_key: "steps"
diff_key: "files_changed"
syntax_highlighting: true
show_line_numbers: true
collapse_large_diffs: true
max_uncollapsed_lines: 200
annotation_schemes:
- annotation_type: "code_review"
name: "review"
description: "Review the agent's code changes as you would a GitHub PR"
# Inline comment categories
comment_categories:
- name: "bug"
label: "Bug"
color: "#DC2626"
description: "Functional error in the code"
- name: "style"
label: "Style"
color: "#2563EB"
description: "Code style or convention issue"
- name: "performance"
label: "Performance"
color: "#EA580C"
description: "Inefficient code or unnecessary computation"
- name: "security"
label: "Security"
color: "#9333EA"
description: "Security vulnerability or unsafe practice"
- name: "logic"
label: "Logic"
color: "#CA8A04"
description: "Logic issue that may not cause immediate failure"
- name: "suggestion"
label: "Suggestion"
color: "#16A34A"
description: "Improvement idea, not an error"
- name: "question"
label: "Question"
color: "#6B7280"
description: "Clarification needed"
# File-level ratings
file_ratings:
- name: "correctness"
label: "Correctness"
scale: 5
descriptions:
1: "Does not work, introduces new bugs"
2: "Partially works, has significant issues"
3: "Works for happy path, misses edge cases"
4: "Works correctly with minor issues"
5: "Fully correct, handles edge cases"
- name: "code_quality"
label: "Code Quality"
scale: 5
descriptions:
1: "Unmaintainable, no structure"
2: "Poor quality, significant style issues"
3: "Acceptable, follows basic conventions"
4: "Good quality, clean and readable"
5: "Excellent, idiomatic, well-documented"
# Overall verdict
verdict:
options:
- name: "approve"
label: "Approve"
color: "#16A34A"
description: "Ready to merge as-is or with trivial changes"
- name: "request_changes"
label: "Request Changes"
color: "#DC2626"
description: "Needs significant revisions before merging"
- name: "comment"
label: "Comment Only"
color: "#6B7280"
description: "Providing feedback without a merge decision"
# Annotator settings
annotator_config:
allow_back_navigation: true
# Output settings
output:
path: "output/"
format: "jsonl"Step 3: Launch the Annotation Server
potato start config.yaml -p 8000Navigate to http://localhost:8000. You will see the first coding agent trace with the task description, the agent's reasoning steps, and the file diffs rendered with syntax highlighting.
Step 4: The Annotator Workflow
Here is the typical review flow:
- Read the task: Understand what the agent was asked to do (e.g., "Fix the TypeError in django/db/models/query.py")
- Review the trace: Scroll through the agent's reasoning steps to understand its approach
- Review each file diff:
- Read through the diff with syntax highlighting
- Click on any line to add an inline comment
- Select a comment category (bug, style, performance, etc.)
- Write the comment body explaining the issue
- Rate the file on correctness (1-5) and code quality (1-5)
- Render verdict: Select approve, request changes, or comment only
- Submit: Click "Submit" or press Ctrl+Enter
Keyboard shortcuts speed up the workflow:
| Shortcut | Action |
|---|---|
j / k | Navigate between files |
c | Open comment on selected line |
1-5 | Set rating for current dimension |
a | Set verdict to approve |
r | Set verdict to request changes |
Ctrl+Enter | Submit review |
Export Format
Each submitted review produces a structured JSON object:
{
"trace_id": "swe_bench_123",
"annotator": "reviewer_01",
"timestamp": "2026-03-22T14:32:11Z",
"review": {
"inline_comments": [
{
"file": "django/db/models/query.py",
"line": 236,
"side": "right",
"category": "logic",
"body": "This early return skips set_values entirely, but if fields are provided later via .values('name'), the previous empty .values() call will have returned a clone that never went through set_values. Consider checking if this clone is still valid downstream."
},
{
"file": "tests/queries/test_values.py",
"line": 5,
"side": "right",
"category": "suggestion",
"body": "Consider adding a test case for .values() followed by .values('name') to verify the chaining behavior after your fix."
}
],
"file_ratings": [
{
"file": "django/db/models/query.py",
"correctness": 3,
"code_quality": 4
},
{
"file": "tests/queries/test_values.py",
"correctness": 4,
"code_quality": 4
}
],
"verdict": "request_changes"
}
}This structured format is directly usable for training code review models and for aggregate analysis.
Analysis: Working with Review Data
Loading Reviews
import json
import pandas as pd
from pathlib import Path
reviews = []
for f in Path("output/").glob("*.jsonl"):
with open(f) as fh:
for line in fh:
reviews.append(json.loads(line))
print(f"Loaded {len(reviews)} code reviews")Comment Category Distribution
from collections import Counter
all_comments = []
for rev in reviews:
for comment in rev["review"]["inline_comments"]:
all_comments.append(comment)
category_counts = Counter(c["category"] for c in all_comments)
print("Comment categories:")
for cat, count in category_counts.most_common():
print(f" {cat}: {count}")Average File Ratings
ratings = []
for rev in reviews:
for fr in rev["review"]["file_ratings"]:
ratings.append(fr)
ratings_df = pd.DataFrame(ratings)
print("Average ratings by file:")
print(
ratings_df.groupby("file")[["correctness", "code_quality"]]
.mean()
.round(2)
.to_string()
)Verdict Distribution
verdict_counts = Counter(rev["review"]["verdict"] for rev in reviews)
total = sum(verdict_counts.values())
print("Verdict distribution:")
for verdict, count in verdict_counts.most_common():
print(f" {verdict}: {count} ({count/total*100:.1f}%)")Bug Rate by Agent
If your traces include an agent field, you can compare bug rates across agents:
agent_bugs = {}
for rev in reviews:
agent = rev.get("agent", "unknown")
bug_count = sum(
1 for c in rev["review"]["inline_comments"]
if c["category"] == "bug"
)
if agent not in agent_bugs:
agent_bugs[agent] = []
agent_bugs[agent].append(bug_count)
print("Average bugs per review by agent:")
for agent, bugs in sorted(agent_bugs.items()):
print(f" {agent}: {sum(bugs)/len(bugs):.2f} (n={len(bugs)})")Use Cases
Training Code Review Models
The structured inline comments, file ratings, and verdicts from Potato's code review annotation are ideal training data for automated code review models. Each review provides:
- Localized feedback tied to specific diff lines
- Categorized issues (bug vs. style vs. performance)
- Quality signals at multiple granularities (line, file, overall)
This is the data format used by tools like CodeRabbit and Graphite's AI reviewer, but generated from human experts rather than distilled from an LLM.
Evaluating Coding Agents on SWE-bench
SWE-bench tells you if the agent resolved the issue (tests pass), but not if the code is mergeable. By running code review annotation on SWE-bench solutions, you can identify agents that solve issues with clean code versus agents that solve issues with hacks. This produces a more nuanced leaderboard that correlates with real-world developer experience.
Building Code Quality Datasets
Aggregate code review data across many traces to build datasets of common code quality issues in AI-generated code. These datasets can be used for:
- Fine-tuning code generation models to avoid common mistakes
- Building linters specific to AI-generated code patterns
- Training classifiers that flag likely issues in agent output before human review
Summary
Potato's code_review schema puts the GitHub PR review workflow inside agent evaluation. The inline comments, file ratings, and verdicts you collect give you structured code quality data, which is a lot more than a pass/fail test result tells you. That data is what you need whether you are training a code review model, separating clean SWE-bench solutions from hacky ones, or just establishing a quality baseline for your agent.