De la evaluación a los datos de entrenamiento: edición de trayectorias para SFT y DPO
La mayoría de las evaluaciones de agentes se detienen en una puntuación. El esquema trajectory_edit de Potato 2.6 permite a los anotadores reescribir un paso equivocado en lugar de calificarlo, y exporta cada corrección como objetivos de ajuste fino supervisado y pares de preferencia para DPO.
La evaluación de agentes suele terminar con un número. Un anotador lee una trayectoria, decide que el tercer paso estaba mal y registra una puntuación baja o etiqueta un tipo de error. Ese número sirve para medir con qué frecuencia falla el agente. Es mucho menos útil para corregir al agente, porque "el tercer paso estaba mal" no le dice al modelo cuál debería haber sido el tercer paso.
La próxima versión Potato 2.6 añade un esquema que pide la respuesta en lugar de la calificación. Con trajectory_edit, los anotadores reescriben los pasos de un agent trace (traza de agente): corrigen un paso de razonamiento fallido, reparan una tool call (llamada a herramienta) con un error tipográfico o refuerzan una respuesta final débil, y Potato conserva la trayectoria corregida junto a la original. A continuación, el exportador trajectory_correction convierte cada par (original, corrected) en datos de entrenamiento: objetivos de ajuste fino supervisado y pares de preferencia de optimización directa de preferencias.
De eso trata esta entrada. Convierte una herramienta de evaluación en una herramienta de producción de datos de entrenamiento, y cambia lo que produce el tiempo de un anotador humano: no una etiqueta, sino una señal de aprendizaje.
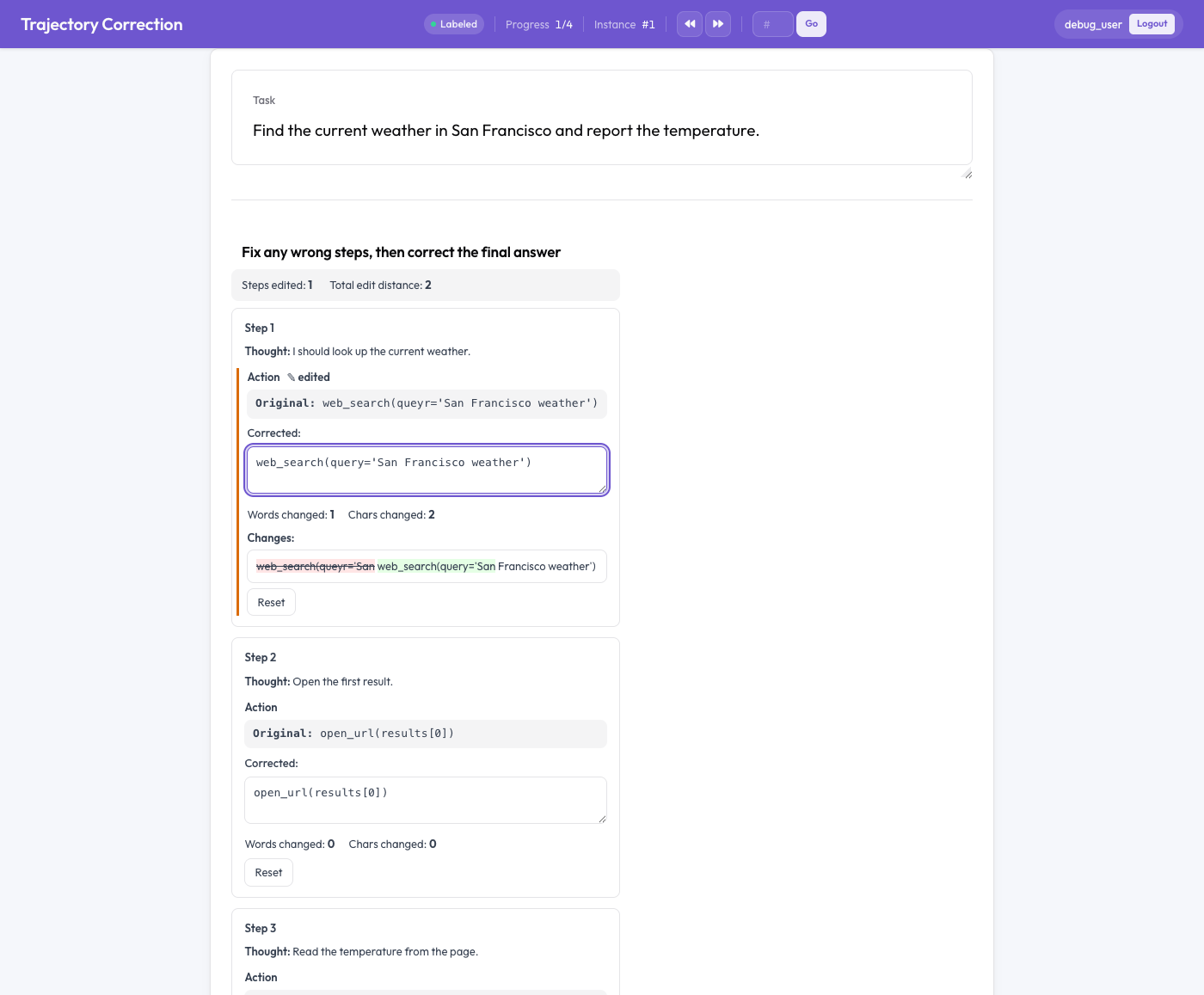 El editor de corrección de trayectorias
El editor de corrección de trayectorias
Editar en lugar de puntuar
Cada paso del agente se muestra como una tarjeta con dos mitades: el texto original, de solo lectura, y un cuadro corregido editable que viene rellenado con el original. El anotador edita el cuadro corregido directamente. A medida que escribe, ocurren tres cosas:
- un diff en vivo a nivel de palabra resalta las inserciones en verde y las eliminaciones en rojo tachado,
- se cuentan las palabras y los caracteres modificados, y
- aparece una marca de "edited" (editado) en cualquier campo que haya cambiado.
Un botón "Reset" restaura el original de un campo si el anotador cambia de opinión. Lo fundamental: nada es obligatorio. Un anotador que lee una traza y la encuentra correcta simplemente la deja como está, y una traza sin editar no produce ningún par de entrenamiento. La señal proviene solo de correcciones reales.
Configuración
El esquema apunta a la lista de pasos de tus datos y nombra qué campos son editables:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerDe forma predeterminada, solo la action de cada paso es editable. Añade thought a editable_fields cuando quieras que los anotadores reparen el razonamiento del agente además de sus acciones, y establece require_reason_on_edit: true cuando quieras que se adjunte una justificación escrita a cada cambio, lo que ayuda cuando las propias correcciones se van a revisar.
El formato de datos es el que ya tienen tus trazas. El esquema lee los pasos del campo indicado por steps_key; cada paso es un objeto cuyos campos pueden editarse:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}El error tipográfico en queyr es exactamente el tipo de cosa que un anotador corrige en el cuadro corregido, lo que produce una corrección de un solo token de la que el modelo puede aprender.
Ejecuta el ejemplo incluido desde la raíz del repositorio:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000De las correcciones a los archivos de entrenamiento
El exportador trajectory_correction escribe tres archivos, cada uno para un uso posterior distinto:
trajectory_corrections.jsoncontiene el registro completo: eloriginal_trace, elcorrected_tracereconstruido y loseditspor campo con distancias de edición y motivos. Este es tu rastro de auditoría.trajectory_sft.jsonltiene una línea por traza editada,{"prompt": <task>, "completion": <corrected_trace>}. La trayectoria corregida se convierte en el objetivo que un modelo aprende a reproducir mediante ajuste fino.trajectory_dpo.jsonltiene una línea por traza editada,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}. La edición del humano define la preferencia: la corregida por encima de la original.
 Cómo las ediciones se convierten en datos de entrenamiento SFT y DPO
Cómo las ediciones se convierten en datos de entrenamiento SFT y DPO
El archivo DPO es la parte que sale gratis. En una canalización de datos de preferencia habitual hay que generar o recopilar una respuesta peor para emparejarla con la mejor. Aquí la respuesta peor ya existe (es la trayectoria original que produjo el agente) y la edición del humano es la prueba de que la versión corregida es la preferida. Una sola anotación produce tanto un objetivo de SFT como un par de DPO.
Qué se omite y por qué importa
Las trazas sin editar se cuentan, pero se excluyen de los archivos SFT y DPO. Entrenar con una trayectoria sin cambios no le enseña nada al modelo y, peor aún, inundaría un conjunto de datos de preferencia con pares chosen == rejected que añaden ruido. El recuento de omitidas sigue apareciendo en las estadísticas de exportación, así que puedes ver qué proporción del lote ya era correcta, lo cual es en sí una señal útil sobre la calidad del agente. Con varios anotadores, cada anotador que editó una traza dada produce un registro SFT/DPO, de modo que todas las correcciones independientes contribuyen.
Un par de aristas
- El diff es a nivel de palabra. En tool calls (llamadas a herramientas) parecidas a código y sin espacios, un solo token puede aparecer como completamente cambiado incluso ante una corrección de un solo carácter. El contador de distancia de caracteres es la señal precisa en esos casos; confía en él por encima del diff visual para llamadas a herramientas densas.
- Editar combina de forma natural con puntuar. Si además quieres etiquetas de corrección por paso o una taxonomía de errores sobre la misma traza, ejecuta un esquema de puntuación a nivel de paso junto al editor, para que una sola pasada produzca tanto el diagnóstico como la corrección.
Por qué importa esto
El bucle de ajuste de agentes siempre ha tenido un cuello de botella en el paso de "qué debería haber hecho". Las puntuaciones te dicen dónde falla un modelo; no producen el comportamiento corregido sobre el que entrenar, así que los equipos acaban escribiendo correcciones sintéticas o pagando por una segunda ronda de etiquetado. La edición de trayectorias colapsa eso dentro de la propia evaluación. La misma persona que habría puntuado la traza la repara en su lugar, y la reparación es el dato de entrenamiento.
La edición de trayectorias llega en Potato 2.6. Consulta la documentación de edición de trayectorias para la lista completa de opciones, la visualización eval_trace para leer trazas con rapidez antes de editar, y la referencia de formatos de exportación para los detalles del exportador.