Codificación cualitativa en Potato: libros de códigos, memos y códigos in vivo
Un vistazo al modo QDA, el espacio de trabajo para análisis de datos cualitativos que llega con Potato 2.6: un libro de códigos vivo, codificación in vivo, memos analíticos, casos y búsqueda de texto completo sobre todo un corpus.
Si alguna vez has codificado transcripciones de entrevistas, conoces la historia del software. Las herramientas serias para el análisis de datos cualitativos (QDA), como NVivo, ATLAS.ti, MAXQDA y Dedoose, son potentes y caras. Viven en el escritorio, encierran tu proyecto en un archivo propietario y convierten la colaboración en una negociación de licencias. Muchos investigadores acaban codificando en una hoja de cálculo y luego pierden el hilo a mitad de camino, porque una hoja de cálculo no tiene ni idea de qué es un código.
Potato nació al otro lado de la valla, como herramienta de anotación de texto para conjuntos de datos de PLN y aprendizaje automático. A lo largo de las últimas versiones fue desarrollando las piezas que necesita un flujo de trabajo cualitativo: tramos (spans) sobre los pasajes, un libro de códigos compartido y métricas de acuerdo. La próxima versión 2.6 las une en un modo construido para la forma en que trabajan realmente los investigadores cualitativos.
Este artículo recorre el modo QDA: qué activa, cómo encajan las piezas y qué aspecto tiene una configuración. Si lo que buscas es la referencia, la documentación del modo QDA contiene la lista completa de opciones.
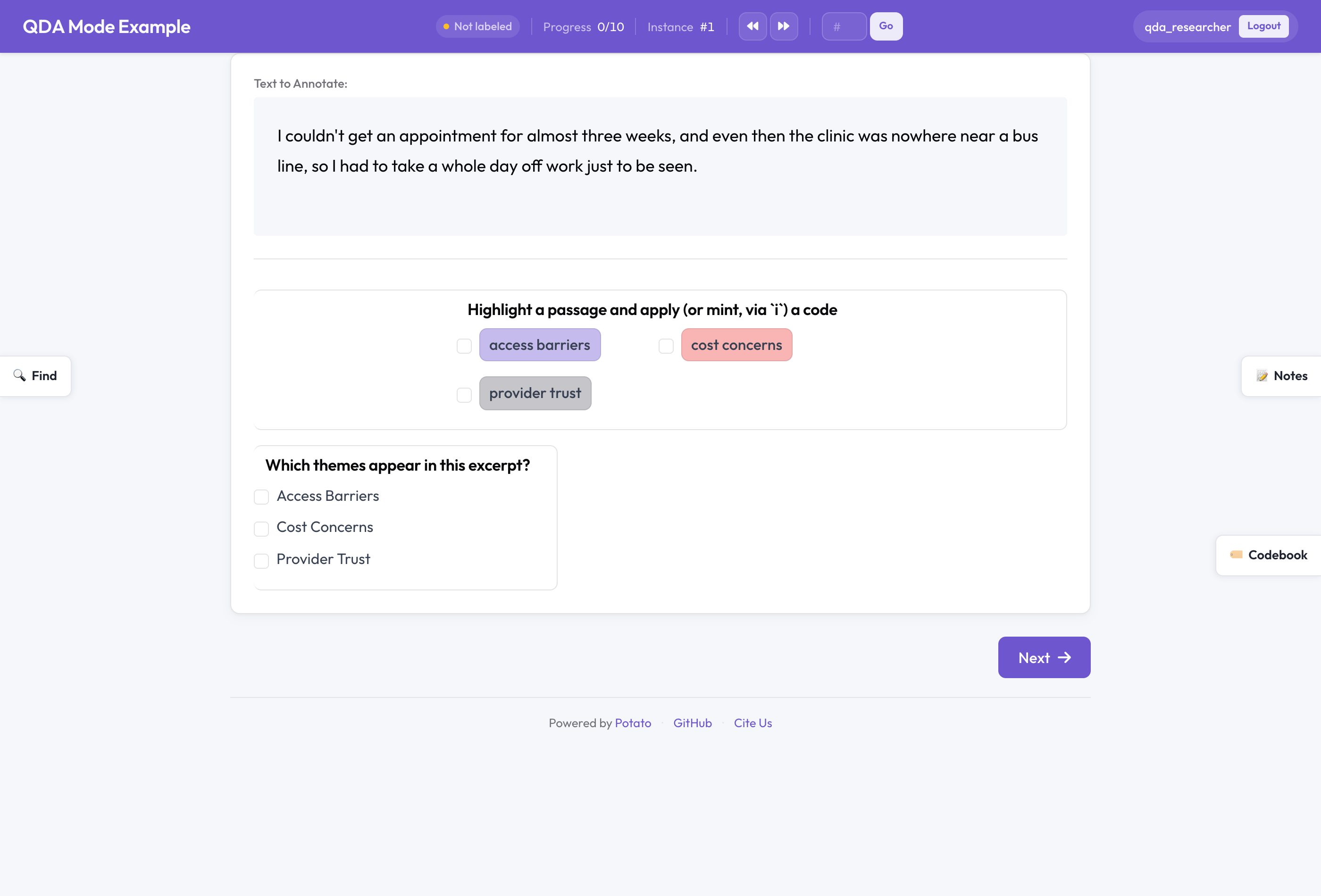 Potato en modo QDA
Potato en modo QDA
Un solo interruptor, valores cualitativos por defecto
La mayor parte de la maquinaria de Potato se comparte entre tareas muy distintas. El mismo esquema de span que etiqueta entidades nombradas para un conjunto de datos de NER puede etiquetar pasajes en una entrevista. La diferencia entre esos dos trabajos no es el conjunto de funciones, sino la postura. Un proyecto de NER por crowdsourcing quiere un conjunto fijo de etiquetas y un muestreo con solapamiento para medir el acuerdo. Una investigadora que codifica sola veinte entrevistas quiere inventar códigos a medida que lee y conservar notas privadas sobre lo que va observando.
El modo QDA es el único interruptor que asume esa segunda postura:
qda_mode:
enabled: true # compose codebook + memos + cases + searchEstablecer qda_mode.enabled: true cambia las funciones universales de Potato a sus valores cualitativos por defecto. El libro de códigos pasa a ser editable mientras codificas, en lugar de quedar bloqueado. Se activa la barra lateral de memos. Se activan los casos, con detección automática. La codificación in vivo queda disponible en cualquier esquema de span que marques como respaldado por libro de códigos.
| Función | Valor por defecto estándar | En modo QDA |
|---|---|---|
| Modo del libro de códigos | fixed | open: añade, renombra, recolorea, mueve o elimina códigos sobre la marcha |
| Barra lateral de memos | desactivada | activada |
| Casos | desactivados | activados, con detección automática |
| Búsqueda y reclamo por anotador | desactivado | disponible (search.annotator_claim: true) |
| Tecla de codificación in vivo | i | activa en cualquier esquema de span respaldado por libro de códigos |
Nada de esto queda fijado. El modo QDA solo cambia el punto de partida; cada valor por defecto puede sobrescribirse. La única excepción es una barrera de seguridad: si conectas un backend de crowdsourcing como Prolific o Mechanical Turk, Potato bloquea por fuerza el libro de códigos en fixed, para que los anotadores remunerados no puedan rehacer el esquema compartido a tus espaldas.
Las piezas
Un libro de códigos vivo
En la codificación de corte teoría fundamentada, el libro de códigos no es algo que redactes de antemano. Crece a medida que lees. Adviertes una idea recurrente, le pones nombre y, una semana después, te das cuenta de que dos de tus códigos son en realidad el mismo y los fusionas.
Un esquema de span pasa a formar parte del libro de códigos cuando lo marcas:
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Esas labels son un conjunto de partida, no una jaula. En el modo de libro de códigos open añades, renombras, recoloreas, mueves y eliminas códigos mientras trabajas. El modo extensible permite a los codificadores añadir códigos, pero no eliminar los compartidos; fixed es el clásico bloqueado, para cuando ya has fijado un esquema.
Codificación in vivo
La codificación in vivo toma las propias palabras del participante como código. Alguien dice «es que no conseguía que me devolvieran la llamada» y «que me devolvieran la llamada» se convierte en el código, literalmente.
Selecciona un pasaje en un esquema de span respaldado por libro de códigos y pulsa la tecla in vivo (codebook_invivo_key, por defecto i). Potato acuña un código directamente a partir del texto resaltado. A medida que haces esto a lo largo de un corpus, la fragmentación es el enemigo: acabas con «sin devolución de llamada», «no conseguía que me devolvieran la llamada» y «nunca devolvieron la llamada» como tres códigos para una sola idea. El compositor de códigos contrarresta esto mostrando códigos casi duplicados mientras escribes, para que reutilices uno existente en lugar de generar otro.
Memos
Codificar sin notas hace perder el razonamiento que hay detrás de los códigos. Los memos son notas analíticas adjuntas a una instancia o a una selección de texto concreta. Puedes mantenerlos privados o compartirlos con el equipo. Son el lugar donde vive el «por qué codifiqué esto así», y se exportan junto a las citas para que tu rastro de auditoría sobreviva al proyecto.
Casos
Un caso agrupa extractos en una unidad de análisis: un participante, un documento, una visita de campo. Una vez agrupados los extractos, los atributos de nivel de caso se elevan para que puedas tabular los códigos frente a las variables de los participantes. Si cada entrevista lleva un campo condition, la tabla cruzada de administración puede mostrar cómo se distribuye un código entre las condiciones.
cases:
enabled: true
key: participant_id
attributes: [condition]Búsqueda
Un corpus solo es navegable si puedes saltar a cualquier mención de una palabra. El modo QDA incluye búsqueda de texto completo FTS5 sobre todo el conjunto de datos. Con annotator_claim: true, un codificador puede llevar cualquier coincidencia de la búsqueda directamente a su propia cola, que es como un único analista recorre un corpus por temas en lugar de leerlo estrictamente de principio a fin.
search:
enabled: true
annotator_claim: trueCómo encaja todo
Por debajo, el libro de códigos, los memos, los casos y la búsqueda leen y escriben en la misma base de datos del proyecto, así que un código acuñado en un sitio es inmediatamente buscable y exportable en todos los demás.
 Cómo el modo QDA compone sus piezas sobre un almacén compartido
Cómo el modo QDA compone sus piezas sobre un almacén compartido
Una configuración completa
Aquí tienes un estudio pequeño pero completo. Los bloques cases, search y de memos son opcionales (el modo QDA ya activa casos y memos), así que solo los escribes para ajustar un valor por defecto como la clave del caso.
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Ejecútala desde la raíz del repositorio una vez instalada la 2.6:
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000Recuperar tu codificación
Dos exportadores convierten los datos codificados en los entregables que necesita un artículo cualitativo:
codebookda una fila por código, con su jerarquía, descripción, color y número de usos.quotation_reportda una fila por tramo codificado: la cita, sus desplazamientos de caracteres, la instancia de origen y el codificador. Añadeinclude_memos=truepara incorporar tus memos.
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csvSi más de una persona codifica el mismo material, querrás una cifra de fiabilidad. Potato informa de los kappa de Cohen y de Fleiss sobre los códigos, algo que llegó en la versión 2.5 junto con estos exportadores.
Dónde encaja esto
El modo QDA no intenta superar a NVivo en funciones en todos los ejes. Lo que ofrece es un compromiso distinto: gratuito, de código abierto, basado en web y colaborativo, alojado en la misma herramienta que tu anotación para aprendizaje automático y tu evaluación de agentes. Si tu laboratorio ya usa Potato para etiquetar, la codificación cualitativa está ahora a un bloque de configuración de distancia, y no a la de un software de escritorio con licencia aparte.
El modo QDA llega en Potato 2.6. La documentación completa cubre todas las opciones, y la guía de acuerdo entre anotadores explica las métricas de fiabilidad.